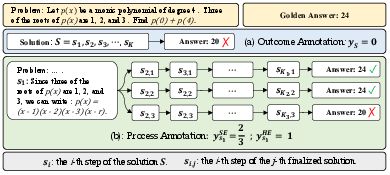
- The paper introduces a process-oriented reward model that evaluates each reasoning step to both verify and reinforce LLM outputs in mathematical tasks.
- It employs automatic process annotation inspired by Monte Carlo Tree Search to generate supervision labels without the need for costly human annotations.
- Results on benchmarks like GSM8K and MATH show significant accuracy improvements, demonstrating Math-Shepherd’s scalability and effectiveness across various LLM configurations.
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Introduction
"Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations" presents a novel method termed Math-Shepherd, designed to enhance the verification and training processes of LLMs in solving mathematical tasks. This approach introduces a process-oriented math reward model that eliminates the dependency on human annotations by utilizing automatically constructed process-wise supervision data. Math-Shepherd capitalizes on a step-by-step evaluation methodology that aims to improve both the accuracy of existing LLM outputs and their learning process through reinforcement learning.
Methodology
Math-Shepherd employs a Process Reward Model (PRM) to evaluate each reasoning step of a solution, unlike traditional method outcome reward models (ORM) that assess entire responses holistically. Key innovations in Math-Shepherd include:
- Automatic Process Annotation: Inspired by Monte Carlo Tree Search, this framework automatically generates supervision labels by using a "completer" to explore multiple reasoning pathways from an intermediate step. The potential correctness of a step is gauged based on its ability to lead to a correct final result, enabling a novel construction of dataset annotations without human input.
- Verification and Reinforcement Learning: Math-Shepherd contributes to two main aspects:
- Verification: It reranks multiple solutions from LLMs, improving accuracy by selecting the most promising reasoning pathways.
- Reinforcement Learning: Integrating Math-Shepherd with Proximal Policy Optimization (PPO) for step-by-step learning allows LLMs to incrementally improve their reasoning chains.
The implementation of Math-Shepherd was tested on well-established mathematical reasoning benchmarks, such as GSM8K and MATH, exhibiting significant accuracy improvements with and without reinforcement learning strategies.
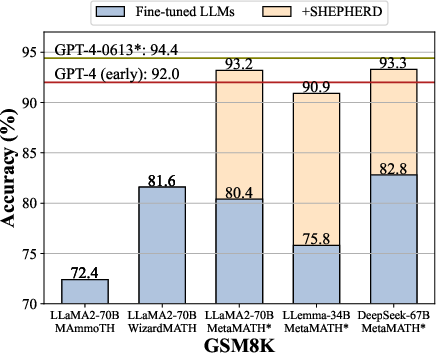
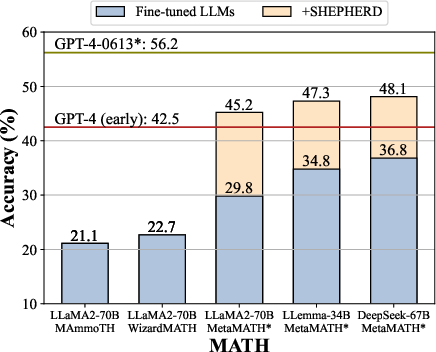
Figure 1: We evaluate the performance of various LLMs with Math-Shepherd on the GSM8K and MATH datasets. All base models are finetuned with the MetaMath dataset.
Results
Math-Shepherd demonstrated exceptional performance improvements across different LLMs:
Analysis
Numerous insights were gleaned from the experimentation with Math-Shepherd, highlighting key strengths and areas for further exploration:
- Data Quality and Efficiency: The approach showcased high efficiency in utilizing automatically annotated datasets, consistently performing well regardless of training set size compared to traditional ORM.
- Model Versatility: Math-Shepherd adeptly handled large model outputs, such as DeepSeek-67B, further indicating its scalability and adaptability.
- Future Potentials: The impressive performance indicates promising avenues for integrating further LLM training and iterative methods to refine reward models.
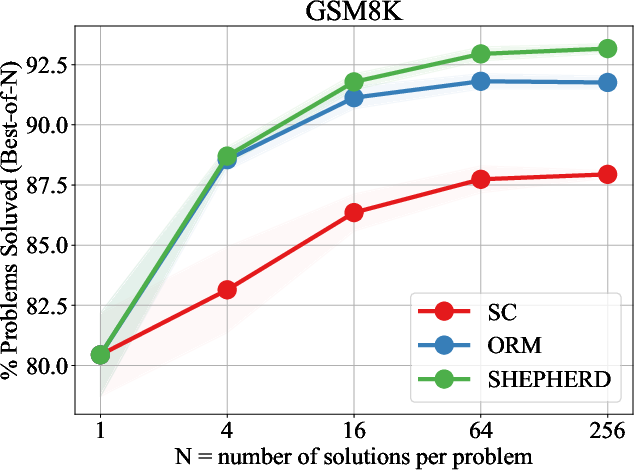
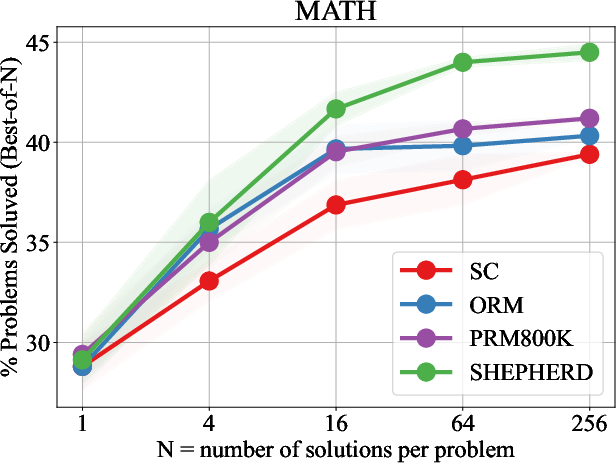
Figure 3: Performance of LLaMA2-70B using different verification strategies across different numbers of solution candidates on GSM8K and MATH.
Implications and Future Work
The Math-Shepherd framework signifies a significant stride in automated LLM evaluation and improvement, particularly in mathematically intense reasoning tasks. It advocates for process-level enhancements and stands to bolster both theory and practical implementations in AI. Encouraging further exploration, future research could focus on iterative model refinement and broader applications of automatic process annotation methodologies, expanding beyond mathematical reasoning to other complex cognitive domains.
Conclusion
Math-Shepherd introduces an innovative, automatic process supervision technique for LLMs that stands to influence how verification and reinforcement learning are approached in AI systems tackling mathematical and potentially other multistep reasoning challenges. The adaptability and efficacy shown in this work underline its potential to redefine LLM training paradigms, offering a substantive advancement in model supervision devoid of manual annotation constraints.