Compositional Chain-of-Thought Prompting for Large Multimodal Models
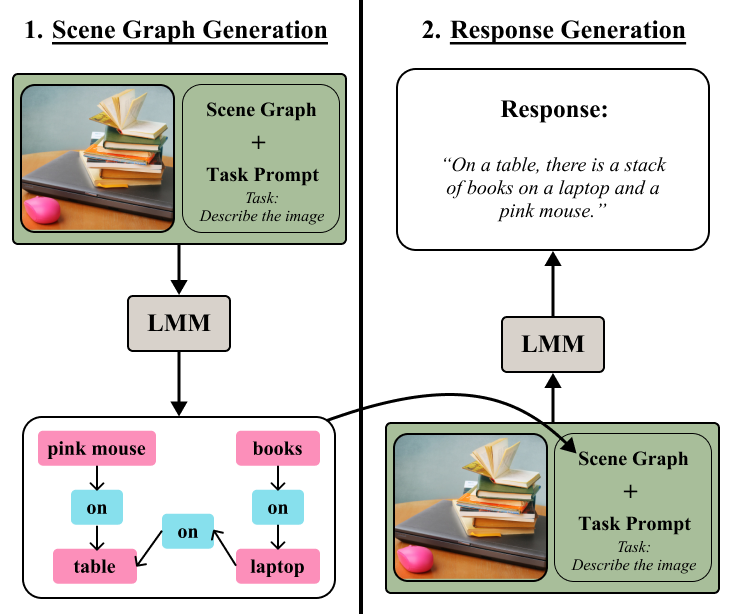
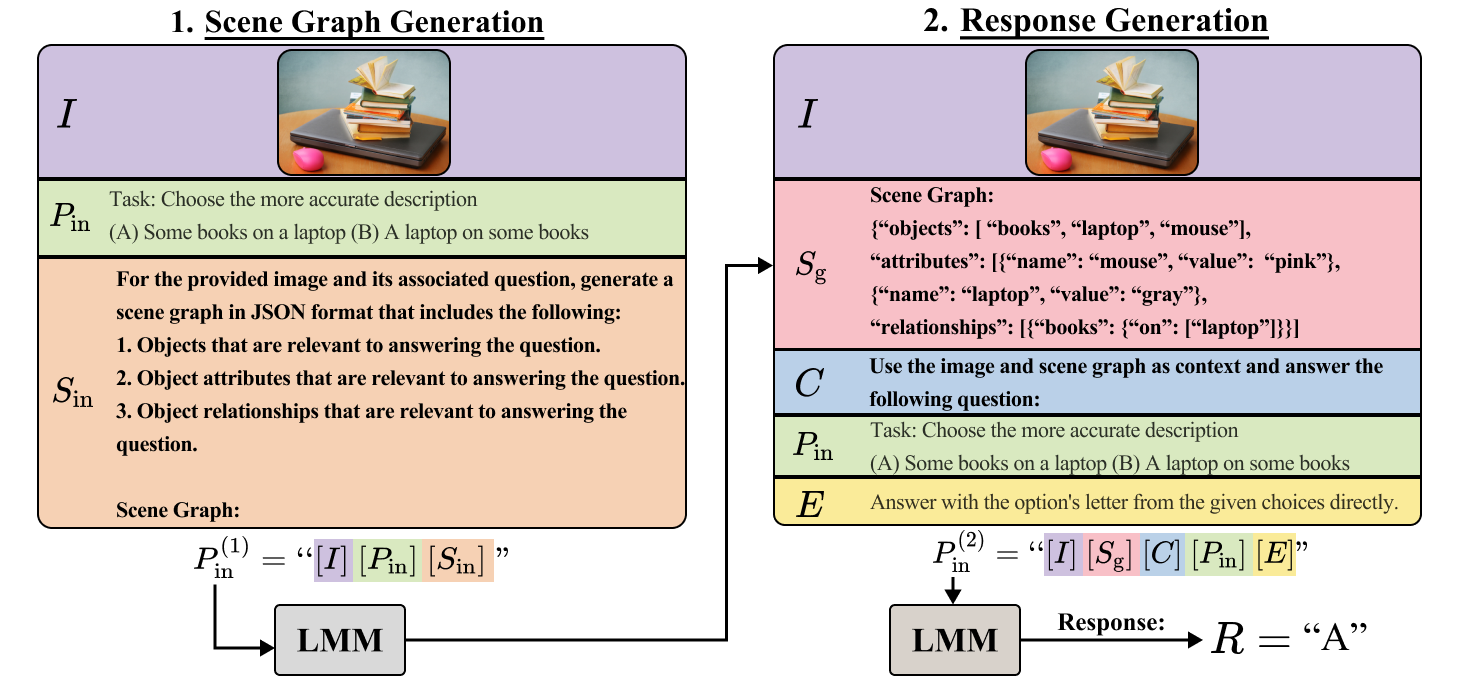
Abstract: The combination of strong visual backbones and LLM reasoning has led to Large Multimodal Models (LMMs) becoming the current standard for a wide range of vision and language (VL) tasks. However, recent research has shown that even the most advanced LMMs still struggle to capture aspects of compositional visual reasoning, such as attributes and relationships between objects. One solution is to utilize scene graphs (SGs)--a formalization of objects and their relations and attributes that has been extensively used as a bridge between the visual and textual domains. Yet, scene graph data requires scene graph annotations, which are expensive to collect and thus not easily scalable. Moreover, finetuning an LMM based on SG data can lead to catastrophic forgetting of the pretraining objective. To overcome this, inspired by chain-of-thought methods, we propose Compositional Chain-of-Thought (CCoT), a novel zero-shot Chain-of-Thought prompting method that utilizes SG representations in order to extract compositional knowledge from an LMM. Specifically, we first generate an SG using the LMM, and then use that SG in the prompt to produce a response. Through extensive experiments, we find that the proposed CCoT approach not only improves LMM performance on several vision and language VL compositional benchmarks but also improves the performance of several popular LMMs on general multimodal benchmarks, without the need for fine-tuning or annotated ground-truth SGs. Code: https://github.com/chancharikmitra/CCoT
- Flamingo: a visual language model for few-shot learning. ArXiv, abs/2204.14198, 2022.
- FETA: Towards specializing foundational models for expert task applications. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022.
- Deep compositional question answering with neural module networks. ArXiv, abs/1511.02799, 2015a.
- Neural module networks. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 39–48, 2015b.
- Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015.
- Bringing image scene structure to video via frame-clip consistency of object tokens. In Thirty-Sixth Conference on Neural Information Processing Systems, 2022.
- Qwen-vl: A frontier large vision-language model with versatile abilities. ArXiv, abs/2308.12966, 2023.
- Compositional video synthesis with action graphs. In ICML, 2021.
- Object level visual reasoning in videos. In ECCV, pages 105–121, 2018.
- Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261, 2018.
- Graph of thoughts: Solving elaborate problems with large language models. ArXiv, abs/2308.09687, 2023.
- Breaking common sense: Whoops! a vision-and-language benchmark of synthetic and compositional images. ArXiv, abs/2303.07274, 2023.
- Language models are few-shot learners. ArXiv, abs/2005.14165, 2020.
- Uniter: Universal image-text representation learning. In ECCV, 2020.
- Palm: Scaling language modeling with pathways. J. Mach. Learn. Res., 24:240:1–240:113, 2022.
- Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023.
- A survey on in-context learning. 2022.
- Teaching structured vision & language concepts to vision & language models. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2657–2668, 2022.
- Palm-e: An embodied multimodal language model. In International Conference on Machine Learning, 2023.
- Cyclip: Cyclic contrastive language-image pretraining. arXiv preprint arXiv:2205.14459, 2022.
- Multimodal-gpt: A vision and language model for dialogue with humans. ArXiv, abs/2305.04790, 2023.
- Visual programming: Compositional visual reasoning without training. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14953–14962, 2022.
- Momentum contrast for unsupervised visual representation learning. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9726–9735, 2019.
- Mapping images to scene graphs with permutation-invariant structured prediction. In Advances in Neural Information Processing Systems (NIPS), 2018.
- Spatio-temporal action graph networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 0–0, 2019.
- Learning canonical representations for scene graph to image generation. In European Conference on Computer Vision, 2020.
- Object-region video transformers. In Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- Incorporating structured representations into pretrained vision \& language models using scene graphs. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023.
- Gqa: A new dataset for real-world visual reasoning and compositional question answering. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6693–6702, 2019.
- Learning object detection from captions via textual scene attributes. ArXiv, abs/2009.14558, 2020.
- Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning, 2021.
- Image retrieval using scene graphs. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3668–3678, 2015.
- Inferring and executing programs for visual reasoning. 2017 IEEE International Conference on Computer Vision (ICCV), pages 3008–3017, 2017.
- Image generation from scene graphs. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1219–1228, 2018.
- Large language models are zero-shot reasoners. ArXiv, abs/2205.11916, 2022a.
- Large language models are zero-shot reasoners. ArXiv, abs/2205.11916, 2022b.
- Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 123(1):32–73, 2017.
- Boosting logical reasoning in large language models through a new framework: The graph of thought. ArXiv, abs/2308.08614, 2023.
- Seed-bench: Benchmarking multimodal llms with generative comprehension. ArXiv, abs/2307.16125, 2023a.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. arXiv preprint arXiv:2201.12086, 2022.
- BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, 2023b.
- Oscar: Object-semantics aligned pre-training for vision-language tasks. ECCV 2020, 2020.
- Microsoft coco: Common objects in context. In ECCV, 2014.
- Improved baselines with visual instruction tuning, 2023a.
- Visual instruction tuning. In NeurIPS, 2023b.
- Mmbench: Is your multi-modal model an all-around player? ArXiv, abs/2307.06281, 2023c.
- Learn to explain: Multimodal reasoning via thought chains for science question answering. ArXiv, abs/2209.09513, 2022.
- Chameleon: Plug-and-play compositional reasoning with large language models. ArXiv, abs/2304.09842, 2023.
- Fairness-guided few-shot prompting for large language models. ArXiv, abs/2303.13217, 2023.
- Crepe: Can vision-language foundation models reason compositionally? ArXiv, abs/2212.07796, 2022.
- Ok-vqa: A visual question answering benchmark requiring external knowledge. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3190–3199, 2019.
- Something-else: Compositional action recognition with spatial-temporal interaction networks. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020.
- Rethinking the role of demonstrations: What makes in-context learning work? ArXiv, abs/2202.12837, 2022.
- OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
- Toolllm: Facilitating large language models to master 16000+ real-world apis. ArXiv, abs/2307.16789, 2023.
- Differentiable scene graphs. In WACV, 2020.
- Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21:140:1–140:67, 2019.
- Scienceqa: a novel resource for question answering on scholarly articles. International Journal on Digital Libraries, 23:289 – 301, 2022.
- Toolformer: Language models can teach themselves to use tools. ArXiv, abs/2302.04761, 2023.
- Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. ArXiv, abs/2303.17580, 2023.
- Modular visual question answering via code generation. ArXiv, abs/2306.05392, 2023.
- Vipergpt: Visual inference via python execution for reasoning. ArXiv, abs/2303.08128, 2023.
- Lxmert: Learning cross-modality encoder representations from transformers. pages 5099–5110. Association for Computational Linguistics, 2019.
- Ul2: Unifying language learning paradigms. In International Conference on Learning Representations, 2022.
- Winoground: Probing vision and language models for visio-linguistic compositionality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5238–5248, 2022.
- Better zero-shot reasoning with self-adaptive prompting. In Annual Meeting of the Association for Computational Linguistics, 2023.
- T-sciq: Teaching multimodal chain-of-thought reasoning via large language model signals for science question answering. ArXiv, abs/2305.03453, 2023a.
- Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In Annual Meeting of the Association for Computational Linguistics, 2023b.
- Videos as space-time region graphs. In ECCV, 2018.
- Self-consistency improves chain of thought reasoning in language models. ArXiv, abs/2203.11171, 2022a.
- Language models with image descriptors are strong few-shot video-language learners. ArXiv, abs/2205.10747, 2022b.
- Finetuned language models are zero-shot learners. ArXiv, abs/2109.01652, 2021.
- Chain of thought prompting elicits reasoning in large language models. ArXiv, abs/2201.11903, 2022.
- Visual chatgpt: Talking, drawing and editing with visual foundation models. ArXiv, abs/2303.04671, 2023.
- Expertprompting: Instructing large language models to be distinguished experts. ArXiv, abs/2305.14688, 2023.
- Scene Graph Generation by Iterative Message Passing. In CVPR, pages 3097–3106, 2017.
- Panoptic scene graph generation. In European Conference on Computer Vision, 2022.
- Tree of thoughts: Deliberate problem solving with large language models. ArXiv, abs/2305.10601, 2023a.
- Beyond chain-of-thought, effective graph-of-thought reasoning in large language models. ArXiv, abs/2305.16582, 2023b.
- mplug-owl: Modularization empowers large language models with multimodality. ArXiv, abs/2304.14178, 2023a.
- mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration. ArXiv, abs/2311.04257, 2023b.
- Ernie-vil: Knowledge enhanced vision-language representations through scene graphs. Proceedings of the AAAI Conference on Artificial Intelligence, 35(4):3208–3216, 2021.
- When and why vision-language models behave like bags-of-words, and what to do about it? In International Conference on Learning Representations, 2023.
- Automatic chain of thought prompting in large language models. ArXiv, abs/2210.03493, 2022.
- Multimodal chain-of-thought reasoning in language models. ArXiv, abs/2302.00923, 2023.
- Svit: Scaling up visual instruction tuning. ArXiv, abs/2307.04087, 2023.
- Vl-checklist: Evaluating pre-trained vision-language models with objects, attributes and relations. arXiv preprint arXiv:2207.00221, 2022.
- Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models. ArXiv, abs/2310.16436, 2023.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.