- The paper introduces FRANQ, a framework that decouples factual correctness and faithfulness, enabling precise detection of hallucinated claims in RAG outputs.
- It employs a probabilistic model using AlignScore, MaxNLI, and parametric methods with condition-calibrated isotonic regression for enhanced uncertainty quantification.
- Experimental benchmarks demonstrate that FRANQ outperforms traditional methods in both long-form and short-form QA by effectively reducing false claim acceptance.
Faithfulness-Aware Uncertainty Quantification for Fact-Checking RAG Output
Introduction
The paper introduces FRANQ, a faithfulness-aware uncertainty quantification (UQ) framework for fact-checking the output of retrieval-augmented generation (RAG) systems. Unlike traditional approaches that conflate factuality and faithfulness (i.e., grounding in retrieved evidence), FRANQ decomposes hallucination detection into two core axes: the factual correctness of atomic claims and their fidelity to the provided context. This rigorous separation enables more precise identification of factual errors within RAG outputs, circumventing failure cases where factually accurate yet ungrounded claims are mistakenly flagged as hallucinations.
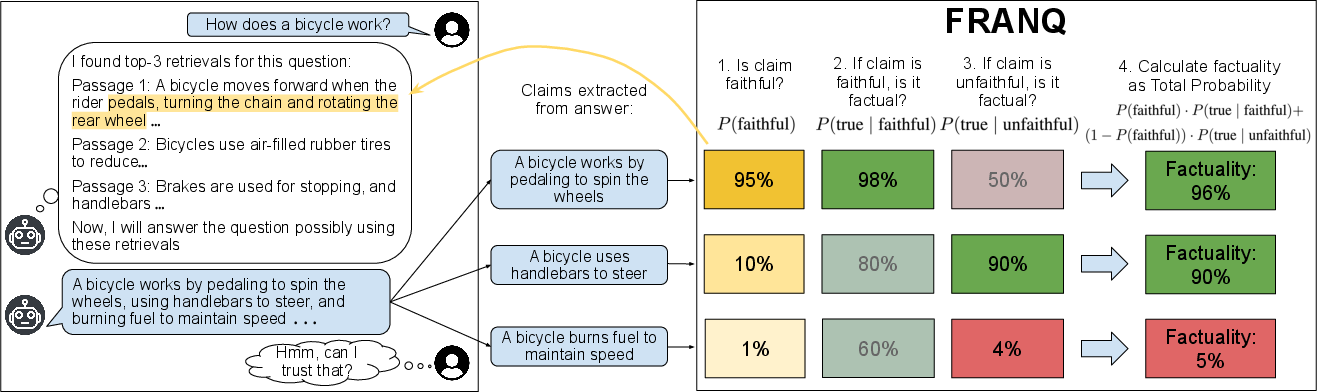
Figure 1: Schematic overview of the FRANQ pipeline including claim decomposition and joint faithfulness/factuality assessment.
Methodology
FRANQ Decomposition and Probabilistic Model
Given a user query x, the RAG system retrieves documents r={r1,...,rk} and generates a response y. FRANQ decomposes y into atomic claims c1,...,cl. For each claim c, FRANQ models the probability of factuality:
P(c is true)=P(c is faithful to r)⋅P(c is true∣faithful)+(1−P(c is faithful to r))⋅P(c is true∣unfaithful)
Faithfulness P(c is faithful to r) is estimated via AlignScore [zha2023alignscoreevaluatingfactualconsistency]. For claims deemed faithful, factuality is calculated using MaxNLI—a maximum entailment score from a pre-trained NLI model [he2021debertav3]. For unfaithful claims, FRANQ applies a parametric knowledge UQ method (i.e., likelihood of the claim according to the LLM without retrieval context [mallen2022not]). Outputs are calibrated via condition-specific isotonic regression.
Component Selection
- Faithfulness Assessment: AlignScore, operating at the claim and context level, directly measures semantic entailedness.
- Factuality Given Faithful: MaxNLI extracts the maximal entailment confidence.
- Factuality Given Unfaithful: Parametric knowledge UQ computes token-level likelihood of the claim, exploiting the LLM’s internal factual priors.
Short-form QA settings required modular UQ methods: Semantic Entropy for UQfaith and the Sum of Eigenvalues method for UQunfaith, reflecting superior performance in sequence-level settings over token-level alternatives.
Calibration Strategy
Component scores are aligned to probabilistic intervals using isotonic regression with condition-specific splits (faithful vs unfaithful claims), minimizing calibration error and boosting downstream rejection metrics.
Experimental Setup and Datasets
Dataset Design
Recognizing the limitations of existing RAG hallucination datasets, the authors construct a bespoke long-form QA benchmark annotated for both factuality and faithfulness. Claims are extracted using GPT-4o and matched to token spans. Manual annotation supplements automatic labeling for low confidence or contradictory cases. Short-form RAG performance is evaluated over TriviaQA, SimpleQA, PopQA, and Natural Questions, using 200 training and 1,000 test samples per set.
Baselines
Comprehensive UQ baselines are considered, including information-based and sample-diversity metrics (CCP, Perplexity, TokenSAR, Semantic Entropy, etc.), retriever-specific methods, and supervised pipelines (XGBoost) using both aggregate and FRANQ-specific features.
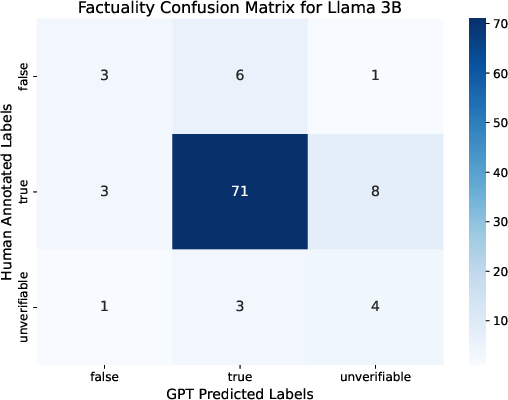
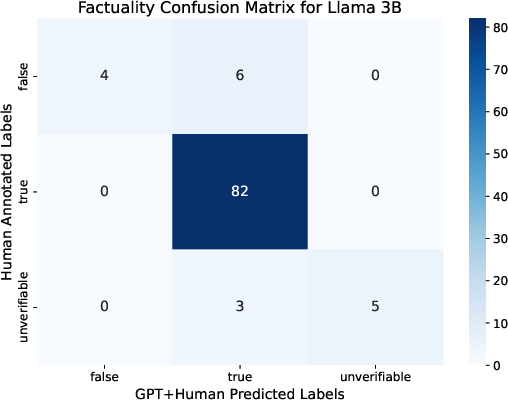
Figure 2: Class balance in factuality annotations before manual enhancement, illustrating the discrepancy between automatic and human annotation.
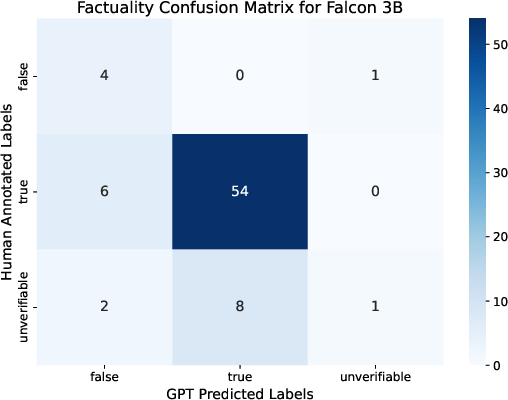
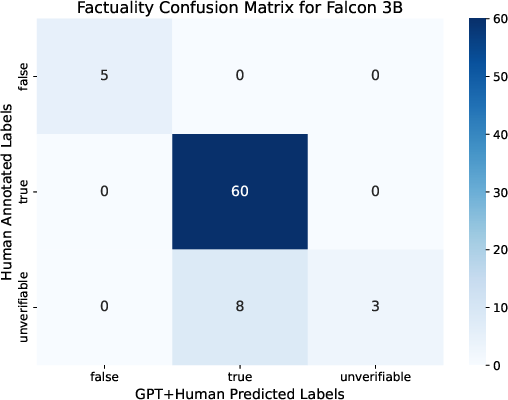
Figure 3: Pre-enhancement balance for faithfulness annotations, verifying automatic assignment quality.
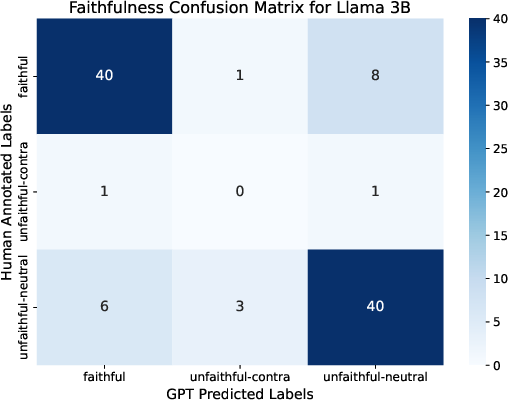
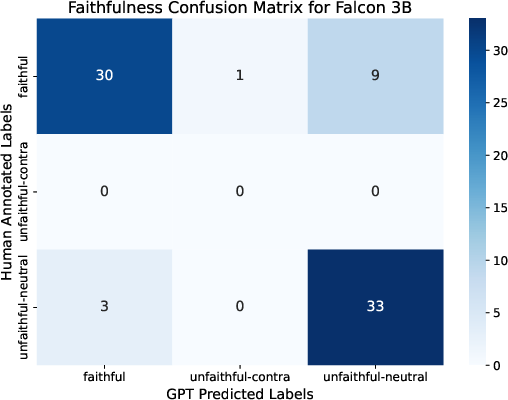
Figure 4: Distribution of Llama 3B faithfulness classes, highlighting the predominance of unfaithful claims in RAG output.
Results
FRANQ with condition-specific calibration achieves the highest PR-AUC and PRR scores across both Llama 3B and Falcon 3B (Table 1). Notably, the use of continuous AlignScore signals and condition-dependent calibration contribute to superior rejection of false claims. Lower PRR is observed for baseline token probability and entropy methods, reinforcing the inadequacy of applying vanilla UQ to the joint prompt.
Across multiple datasets and two LLM backbones, condition-calibrated FRANQ consistently yielded lowest mean ranks and highest mean metric values (ROC-AUC, PR-AUC, PRR) compared to both unsupervised and XGBoost baselines (Table 2). Performance retained robustness over varying training sizes and in cross-model evaluations.
Ablations
Component analysis confirms that Parametric Knowledge is critical for unfaithful claims in long-form QA, whereas MaxNLI and Semantic Entropy provide stable results in faithful scenarios. Calibration error is lowest for condition-calibrated FRANQ variants, outperforming all black-box metrics and XGBoost-based systems.
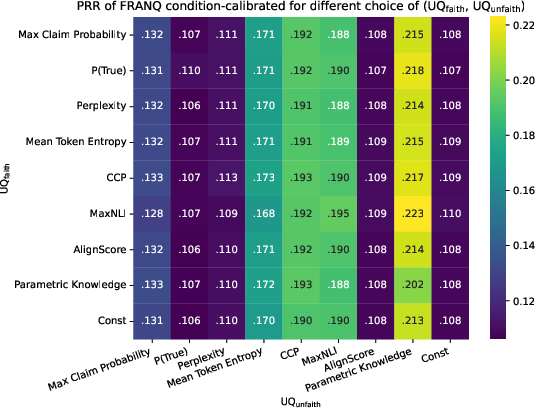
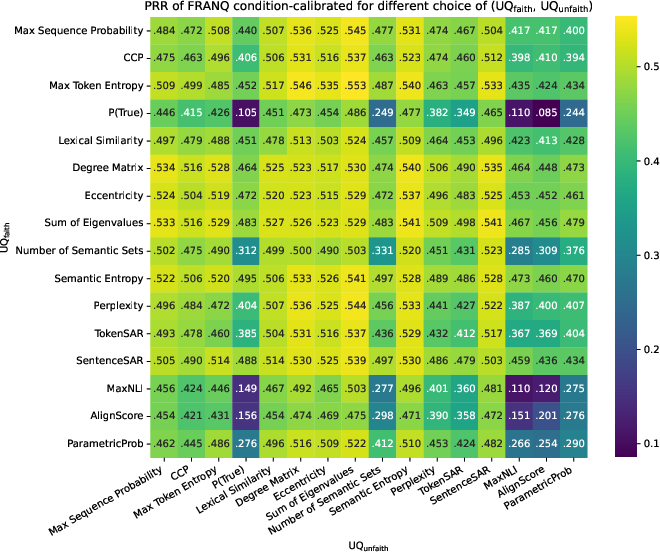
Figure 5: PRR scores on the long-form QA dataset, demonstrating FRANQ’s improvement over baseline UQ strategies.
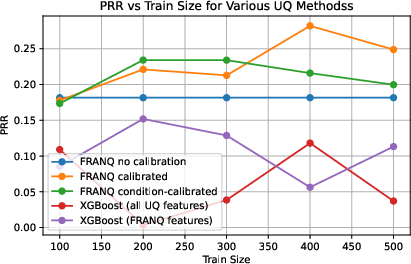
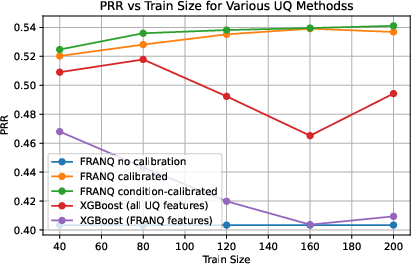
Figure 6: Learning curve for FRANQ on long-form QA (Llama 3B), showing saturation at moderate training set sizes.
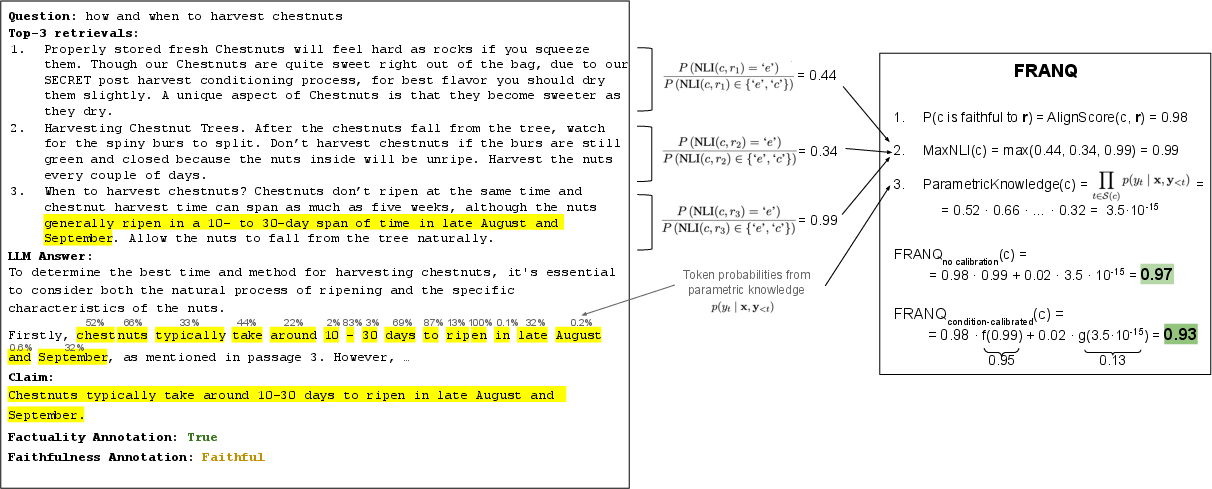

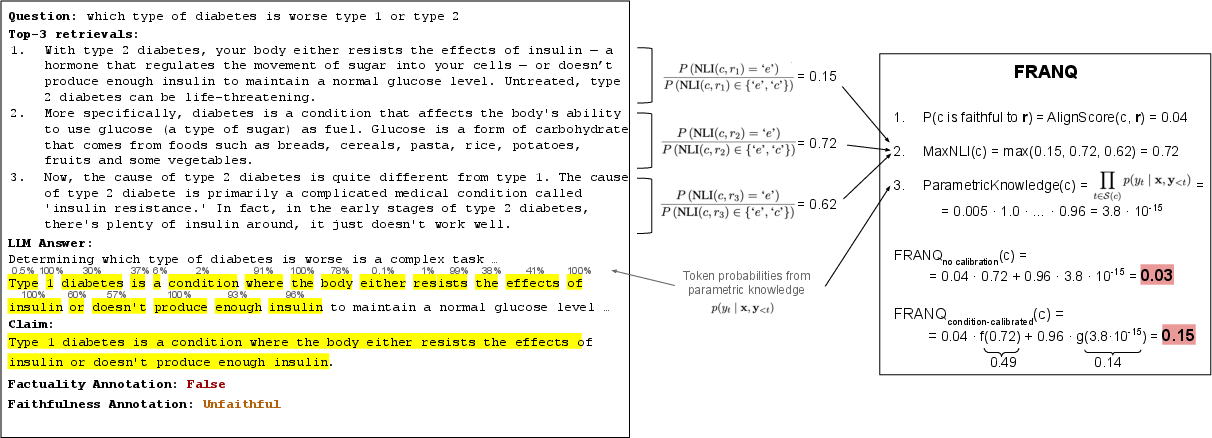
Figure 7: Case study for a faithful and factually correct claim, where FRANQ assigns maximally calibrated confidence via MaxNLI.
Implementation Guidelines
- Atomic Claim Extraction: Employ sequence or token-level decomposition via advanced prompt engineering (see detailed GPT-4o protocols in the appendix).
- Faithfulness Estimation: Use AlignScore or equivalent entailment metrics. Thresholding degrades performance; continuous signals should be preferred.
- Factuality Estimation: Integrate NLI models (DeBERTaV3 or comparable) for faithful claims; fallback to LLM token likelihood or diversity-based metrics (Semantic Entropy, Eigenvalue Sum) for unfaithful cases.
- Calibration: Fit condition-specific isotonic regression functions per claim category using training splits constructed from annotated data. For production, recalibrate periodically as claim distribution drifts.
- Scalability: The pipeline is GPU-efficient (V100-class), but calibration requires periodic retraining on representative annotated sets.
- Integration/Deployment: FRANQ modules can be composed post-generation for token-level (long-form) or sequence-level (short-form) inference, and downstream filtering can use calibrated confidence scores for abstention, rejection, or post-edit prioritization.
Implications and Future Directions
The rigorous decoupling of factuality and faithfulness establishes a benchmark for reliable hallucination detection in RAG systems. Practically, FRANQ enables fine-grained sparsing/filtering of LLM outputs, which is critical for high-stakes applications in scientific QA, medical documentation, or legal summarization. The condition-calibrated variant yields well-calibrated confidence scores, which allow for downstream rejection and abstention pipelines.
Theoretically, the framework defines compositional uncertainty quantification for hybrid parametric/non-parametric scenarios—a paradigm extensible to retrieval uncertainty modeling, evidence weighting under contradictory or noisy retrieved contexts, and even dynamic retrieval pruning. Future work should incorporate retrieval-side UQ, active claim re-ranking, and integration of domain-adaptive NLI or grounding models.
Conclusion
FRANQ advances hallucination detection in RAG by formalizing the distinction between factuality and faithfulness at the atomic claim level and leveraging compositional UQ with probabilistic calibration. Empirical benchmarks confirm FRANQ’s superiority across models and datasets, especially for false claim rejection. Its modular, well-calibrated architecture enables direct adoption in production RAG pipelines and sets a new standard for factuality assessment under retrieval augmentation.