Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
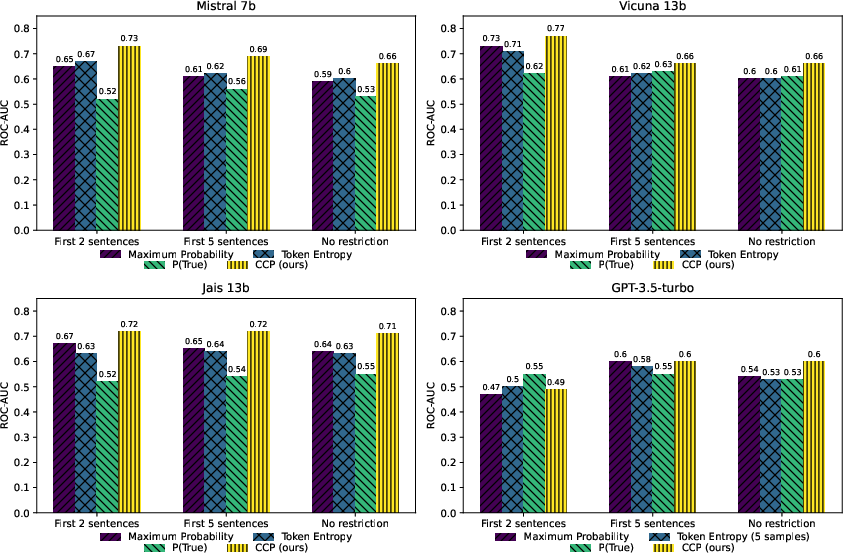
Abstract: LLMs are notorious for hallucinating, i.e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factually correct, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel fact-checking and hallucination detection pipeline based on token-level uncertainty quantification. Uncertainty scores leverage information encapsulated in the output of a neural network or its layers to detect unreliable predictions, and we show that they can be used to fact-check the atomic claims in the LLM output. Moreover, we present a novel token-level uncertainty quantification method that removes the impact of uncertainty about what claim to generate on the current step and what surface form to use. Our method Claim Conditioned Probability (CCP) measures only the uncertainty of a particular claim value expressed by the model. Experiments on the task of biography generation demonstrate strong improvements for CCP compared to the baselines for seven LLMs and four languages. Human evaluation reveals that the fact-checking pipeline based on uncertainty quantification is competitive with a fact-checking tool that leverages external knowledge.
- A multitask, multilingual, multimodal evaluation of ChatGPT on reasoning, hallucination, and interactivity. In Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 675–718, Nusa Dua, Bali. Association for Computational Linguistics.
- Steven Bird and Edward Loper. 2004. NLTK: The natural language toolkit. In Proceedings of the ACL Interactive Poster and Demonstration Sessions, pages 214–217.
- Factool: Factuality detection in generative ai–a tool augmented framework for multi-task and multi-domain scenarios. arXiv preprint arXiv:2307.13528.
- Detecting and mitigating hallucinations in machine translation: Model internal workings alone do well, sentence similarity Even better. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 36–50, Toronto, Canada. Association for Computational Linguistics.
- LM-polygraph: Uncertainty estimation for language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 446–461.
- Unsupervised quality estimation for neural machine translation. Transactions of the Association for Computational Linguistics, 8:539–555.
- Yarin Gal et al. 2016. Uncertainty in deep learning. Ph.D. thesis, University of Cambridge.
- A survey on automated fact-checking. Transactions of the Association for Computational Linguistics, 10:178–206.
- Deberta: decoding-enhanced bert with disentangled attention. In 9th International Conference on Learning Representations, ICLR.
- Mistral 7b. CoRR, abs/2310.06825.
- Language models (mostly) know what they know. CoRR, abs/2207.05221.
- Adam Tauman Kalai and Santosh S Vempala. 2023. Calibrated language models must hallucinate. arXiv preprint arXiv:2311.14648.
- Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In The Eleventh International Conference on Learning Representations.
- Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Simple and scalable predictive uncertainty estimation using deep ensembles. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NeurIPS 2017, page 6405–6416, Red Hook, NY, USA. Curran Associates Inc.
- A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc.
- Generating with confidence: Uncertainty quantification for black-box large language models. arXiv preprint arXiv:2305.19187.
- Andrey Malinin and Mark Gales. 2020. Uncertainty estimation in autoregressive structured prediction. In International Conference on Learning Representations.
- Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. arXiv preprint arXiv:2303.08896.
- FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100.
- The clef-2021 checkthat! lab on detecting check-worthy claims, previously fact-checked claims, and fake news. In Advances in Information Retrieval: 43rd European Conference on IR Research, ECIR 2021, Virtual Event, March 28–April 1, 2021, Proceedings, Part II 43, pages 639–649. Springer.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Fact-checking complex claims with program-guided reasoning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6981–7004.
- Out-of-distribution detection and selective generation for conditional language models. In The Eleventh International Conference on Learning Representations.
- Jais and jais-chat: Arabic-centric foundation and instruction-tuned open generative large language models. CoRR, abs/2308.16149.
- Evaluating large language models on controlled generation tasks. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3155–3168, Singapore. Association for Computational Linguistics.
- Is chatgpt good at search? investigating large language models as re-ranking agent. ArXiv, abs/2304.09542.
- Junya Takayama and Yuki Arase. 2019. Relevant and informative response generation using pointwise mutual information. In Proceedings of the First Workshop on NLP for Conversational AI, pages 133–138. Association for Computational Linguistics.
- Large language models in medicine. Nature medicine, 29(8):1930–1940.
- Mutual information alleviates hallucinations in abstractive summarization. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5956–5965. Association for Computational Linguistics.
- A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation. arXiv preprint arXiv:2307.03987.
- Fact or fiction: Verifying scientific claims. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7534–7550.
- Yi. 2023. A series of large language models trained from scratch by developers at 01-ai. https://github.com/01-ai/Yi.
- Judging llm-as-a-judge with mt-bench and chatbot arena. CoRR, abs/2306.05685.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.