- The paper introduces a prompt-based zero-shot domain adaptation framework that employs a teacher-student model with distilled CLIP and YOLOv11 nano for efficient real-time adaptation.
- The paper presents Prompt-driven Instance Normalization (PIN) for aligning source features to target domains purely using textual prompts, eliminating the need for target images.
- Experimental results on the MDS-A dataset show up to 7× faster adaptation and 5× faster inference compared to state-of-the-art methods, proving the framework’s efficiency.
Prompt-Based Zero-Shot Domain Adaptation Framework
Introduction
The paper "Prmpt2Adpt: Prompt-Based Zero-Shot Domain Adaptation for Resource-Constrained Environments" proposes a novel framework specifically tailored for environments with limited computational resources, such as drones. The work addresses the challenge of Unsupervised Domain Adaptation (UDA) by introducing a prompt-driven approach that adapts object detection models to new domains using solely source domain data and textual prompts, without requiring images from the target domain (Figure 1). This is achieved through efficient feature alignment using a teacher-student paradigm, making the framework suitable for real-time deployment in resource-constrained scenarios.
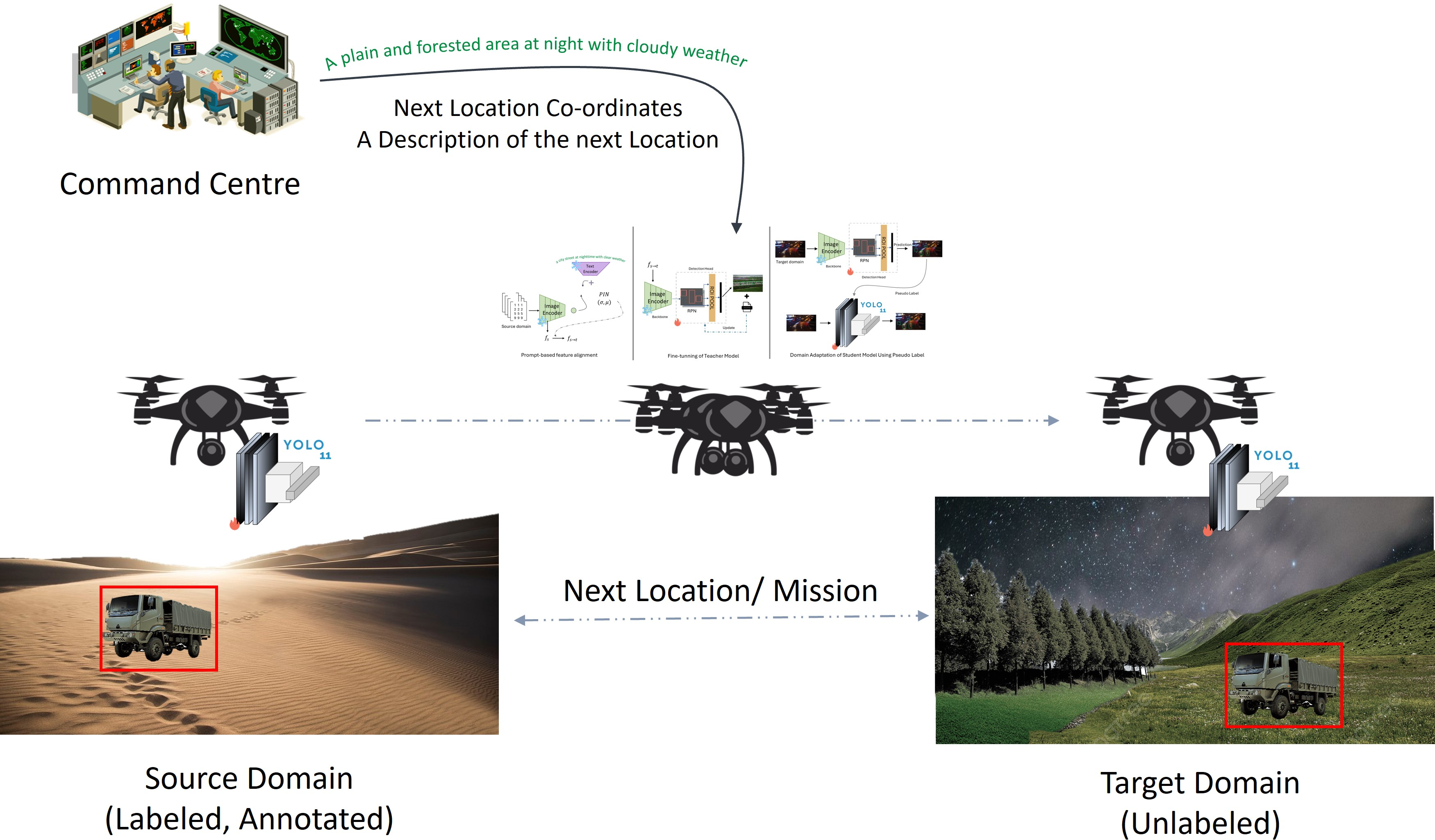
Figure 1: Prmpt2Adpt addresses UDA in a zero-shot setting, where the model is trained solely on the source domain and adapts to the target domain using only textual prompts.
Framework Overview
Prmpt2Adpt stands out for its simplicity and efficiency. The framework employs a distilled CLIP model as the frozen backbone of a Faster R-CNN teacher model (Figure 2). This teacher generates pseudo-labels to guide the on-the-fly adaptation of a compact YOLOv11 nano student model, allowing the system to operate effectively in environments with constrained computational capacity.
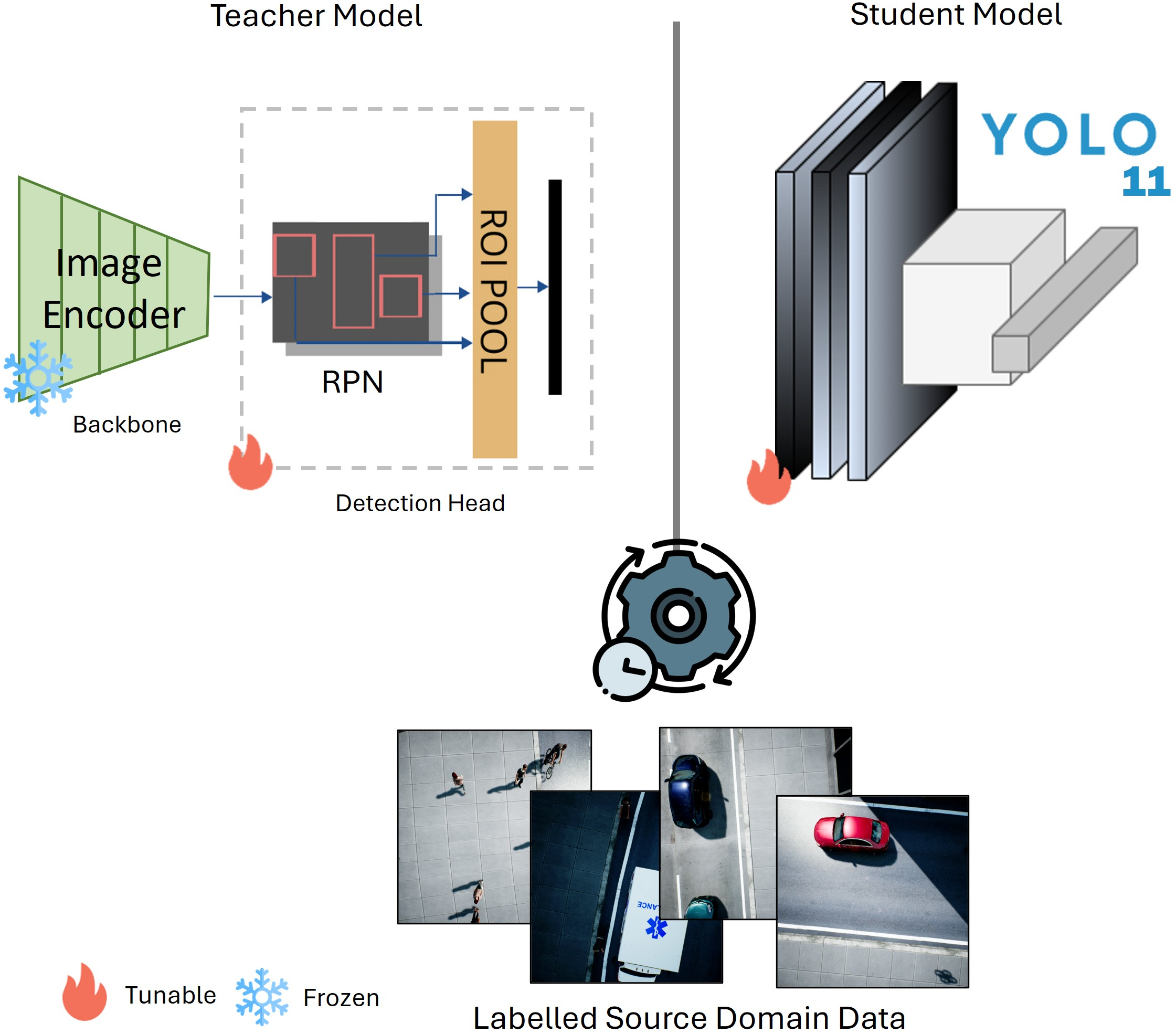
Figure 2: Overview of the teacher-student model architectures used in our proposed framework.
The core innovation lies in the ability to steer highly semantic features of the image data from the source domain toward the target domain using prompt-based feature alignment (Figure 3). This mechanism leverages embeddings from CLIP's image and text encoders to guide adaptation using natural language prompts, enhancing the framework's adaptability without direct access to target-domain data.
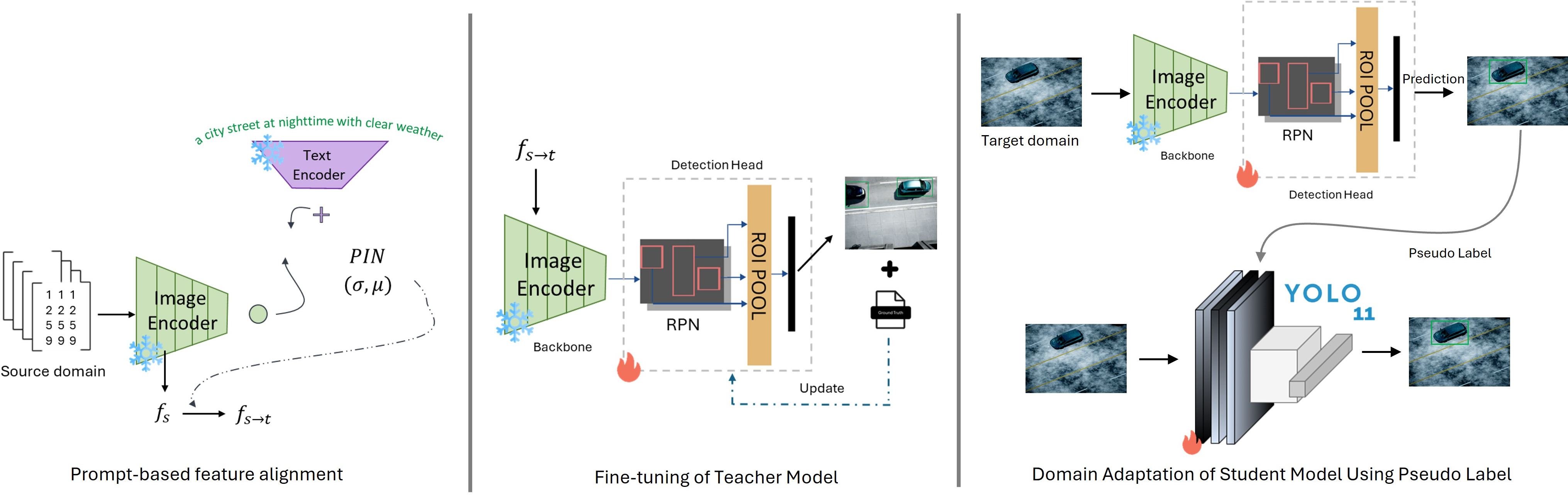
Figure 3: Overview of our proposed Prmpt2Adpt framework.
Teacher-Student Model Design
The teacher model is equipped with a distilled version of the CLIP model, chosen for its semantic richness and computational efficiency. By employing a Region Proposal Network (RPN) and ROI pooling layers trained specifically on labeled source-domain data, the teacher model effectively captures and understands the source domain's visual semantics while guiding adaptation towards the target domain via pseudo-labels.
For the student model, YOLOv11 nano is selected due to its low computational needs and real-time inference capability, making it highly suitable for deployment in drones. The student model receives guidance from the teacher's pseudo-labels, allowing rapid domain adaptation essential for operational efficiency in constrained environments.
Feature Alignment with Prompts
Prompt-driven Instance Normalization (PIN) is a key component of Prmpt2Adpt, inspired by AdaIN, facilitating feature alignment through semantic guidance from natural language descriptions (described in Algorithm 1). The PIN technique effectively steers source-domain features towards the target domain semantics by optimizing statistical parameters derived from CLIP embeddings, enhancing the model's performance without direct exposure to target-domain images.
Experimental Results
The proposed framework was tested on the MDS-A dataset, showcasing its competitive performance compared to existing methods. Despite the reduced model complexity, Prmpt2Adpt exhibited improved adaptation efficiency with up to 7× faster adaptation and 5× faster inference times than state-of-the-art methods PODA and ULDA (Figure 4).
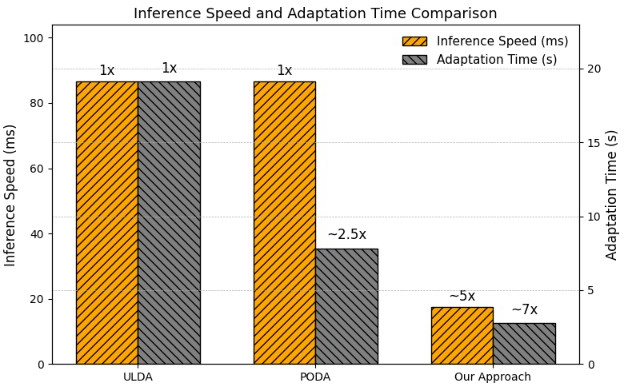
Figure 4: Comparison of inference and adaptation time between our proposed approach and state-of-the-art methods PODA and ULDA.
Furthermore, Figure 5 demonstrates the impact of domain shift on detection accuracy across multiple target domains without adaptation, highlights the significant degradation when encountering unseen conditions.
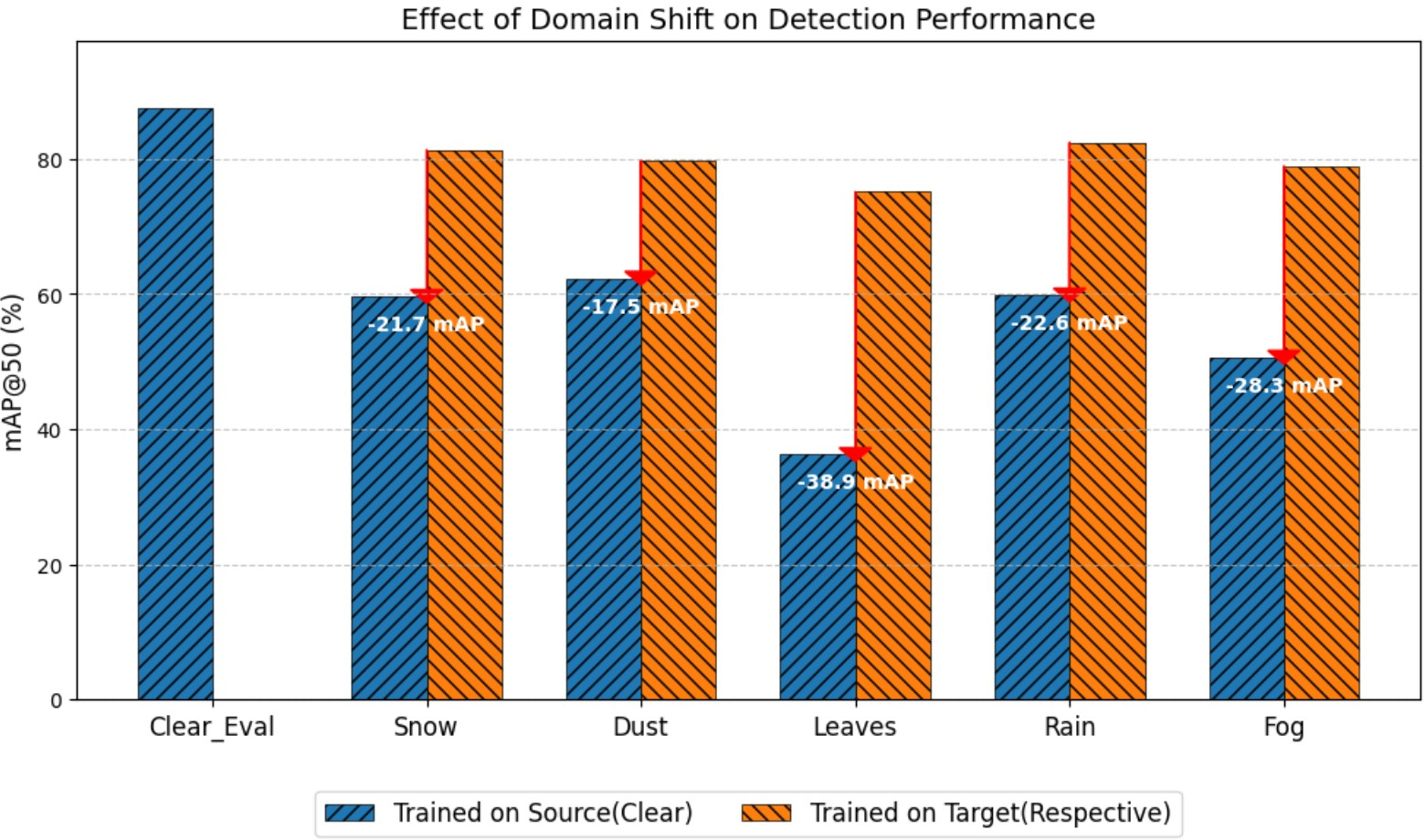
Figure 5: Impact of domain shift on the detection performance of the student model without adaptation.
These results affirm the framework's efficacy in overcoming resource constraints without compromising accuracy, proving it as a feasible solution for real-time applications in critical environments.
Conclusion
Prmpt2Adpt presents a practical and scalable domain adaptation framework for vision systems operating under tight resource constraints, such as drones. By utilizing prompt-based semantic guidance and efficient teacher-student model architecture, this framework addresses major limitations of traditional UDA methods requiring direct access to target-domain data, ensuring rapid adaptation and deployment. Future research could explore extending this approach to broader domain shifts and optimizing detection accuracy further, leveraging advanced LLMs for enhanced semantic understanding.