- The paper presents a supervised learning framework employing four token probability features to effectively detect hallucinations in LLM outputs.
- It utilizes two classifiers—Logistic Regression and a simple Neural Network—to benchmark detection performance on datasets like HaluEval and HELM.
- The approach offers practical improvements for high-stakes applications and highlights future research directions including unsupervised methods and expanded feature sets.
Detecting Hallucinations in LLM Generation: A Token Probability Approach
Introduction
The paper "Detecting Hallucinations in LLM Generation: A Token Probability Approach" addresses a critical issue in natural language processing—the propensity of LLMs to generate hallucinated content. Hallucinations refer to outputs that appear coherent but are misleading or fictitious, posing risks especially in applications that rely heavily on factual consistency. The paper proposes a novel approach using supervised learning with simple classifiers, based on numerical features derived from token probabilities. This method promises efficiency and performance improvements over existing techniques, which often rely on complex setups.
Methodology
The paper introduces a methodology utilizing two classifiers—a Logistic Regression (LR) and a Simple Neural Network (SNN)—to detect hallucinations in LLM-generated text. This is achieved by leveraging four numerical features derived from token probability distributions supplied by LLM evaluators, which may differ from the original LLM generator responsible for the text.
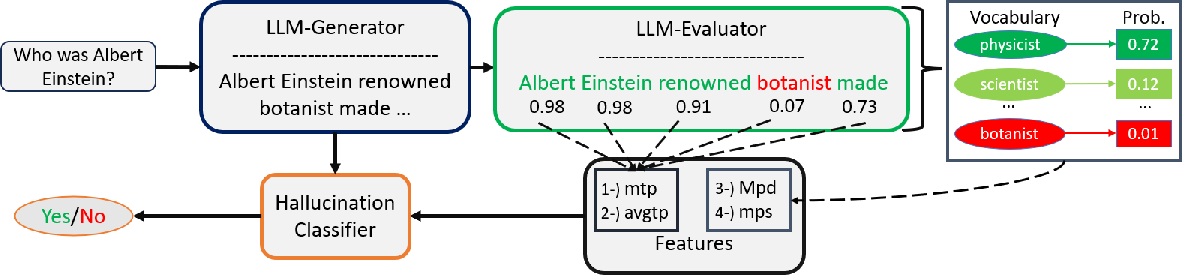
Figure 1: General Pipeline of the Proposed Methodology.
The four primary features used in the detection approach include:
- Minimum Token Probability (mtp): This captures the lowest probability assigned to any token by the LLM evaluator.
- Average Token Probability (avgtp): This measures the mean probability of tokens across the generated text.
- Maximum LLM Evaluator Probability Deviation (Mpd): This captures the greatest difference between the highest probability token and the generated token by the LLM evaluator.
- Minimum LLM Evaluator Probability Spread (mps): This examines the spread between the token with the highest and lowest probability assigned by the LLM evaluator.
These features are inspired by prior research indicating a correlation between low token probabilities and hallucination likelihood in LLM-generated content.
Experimental Setup and Results
The approach was evaluated using various datasets, including HaluEval, HELM, and True-False benchmarks, with several evaluative LLMs like GPT-2, BART, OPT, and more.
HaluEval Benchmark
The experimental results showed that the proposed method, using classifiers trained on just 10% of the data, surpassed existing state-of-the-art methods in specific tasks like Summarization and Question Answering. Notably, the use of different LLM models as evaluators—often dissimilar to the original generator—proved beneficial, reinforcing the importance of diverse model selection based on architecture and training data.
HELM Benchmark
In the HELM benchmark, although the proposed method did not outperform the unsupervised MIND approach, it yielded competitive results compared to other state-of-the-art supervised approaches like SAPLMA. The use of alternative LLM evaluators often matched or exceeded the performance of using the same LLM as the generator.
True-False Dataset
The method exhibited limitations when applied to the True-False dataset, highlighting the need for augmenting feature sets beyond the proposed four numerical features to better capture the nuances of this particular data corpus.
Implications and Future Work
The findings suggest significant potential for enhancing the reliability of LLM outputs through efficient hallucination detection mechanisms. By improving the credibility of LLM-generated content, this approach mitigates risks in high-stakes applications like medical, legal, and educational domains. Future research may focus on integrating unsupervised methods alongside probabilistic criteria to further refine detection accuracy and expand applicability across diverse datasets.
Beyond the current scope, potential enhancements include exploring advanced ensemble techniques and diversifying feature sets to encompass dynamic hidden states or linguistic embeddings, aiming to improve detection accuracy further and facilitate interpretability.
Conclusion
The study presents a supervised learning framework emphasizing numerical token probabilities for hallucination detection in LLM-generated text. By demonstrating competitive results across multiple benchmarks with minimal features and computational overhead, the approach offers a promising direction for practical implementation and continuous improvement in natural language processing tasks. Continued investigation into expanding feature bases and integrating multidimensional evaluators holds promise for refining and optimizing hallucination detection methodologies.