- The paper presents a novel three-tiered pipeline to generate high-quality persona-based conversational datasets using unsupervised LLM methodologies.
- It leverages a Generator-Critic architecture with a Mixture of Experts to refine dialogue coherence, diversity, and non-toxicity.
- The approach produces a synthetic dataset of 20,000 dialogues, yielding improved conversational quality with Turing test loss rates below 9%.
Faithful Persona-based Conversational Dataset Generation with LLMs
Introduction to Persona-based Conversations
The paper "Faithful Persona-based Conversational Dataset Generation with LLMs" (2312.10007) explores the construction of high-quality conversational datasets tailored to persona-based dialogues utilizing LLMs. Personas are synthetic representations of users' character aspects, providing insights into their personality, motivations, and behaviors. Such constructs foster deeper interactions between conversational models and users by capturing an individual's background and preferences within the interactions. Previous datasets in this domain, such as Persona-Chat, have limitations including small size, outdated dialogues, irrelevant utterances, and contradictions within persona attributes. This research proposes a novel framework to expand these datasets, maintaining fidelity and dynamic adaptability using unsupervised LLM methodologies.
Framework Overview
The framework introduces a three-tiered pipeline comprising user generation, user pairing, and conversation generation to establish a large-scale, dynamic conversational dataset.
- User Generation: This step enhances an initial set of persona attributes to create plausible user profiles. It incorporates persona expansion via LLMs and ensures consistency through natural language inference.
- User Pairing: Users are matched based on persona profile similarities, utilizing semantic analysis which maximizes meaningful interaction potential.
- Conversation Generation: Leveraging a Generator-Critic architecture similar to self-feedback mechanisms, plausible persona-based dialogues are iteratively refined, improving sample quality with each cycle.
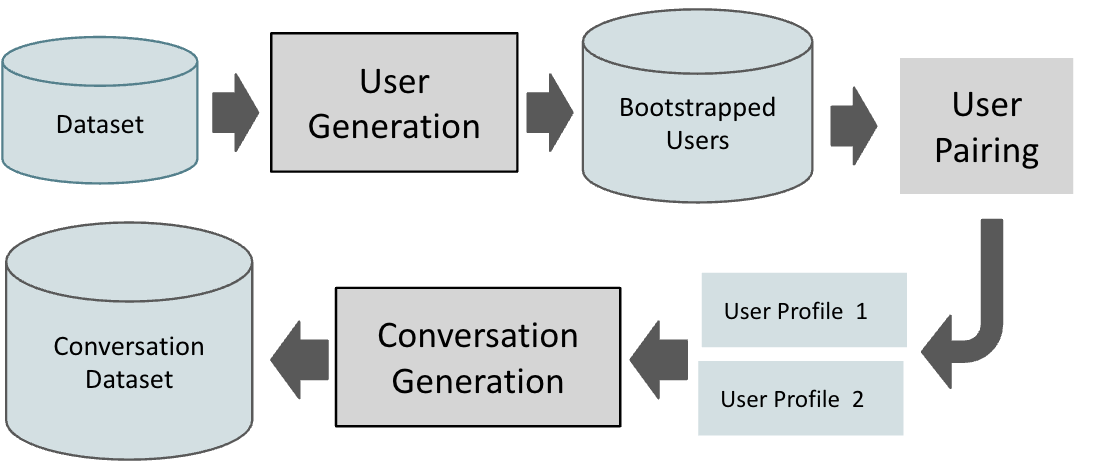
Figure 1: Dataset Augmentation Pipeline
Research Methodology
The approach embodies unsupervised methods significantly reducing human labor by utilizing LLM-driven processes to generate specialized personas and associated dialogues automatically. LLMs are prompted through systematic querying to create diverse and novel user attributes and converse naturally adhering to predefined quality criteria including persona fidelity. Furthermore, it incorporates Mixture of Experts (MoE) within critics ensuring dialogue coherence, depth, consistency, diversity, likability, persona faithfulness, and non-toxicity.
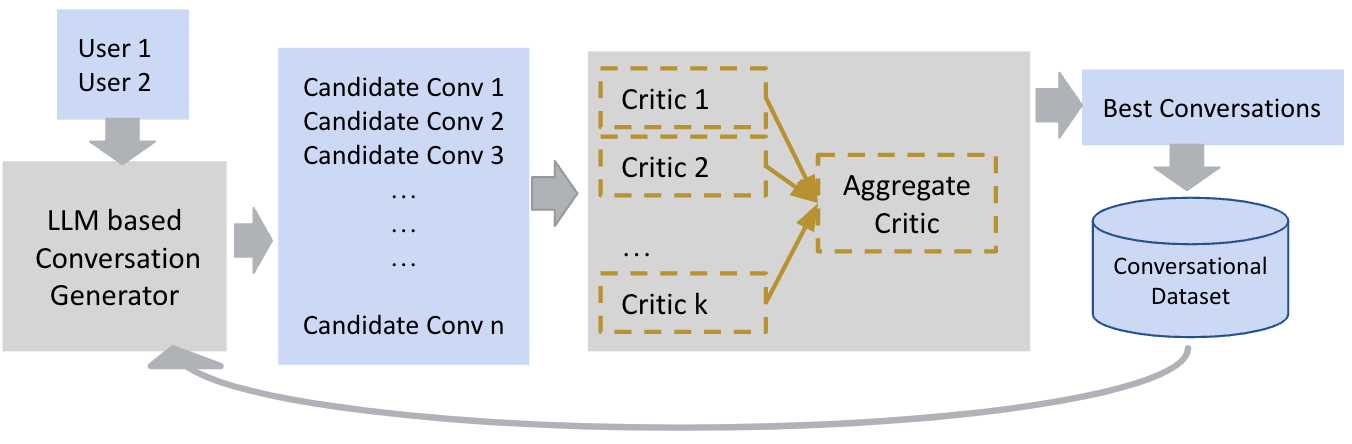
Figure 2: The Generator-Critic Architecture for Conversation Generation
Dataset Evaluation
Synthetic-Persona-Chat, containing 20,000 dialogues synthesized from initial seeds, represents the model's practical application. Through rigorous evaluation, it demonstrated superior performance metrics across conversational quality and user engagement dimensions versus baseline datasets like Persona-Chat. For example, chat conversation quality exhibited notable improvements, reducing losing rates in Turing tests to below 9%.
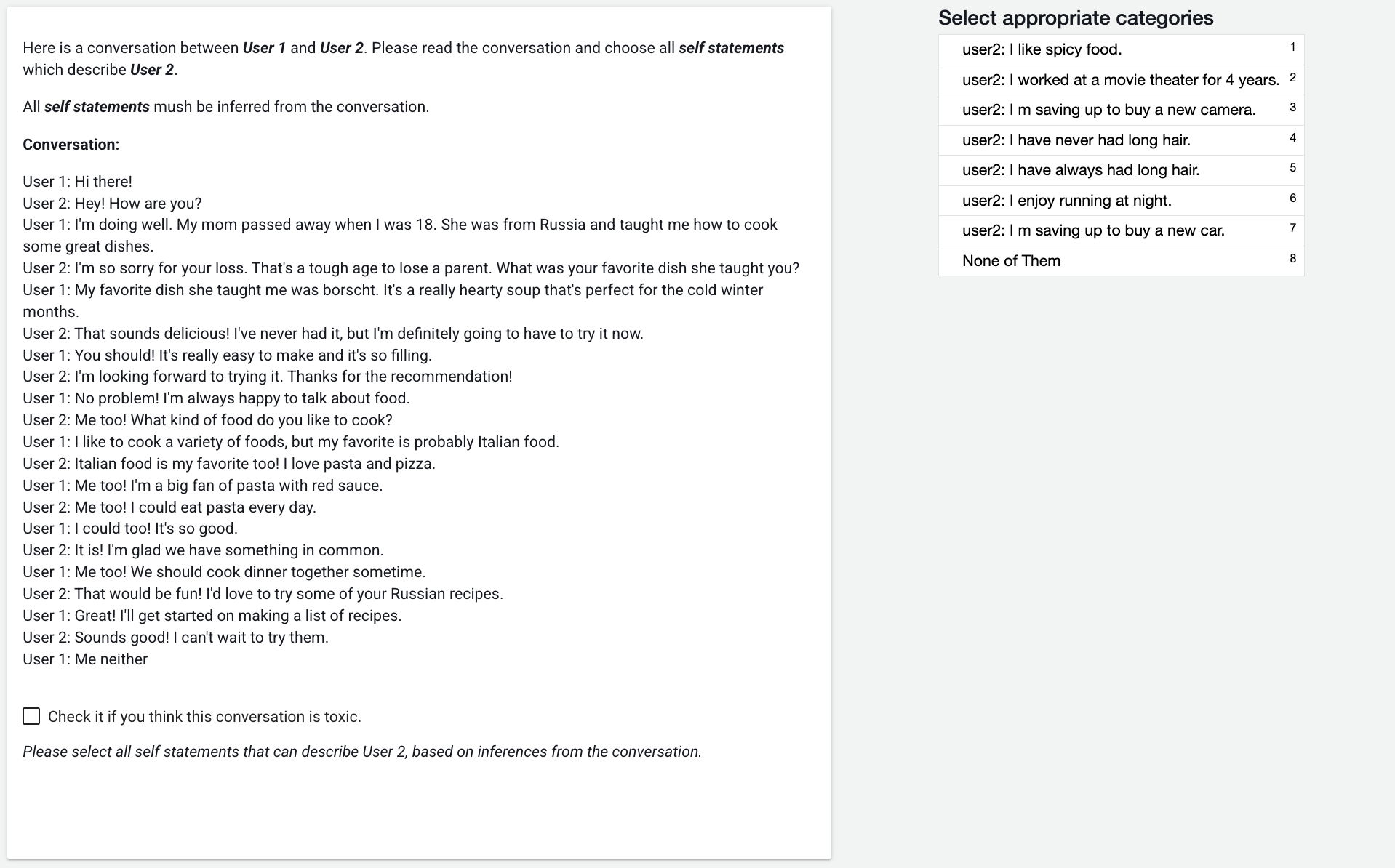
Figure 3: Preview of the Faithfulness Task on the Crowdsourcing Platform.
Implications and Future Avenues
The ability to synthesize persona-driven dialogues at scale utilizing LLMs has numerous implications. This framework enables advancements in persona-aware conversational agent development, supporting specialized conversational tasks, and potentially generating industry-specific dialogue datasets. The iterative Generator-Critic methodology can be extended beyond persona datasets to any domain requiring nuanced conversational data synthesis, adapting to emerging trends and evolving user narratives consistently.
Conclusion
The paper successfully integrates a novel LLM-driven framework to significantly enhance persona-based conversational dataset fidelity and dynamic adaptability, showcasing potential for widespread application in AI-driven user interaction modeling. Continual developments and optimizations could broaden its applicability, facilitating richer, user-centric dialogue systems. Future research may explore further reductions in computational costs and explore diverse personas' intangibles beyond simplistic user attribute definitions.