- The paper presents PERSONA, a testbed for evaluating language model alignment using 1,586 synthetic personas based on U.S. census data.
- The methodology employs demographic sampling, psychodemographic enrichment, and GPT-4 to generate consistent personas for scalable testing.
- The evaluation demonstrates that conditioning methods, particularly summarization, improve models’ role-playing consistency with diverse user profiles.
PERSONA: A Reproducible Testbed for Pluralistic Alignment
Introduction
The rapid progress of LMs introduces the need for alignment with diverse user values. Existing preference optimization methods frequently consolidate majority opinions while sidelining minority viewpoints. To tackle this issue, the paper presents PERSONA, a reproducible testbed designed to evaluate and enhance the alignment of LMs with diverse user personas. By synthesizing 1,586 distinct personas based on U.S. census data, the framework creates a platform for testing LMs' ability to mimic and align with heterogeneous user profiles.
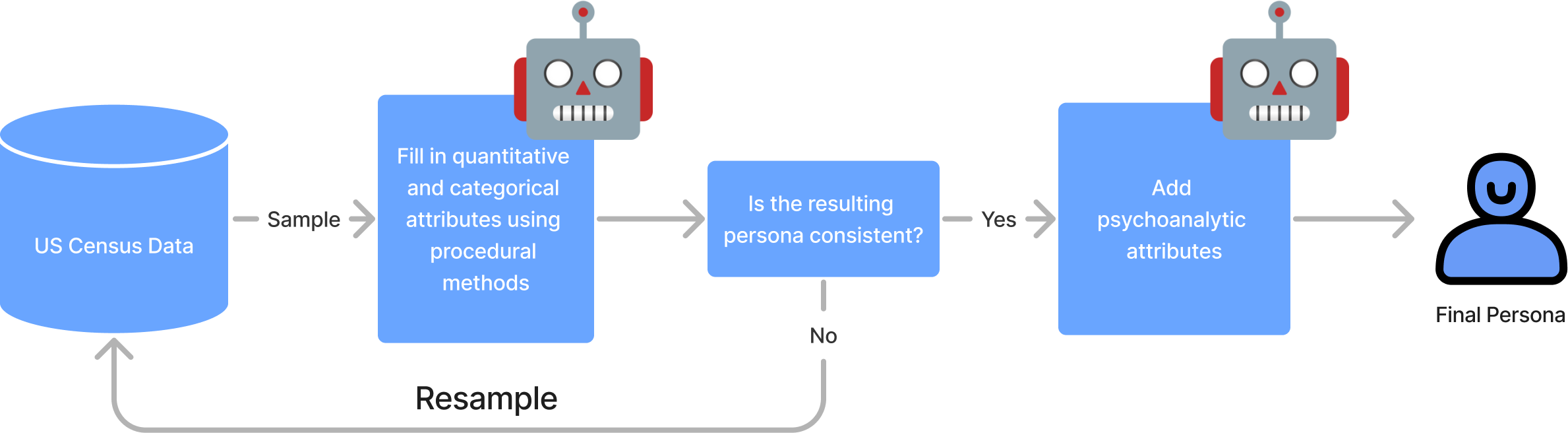
Figure 1: Procedure for generating personas. The above is a flow graph outlining the generation of a single persona.
Challenges in achieving pluralistic alignment arise because LMs are usually trained on data that over-represent certain demographics, further marginalized during RLHF by using limited pools of labelers. Current algorithms, aiming to echo diverse groups, face inherent challenges since a single model cannot accommodate conflicting group preferences. The proposed solution lies in leveraging synthetic personas, which serve as a practical alternative to existing real-user datasets like PRISM, addressing limitations through scalable and reproducible testing environments.
Methodology
Persona Generation:
The procedure of generating personas follows multiple steps: sampling demographic data from PUMS, enriching profiles with psychodemographic data, employing LLMs for additional attribute creation, and ensuring consistency through GPT-4 (Figure 1). The process ensures that personas are grounded in realistic demographic statistics, mirroring the diversity and varied characteristics of the U.S. population.
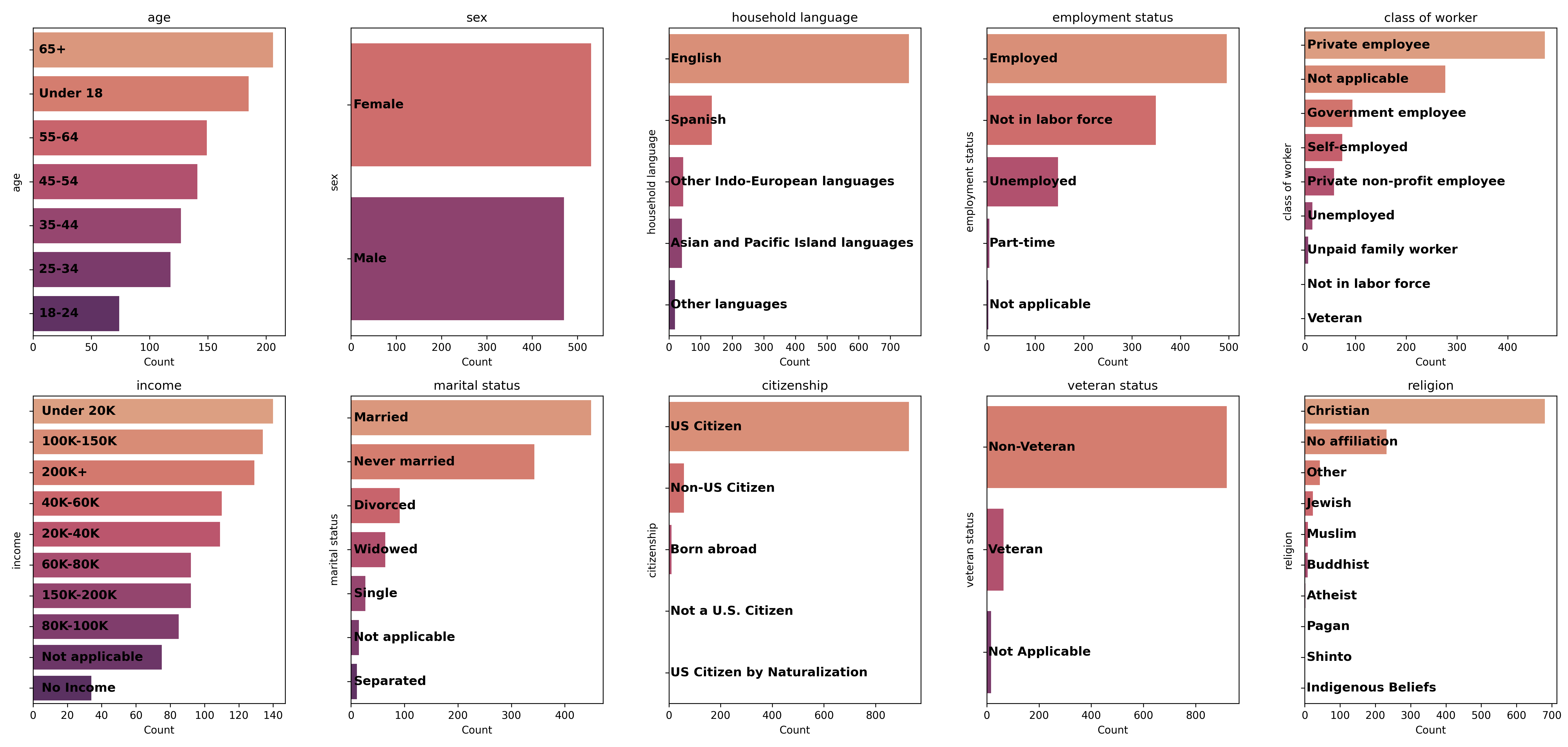
Figure 2: Histograms of group statistics of our demographic of synthetic personas.
Dataset Construction:
Preference datasets are assembled using prompts extracted from the PRISM dataset, focusing on questions liable to eliciting diverse responses. The dataset, comprising 3,868 prompts and 317,200 feedback pairs, facilitates evaluating generalization and alignment by maintaining independence between selected personas and prompt topics.
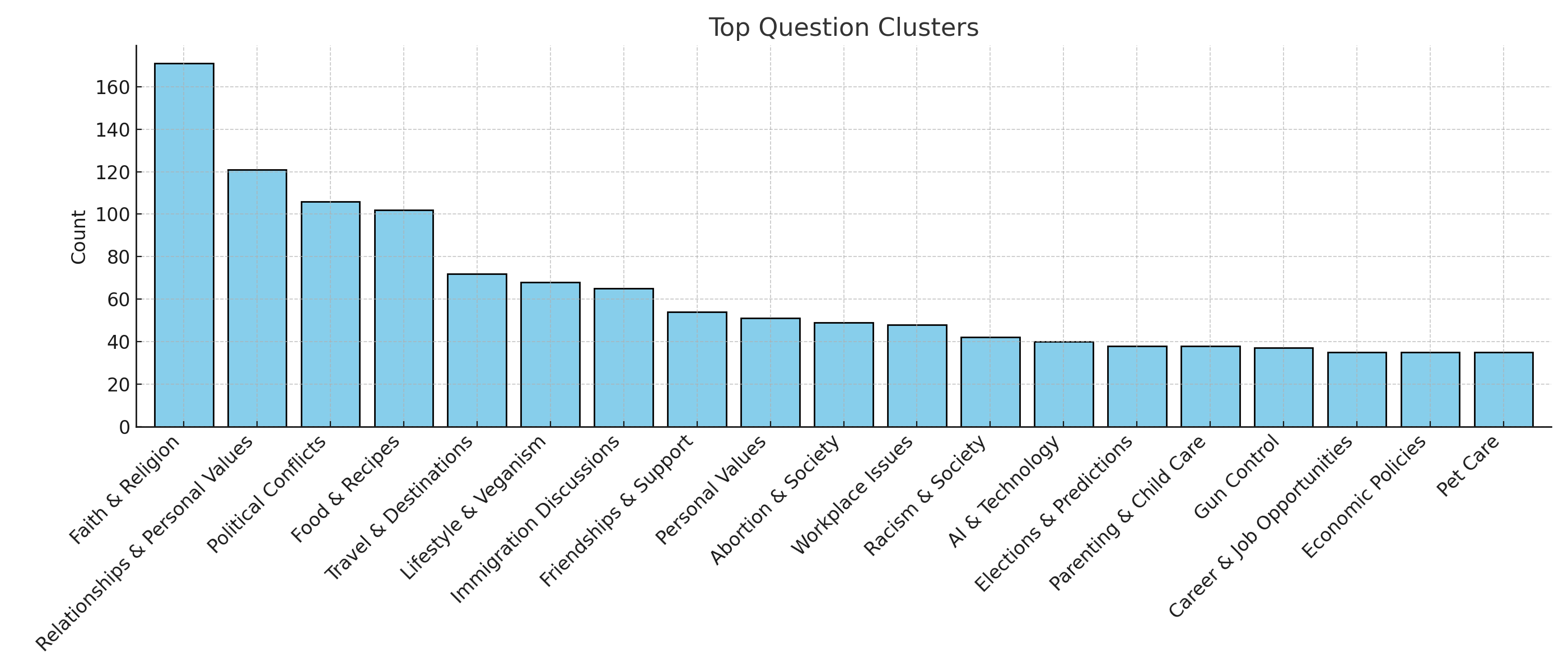
Figure 3: Distribution of prompt topics in the Persona dataset.
Evaluation and Results
The framework evaluates human-verified synthetic personas, revealing the models' efficiency in aligning with user profiles and preferences. Notably, the role-playing capabilities of models like GPT-4 show substantial agreement with human annotators, outperforming others in consistency when mimicking personas.
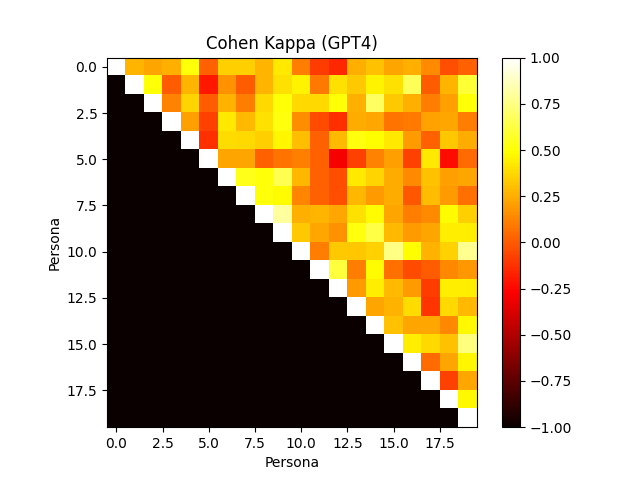
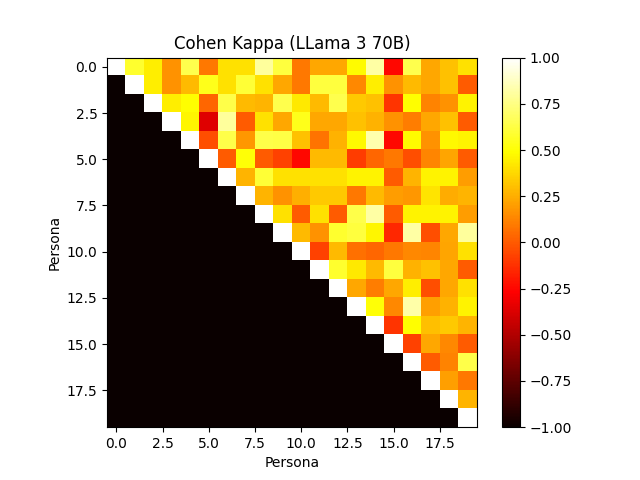
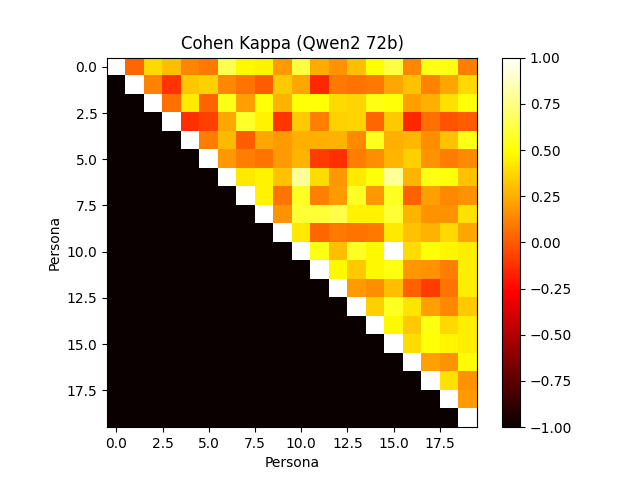
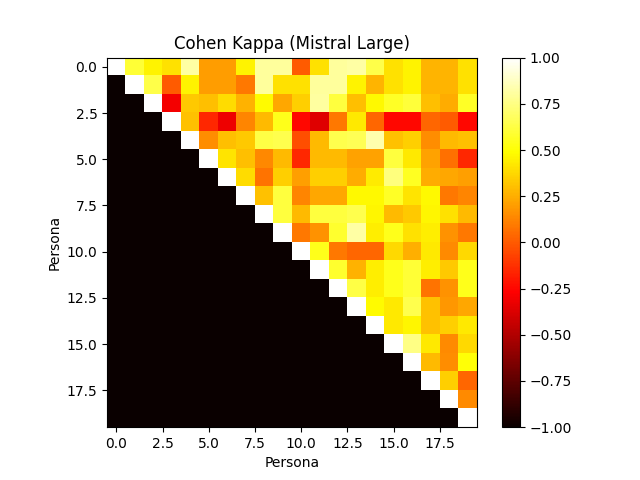
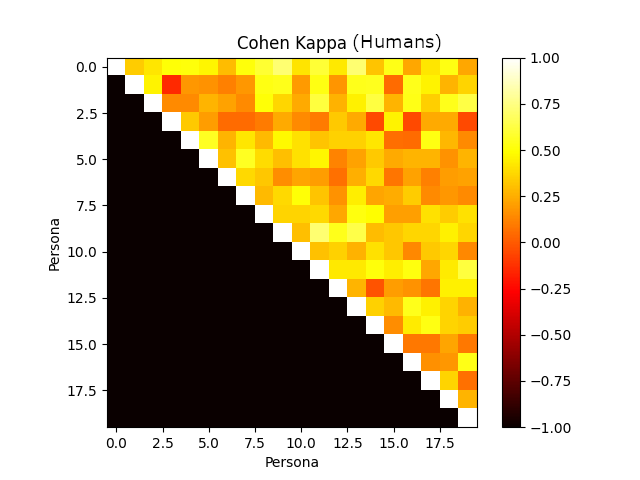
Figure 4: Annotator agreement with various frontier models. Cohen's Kappa confusion matrix.
The use of different conditioning methods on PRISM answer generation confirms summarization as the best-performing result, contrary to weaker outcomes from chain-of-thought prompting (Figure 5).
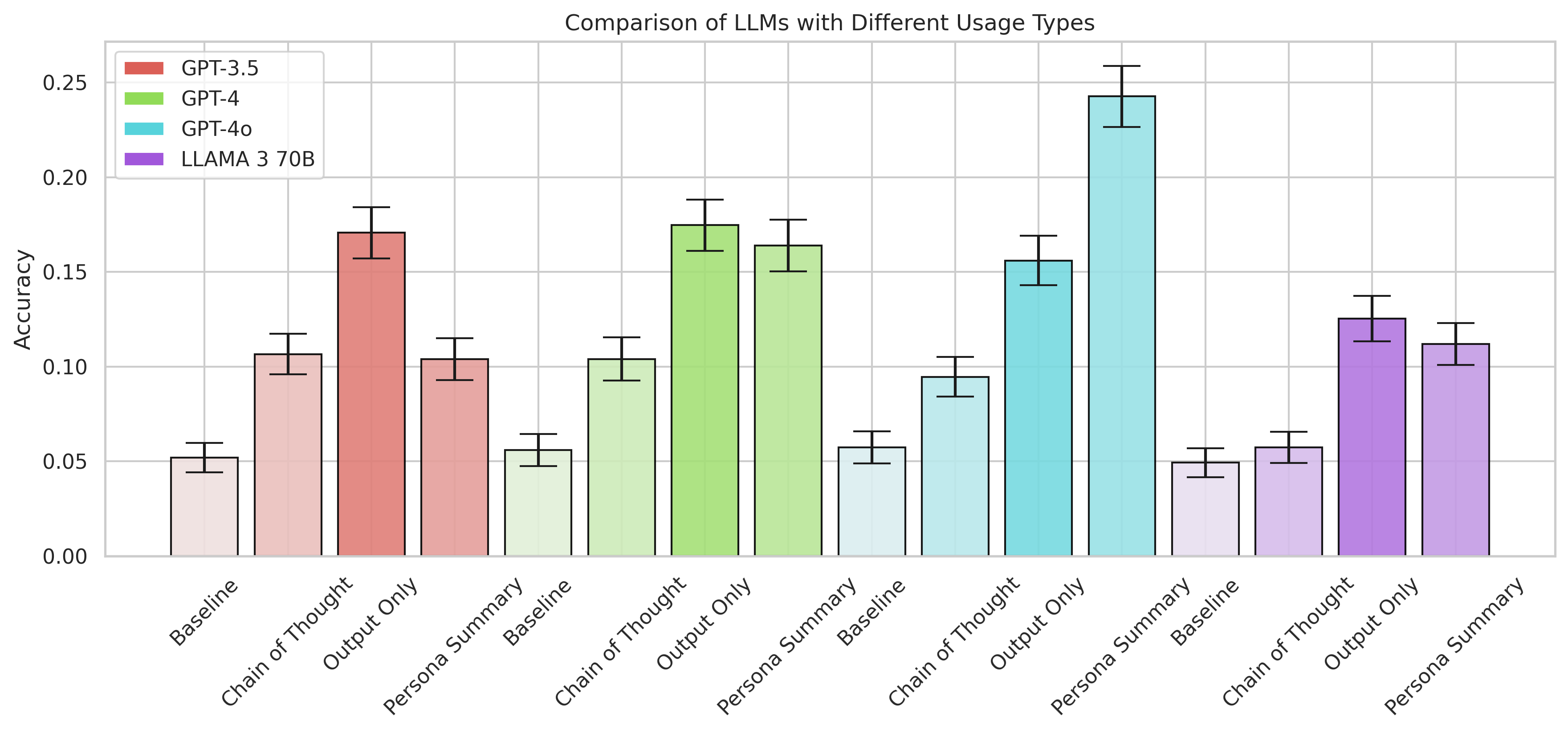
Figure 5: How well various methods of conditioning the PRISM answer generation work.
Conclusion
The PERSONA testbed highlights the importance of pluralistic alignment for LMs, offering a robust, scalable framework for evaluating and enhancing alignment with diverse and synthetic user profiles. The project underscores the limitations of focusing exclusively on U.S. demographics, proposing future expansions to global perspectives. The promising results suggest a meaningful progression toward adaptable, personalized AI applications.
In summary, PERSONA serves as a crucial resource for developing personalized LMs, indicating potential future work in global demographic representation, further contributing to equitable AI advancement.