Virtual Fusion with Contrastive Learning for Single Sensor-based Activity Recognition
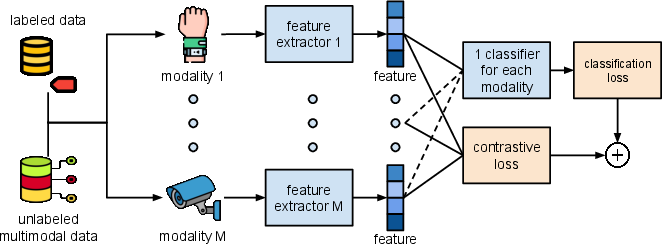
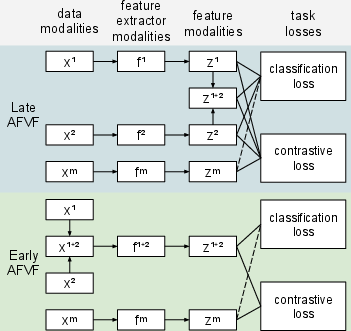
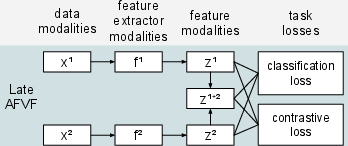
Abstract: Various types of sensors can be used for Human Activity Recognition (HAR), and each of them has different strengths and weaknesses. Sometimes a single sensor cannot fully observe the user's motions from its perspective, which causes wrong predictions. While sensor fusion provides more information for HAR, it comes with many inherent drawbacks like user privacy and acceptance, costly set-up, operation, and maintenance. To deal with this problem, we propose Virtual Fusion - a new method that takes advantage of unlabeled data from multiple time-synchronized sensors during training, but only needs one sensor for inference. Contrastive learning is adopted to exploit the correlation among sensors. Virtual Fusion gives significantly better accuracy than training with the same single sensor, and in some cases, it even surpasses actual fusion using multiple sensors at test time. We also extend this method to a more general version called Actual Fusion within Virtual Fusion (AFVF), which uses a subset of training sensors during inference. Our method achieves state-of-the-art accuracy and F1-score on UCI-HAR and PAMAP2 benchmark datasets. Implementation is available upon request.
- B. Kwolek and M. Kepski, “Fuzzy inference-based fall detection using kinect and body-worn accelerometer,” Applied Soft Computing, vol. 40, pp. 305–318, 3 2016.
- H. Zhang, M. Alrifaai, K. Zhou, and H. Hu, “A novel fuzzy logic algorithm for accurate fall detection of smart wristband,” Transactions of the Institute of Measurement and Control, vol. 42, pp. 786–794, 2 2020.
- A. Hakim, M. S. Huq, S. Shanta, and B. Ibrahim, “Smartphone based data mining for fall detection: Analysis and design,” Procedia Computer Science, vol. 105, pp. 46–51, 2017.
- S. Denkovski, S. S. Khan, B. Malamis, S. Y. Moon, B. Ye, and A. Mihailidis, “Multi visual modality fall detection dataset,” IEEE Access, vol. 10, pp. 106 422–106 435, 2022.
- Z. Wang, V. Ramamoorthy, U. Gal, and A. Guez, “Possible life saver: A review on human fall detection technology,” Robotics, vol. 9, p. 55, 7 2020.
- “Multi-sensor fusion for activity recognition—a survey,” Sensors, vol. 19, p. 3808, 9 2019.
- S. K. Yadav, K. Tiwari, H. M. Pandey, and S. A. Akbar, “A review of multimodal human activity recognition with special emphasis on classification, applications, challenges and future directions,” Knowledge-Based Systems, vol. 223, p. 106970, 7 2021.
- M. Webber and R. F. Rojas, “Human activity recognition with accelerometer and gyroscope: A data fusion approach,” IEEE Sensors Journal, vol. 21, pp. 16 979–16 989, 8 2021.
- M. M. Islam, S. Nooruddin, F. Karray, and G. Muhammad, “Multi-level feature fusion for multimodal human activity recognition in internet of healthcare things,” Information Fusion, vol. 94, pp. 17–31, 6 2023.
- S. Zhu, R. G. Guendel, A. Yarovoy, and F. Fioranelli, “Continuous human activity recognition with distributed radar sensor networks and cnn–rnn architectures,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–15, 2022.
- L. Cao, S. Liang, Z. Zhao, D. Wang, C. Fu, and K. Du, “Human activity recognition method based on fmcw radar sensor with multi-domain feature attention fusion network,” Sensors, vol. 23, p. 5100, 5 2023.
- C. Pham, L. Nguyen, A. Nguyen, N. Nguyen, and V.-T. Nguyen, “Combining skeleton and accelerometer data for human fine-grained activity recognition and abnormal behaviour detection with deep temporal convolutional networks,” Multimedia Tools and Applications, vol. 80, pp. 28 919–28 940, 8 2021.
- X. Feng, Y. Weng, W. Li, P. Chen, and H. Zheng, “Damun: A domain adaptive human activity recognition network based on multimodal feature fusion,” IEEE Sensors Journal, vol. 23, pp. 22 019–22 030, 2023.
- H.-N. Vu, T. Hoang, C. Tran, and C. Pham, “Sign language recognition with self-learning fusion model,” IEEE Sensors Journal, p. 1, 2023.
- R. A. Hamad, L. Yang, W. L. Woo, and B. Wei, “Convnet-based performers attention and supervised contrastive learning for activity recognition,” Applied Intelligence, vol. 53, pp. 8809–8825, 4 2023.
- X. Ouyang, X. Shuai, J. Zhou, I. W. Shi, Z. Xie, G. Xing, and J. Huang, “Cosmo: Contrastive fusion learning with small data for multimodal human activity recognition,” 2022.
- Y. Jain, C. I. Tang, C. Min, F. Kawsar, and A. Mathur, “Collossl: Collaborative self-supervised learning for human activity recognition,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 6, 2022.
- S. Deldari, H. Xue, A. Saeed, D. V. Smith, and F. D. Salim, “Cocoa: Cross modality contrastive learning for sensor data,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 6, pp. 1–28, 9 2022.
- I. Koo, Y. Park, M. Jeong, and C. Kim, “Contrastive accelerometer-gyroscope embedding model for human activity recognition,” IEEE Sensors Journal, vol. 23, 2023.
- R. Brinzea, B. Khaertdinov, and S. Asteriadis, “Contrastive learning with cross-modal knowledge mining for multimodal human activity recognition,” vol. 2022-July, 2022.
- Y. Tian, D. Krishnan, and P. Isola, “Contrastive multiview coding,” 6 2019.
- T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” 2 2020.
- T. Huynh, S. Kornblith, M. R. Walter, M. Maire, and M. Khademi, “Boosting contrastive self-supervised learning with false negative cancellation,” 2022.
- J. Wang, T. Zhu, L. L. Chen, H. Ning, and Y. Wan, “Negative selection by clustering for contrastive learning in human activity recognition,” IEEE Internet of Things Journal, vol. 10, pp. 10 833–10 844, 6 2023.
- J. Robinson, C. Y. Chuang, S. Sra, and S. Jegelka, “Contrastive learning with hard negative samples,” 2021.
- S. Hong. [Online]. Available: https://github.com/hsd1503/resnet1d
- T. H. Tran, T. L. Le, D. T. Pham, V. N. Hoang, V. M. Khong, Q. T. Tran, T. S. Nguyen, and C. Pham, “A multi-modal multi-view dataset for human fall analysis and preliminary investigation on modality,” vol. 2018-August, 2018.
- L. Martínez-Villaseñor, H. Ponce, J. Brieva, E. Moya-Albor, J. Núñez-Martínez, and C. Peñafort-Asturiano, “Up-fall detection dataset: A multimodal approach,” Sensors, vol. 19, p. 1988, 4 2019.
- Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y. Sheikh, “Openpose: Realtime multi-person 2d pose estimation using part affinity fields,” 12 2018.
- M. Saleh, M. Abbas, and R. B. L. Jeannes, “Fallalld: An open dataset of human falls and activities of daily living for classical and deep learning applications,” IEEE Sensors Journal, vol. 21, 2021.
- D. Anguita, A. Ghio, L. Oneto, X. Parra, and J. L. Reyes-Ortiz, “A public domain dataset for human activity recognition using smartphones,” 2013.
- A. Reiss and D. Stricker, “Introducing a new benchmarked dataset for activity monitoring.” IEEE, 6 2012, pp. 108–109.
- T. T. Um, F. M. Pfister, D. Pichler, S. Endo, M. Lang, S. Hirche, U. Fietzek, and D. Kulic, “Data augmentation of wearable sensor data for parkinson’s disease monitoring using convolutional neural networks,” vol. 2017-January, 2017.
- A. Ignatov, “Real-time human activity recognition from accelerometer data using convolutional neural networks,” Applied Soft Computing, vol. 62, pp. 915–922, 1 2018.
- Q. Teng, K. Wang, L. Zhang, and J. He, “The layer-wise training convolutional neural networks using local loss for sensor-based human activity recognition,” IEEE Sensors Journal, vol. 20, pp. 7265–7274, 7 2020.
- W. Gao, L. Zhang, Q. Teng, J. He, and H. Wu, “Danhar: Dual attention network for multimodal human activity recognition using wearable sensors,” Applied Soft Computing, vol. 111, p. 107728, 11 2021.
- D. Bhattacharya, D. Sharma, W. Kim, M. F. Ijaz, and P. K. Singh, “Ensem-har: An ensemble deep learning model for smartphone sensor-based human activity recognition for measurement of elderly health monitoring,” Biosensors, vol. 12, p. 393, 6 2022.
- A. Dahou, M. A. Al-qaness, M. A. Elaziz, and A. Helmi, “Human activity recognition in ioht applications using arithmetic optimization algorithm and deep learning,” Measurement, vol. 199, p. 111445, 8 2022.
- A. M. Helmi, M. A. Al-qaness, A. Dahou, and M. A. Elaziz, “Human activity recognition using marine predators algorithm with deep learning,” Future Generation Computer Systems, vol. 142, pp. 340–350, 5 2023.
- M. A. A. Al-qaness, A. Dahou, M. A. Elaziz, and A. M. Helmi, “Multi-resatt: Multilevel residual network with attention for human activity recognition using wearable sensors,” IEEE Transactions on Industrial Informatics, vol. 19, pp. 144–152, 1 2023.
- A. Sezavar, R. Atta, and M. Ghanbari, “Dcapsnet: Deep capsule network for human activity and gait recognition with smartphone sensors,” Pattern Recognition, vol. 147, p. 110054, 3 2024.
- Q. Xu, M. Wu, X. Li, K. Mao, and Z. Chen, “Contrastive distillation with regularized knowledge for deep model compression on sensor-based human activity recognition,” IEEE Transactions on Industrial Cyber-Physical Systems, vol. 1, pp. 217–226, 2023.
- D. Cheng, L. Zhang, C. Bu, H. Wu, and A. Song, “Learning hierarchical time series data augmentation invariances via contrastive supervision for human activity recognition,” Knowledge-Based Systems, vol. 276, p. 110789, 9 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.