- The paper introduces the PDA method, integrating prompt tuning to enhance unsupervised domain adaptation by reducing domain discrepancies.
- It employs a bifurcated framework with a base branch for class discrimination and an alignment branch for image-guided feature tuning.
- Experimental results on Office-Home, Office-31, and VisDA-2017 demonstrate superior accuracy and reduced metrics such as MMD and KL divergence.
Prompt-based Distribution Alignment for Unsupervised Domain Adaptation
In "Prompt-based Distribution Alignment for Unsupervised Domain Adaptation," the authors introduce a novel method for improving unsupervised domain adaptation (UDA) utilizing prompt-based techniques within vision-LLMs (VLMs). The paper presents the Prompt-based Distribution Alignment (PDA) methodology, which seeks to enhance domain adaptation performance by incorporating domain knowledge into prompt learning, effectively minimizing distribution discrepancies through innovative prompt engineering.
Introduction
The study acknowledges the substantial performance achieved by large pre-trained VLMs, such as CLIP, on various downstream tasks. However, it identifies the shortcomings of existing approaches in handling unsupervised domain adaptation, particularly in prompt engineering, which is crucial for aligning domain knowledge between source and target domains. To address this, the authors propose the PDA method comprising two main components: the base branch, which ensures class discrimination, and the alignment branch, which reduces domain discrepancies. This bifurcated approach allows VLMs to better adapt to UDA tasks.
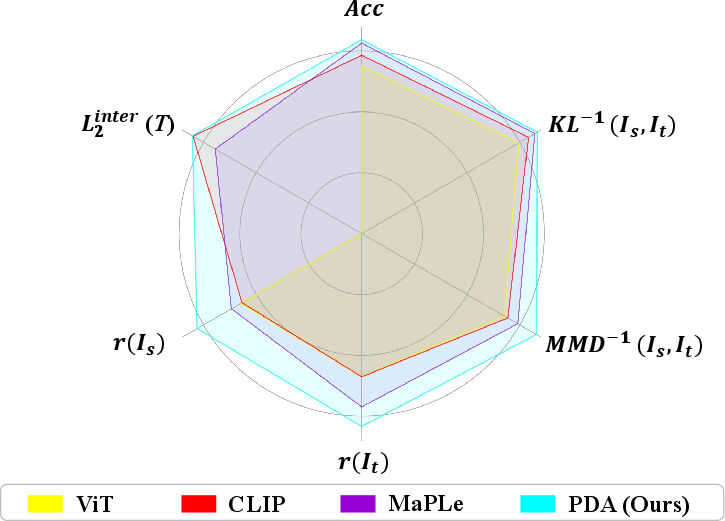
Figure 1: Metric comparisons on Office-Home. Higher values are better. r measures the compactness of features (i.e., the division of inner-class L_2 distance and inter-class L_2 distance L2inter).
Methodology
Base Branch
The PDA method's base branch employs multi-modal prompts to integrate class-related representation into the prompts via visual and textual information. Text prompts are transformed to guide the encoding process of images, allowing domain-specific alignments in visual texts.
Contrastive loss function aligns the image and text representations in both source and target domains, ensuring consistency and discrimination across classes. This is facilitated through the generation of pseudo labels and optimization using contrastive losses for source-domain data and pseudo-labeled target-domain data.
The base branch effectively enhances class discriminability through prompt tuning techniques, thereby improving the model's ability to discern between classes in varying domains.
Alignment Branch
The alignment branch introduces the image-guided feature tuning (IFT) mechanism. Feature banks are constructed for both source and target domains based on visual features with high-confidence scores. These banks are utilized in IFT to reinforce cross-domain features and augment image representations.
IFT utilizes attention mechanisms to enable inputs from image features to attend to domain-specific feature banks, alleviating domain shifts and promoting self-enhanced and cross-domain feature integration.
The total loss in PDA includes contributions from base and alignment branches, enabling end-to-end tuning of multi-modal prompts to facilitate domain alignment effectively.
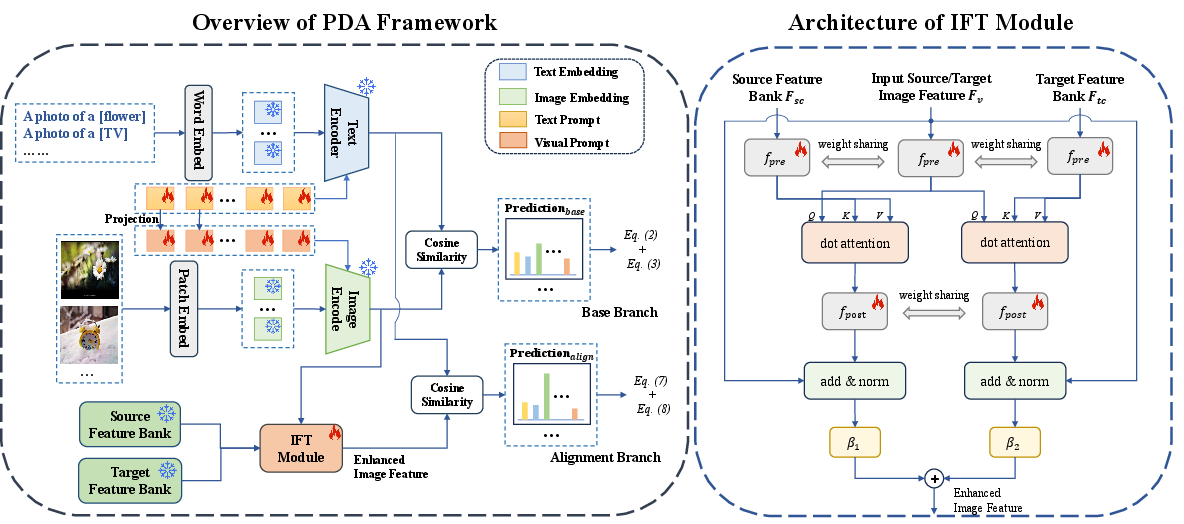
Figure 2: Overview of the proposed Prompt-based Distribution Alignment (PDA) method.
Experimental Results
The experiments conducted across Office-Home, Office-31, and VisDA-2017 datasets demonstrate PDA's superior performance compared to existing prompt tuning and domain adaptation methods. Results show PDA achieves higher accuracy and more compact feature representations, signifying improved domain alignment capabilities and model discriminability.
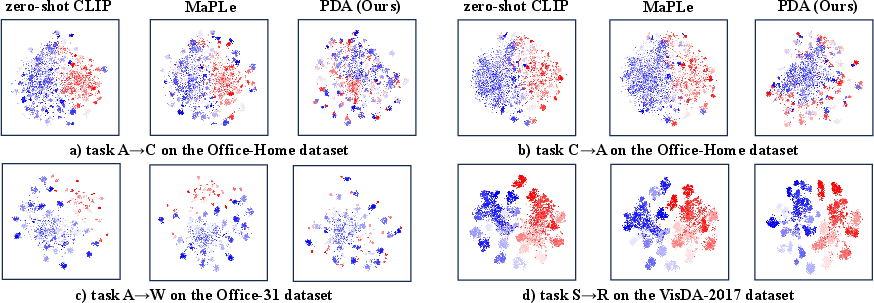
Figure 3: The t-SNE visualization for different tasks on the three datasets with zero-shot CLIP, MaPLe, and our PDA method.
PDA consistently outperforms MaPLe and baseline methods by achieving a lower maximum mean discrepancy (MMD) and KL divergence, evidencing negligible domain discrepancy and more refined class representations.
Implications and Future Work
The PDA method exemplifies how integrating prompt-based techniques can address long-standing challenges in unsupervised domain adaptation by effectively minimizing domain shifts via distribution alignment. It extends the applicability of VLMs to UDA tasks and underscores the importance of multi-modal interactions in domain adaptation. Future work may explore further integrating domain knowledge into prompt alignment for broader applications in UDA and VLMs.
Conclusion
In summary, the "Prompt-based Distribution Alignment for Unsupervised Domain Adaptation" paper presents a significant enhancement in UDA through innovative use of prompt-based learning, effectively reducing domain discrepancies and improving model generalization across varied domains. This work sets a precedent for integrating domain knowledge into multi-modal models, paving the way for further advancements in domain adaptation techniques.
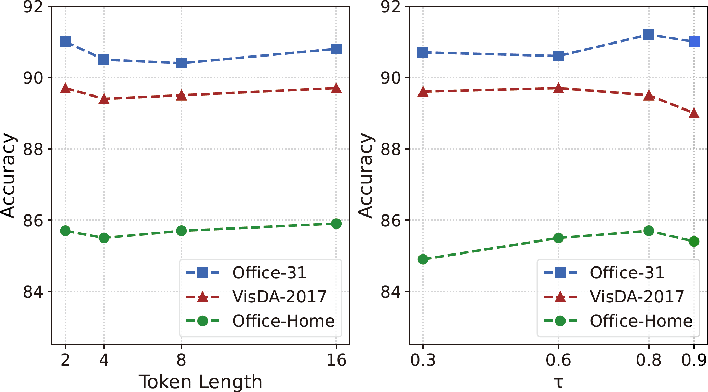
Figure 4: Sensitivity analysis of the context token length (left) and pseudo label threshold tau (right) on three datasets.