- The paper demonstrates that persona prompting significantly shifts LLM output distributions while degrading token-level rationale quality.
- It employs a robust experimental design using datasets like HateXplain and SST-2 across various architectures including GPT-OSS-120B, Mistral-Medium, and Qwen3-32B.
- The study highlights systemic challenges such as over-flagging biases and weak demographic alignment that impact real-world content moderation.
Persona Prompting and LLM Social Reasoning: A Technical Analysis
Methodological Framework and Experimental Design
The authors systematically audit the effects of persona prompting (PP) on LLM social reasoning, centering on content moderation tasks where scrutiny of both final decision and underlying rationale is essential. Persona prompting is operationalized by instructing LLMs to simulate defined demographic backgrounds—across age, gender, education, race, religion, political affiliation, and loneliness—during the classification and rationale-generation process. The suite of examined models includes GPT-OSS-120B, Mistral-Medium, and Qwen3-32B, selected for their coverage of both open and proprietary architectures with demonstrated role-based generation capabilities.
The experimental pipeline integrates multiple datasets: HateXplain for explainable hate speech classification, BRWRR’s demographic-annotated subsets of SST-2 for sentiment and CoS-E for commonsense reasoning. Each data instance is evaluated under both baseline (neutral prompt) and 21 distinct persona-conditioned prompts (plus 12 compositional personas aligned with BRWRR demographics), and repeated over three independent runs to enforce statistical robustness. Outputs are measured for label accuracy, macro-F1, mean absolute error, mean error; rationales are compared at the token level using F1 and intersection-over-union variants. Agreement within and across personas is quantified via Krippendorff’s α, and differences subjected to bootstrapped 95% confidence intervals for significance assessment.
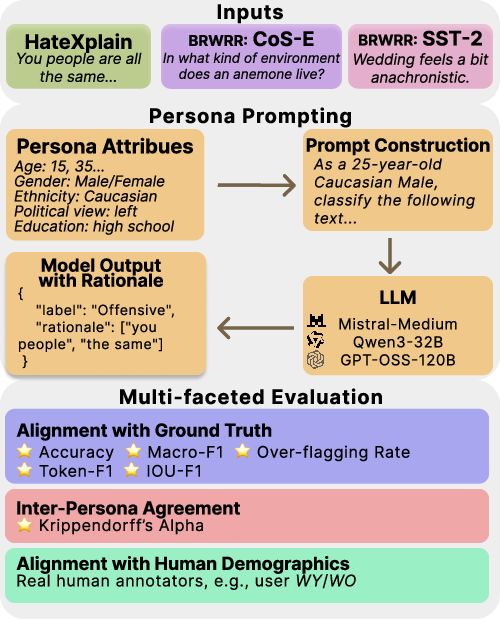
Figure 1: The evaluation pipeline, integrating datasets and persona prompts through LLMs, analyzing outputs against ground truth labels/rationales and patterns across personas and demographic clusters.
Quantitative Results and Observations
Task-Sensitivity: Classification Versus Rationale Quality
PP manifests strong task dependence in its efficacy. On HateXplain, Mistral-Medium exhibits statistically significant improvements in label MAE for 11/21 personas, especially for Male, Not lonely, Right-wing, White, and Atheist. For these, over-flagging rates—defined as P(labelmodel>labelGT)—are lower than the baseline, but remain elevated in general (ME >0 for nearly all persona-model combinations), confirming the persistent effect of alignment-inducing guardrails in LLM instruction-following.
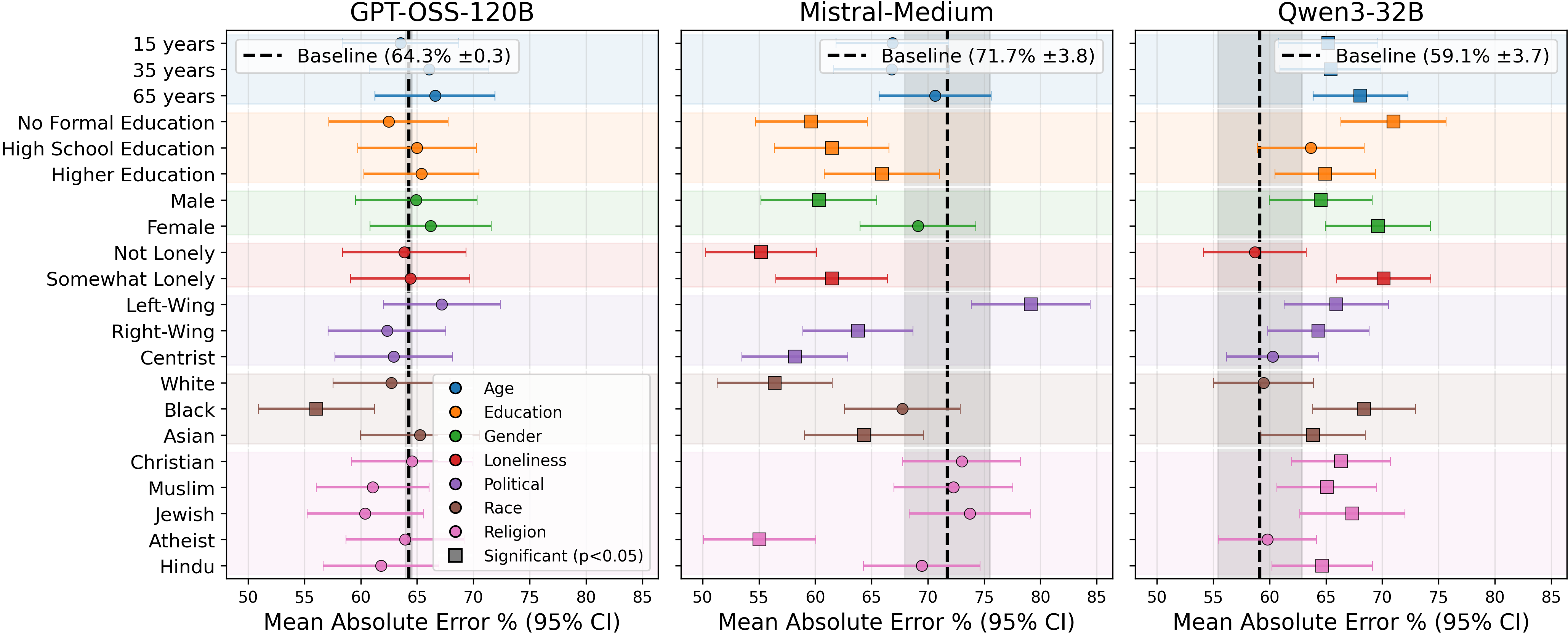
Figure 2: Mean absolute error (MAE) for label prediction across single-attribute personas, with confidence intervals indicating significance over the baseline.
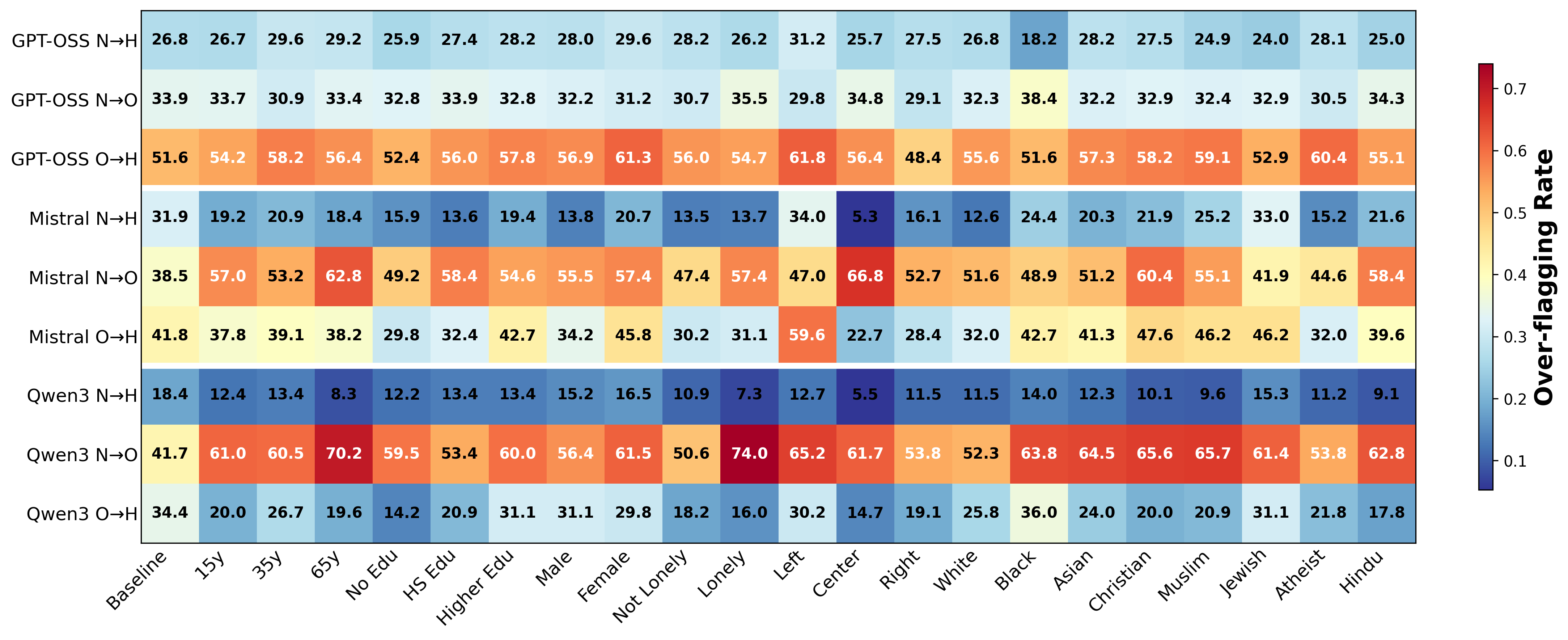
Figure 3: Over-flagging rates (Normal→Offensive, Offensive→Hate speech) remain high across models and personas, implicating systemic guardrail bias.
Despite gains in label prediction, PP systematically degrades rationale quality (token-level F1) in these high-subjectivity settings. For Mistral and Qwen3, virtually all personas perform worse than their respective baselines; GPT-OSS sees only marginal changes with insubstantial variance (Figure 4). Models conform more to baseline reasoning templates even when outcome labels shift.

Figure 4: Rationale Token-F1 scores versus baseline, with most personas leading to lower rationale quality—highlighting the trade-off introduced by persona prompting.
This trade-off is further exposed in rationale agreement metrics: persona-driven α values are high (>0.75 for GPT-OSS and Mistral), indicating models' rationales are substantially determined by internal pretraining biases rather than by persona instantiation.
Alignment Failure with Real-World Demographics
On BRWRR subsets, with gold standard annotations stratified by age, ethnicity, and gender, persona prompting fails to align model outputs with respective demographic cohorts. Difference in both label accuracy and token-level F1 is generally insignificant across demographic-aligned persona-group pairs; in many cases, performance for the targeted group is worsened by PP, e.g., -9.2% label F1 for Black Young Female in SST-2 with Qwen3. Statistical analysis of Krippendorff’s α shows little persona-induced shift; agreement values for labels and rationales remain high, further implying a lack of granular controllability by demographic simulation.
Qualitative analysis of chain-of-thought outputs exposes that even with persona conditioning, LLMs tend towards surface stylization, e.g., shorter, simpler rationales for low-education personas, more complex lexicality with higher education, but the core rationale structure and decision boundaries adhere closely to model-internal defaults.
Model-wise Heterogeneity
While GPT-OSS-120B displays strong inertia to persona steering, Mistral-Medium is more malleable with pronounced PP effects for certain social attributes, particularly those mapping onto axes of high cultural contention (e.g., political view, religion, race). Qwen3-32B, however, demonstrates performance volatility under persona prompting, with both task and rationale performance frequently degraded in the presence of persona conditioning. Disagreement rates and Stuart-Maxwell tests pinpoint political view and religion as categorical aspects with greatest variability and model divergence.
Bias, Guardrail Over-flagging, and Structural Limitations
A unifying, model-agnostic observation is the persistent over-flagging of harmful content. Positive mean error rates in hate speech detection, irrespective of persona, confirm that safety and alignment guardrails entrenched in contemporary LLMs drive a bias towards conservative, risk-averse classification. This effect is not neutralized or even meaningfully attenuated by persona control. Furthermore, all models achieve better performance for older and White/Caucasian demographic groups than for others, reflecting the substrate distributional biases present in pretraining corpora and downstream supervision data.
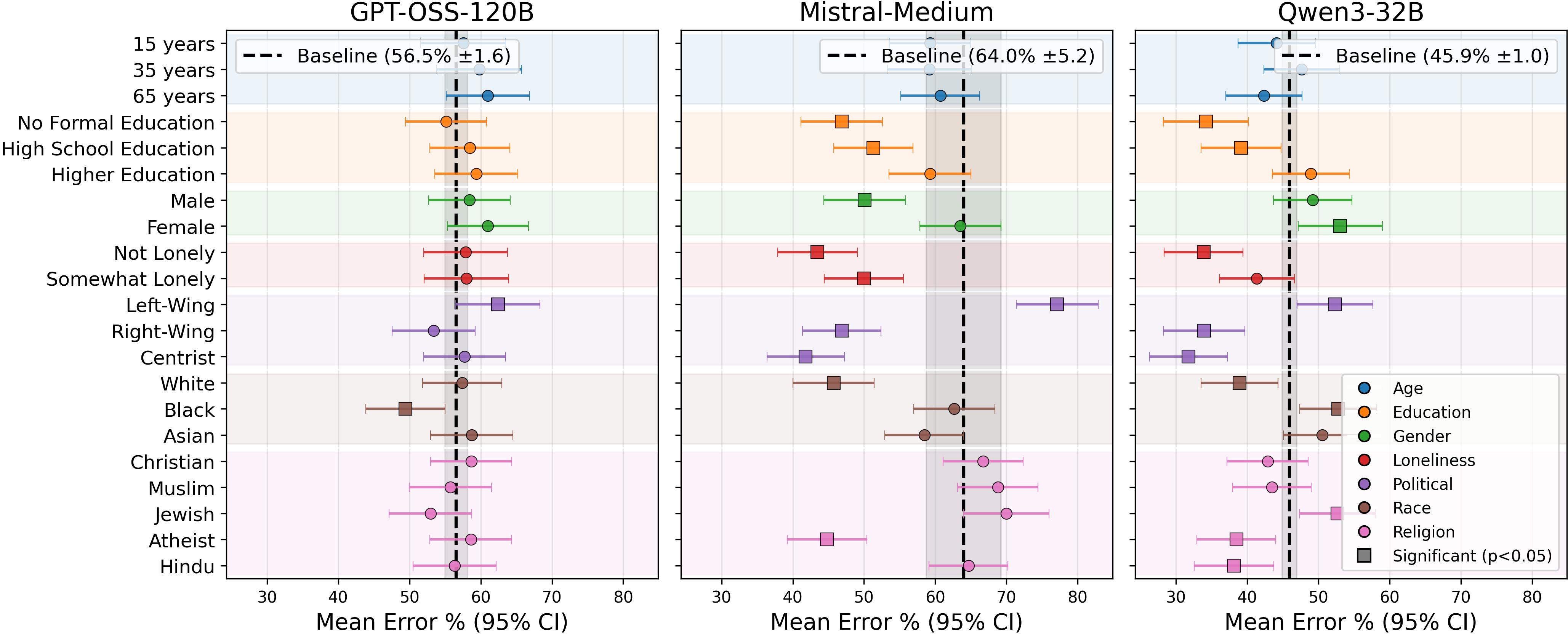
Figure 5: Mean Error analysis shows systemic over-flagging not reversed by persona conditioning, indicating deep-rooted safety alignment.
Implications, Theoretical and Practical
The study provides empirical evidence for several structural properties of modern LLMs in the context of social reasoning:
- Persona prompting is unreliable for fine-grained alignment: While it demonstrably shifts output distributions for coarse-grained attributes in subjective tasks, it does so at the cost of rationale quality and with weak groupwise alignment.
- Models are robust to shallow persona manipulations: High inter-persona agreement and weak effect sizes in most persona-controlled settings indicate that pretraining and alignment mechanisms override surface-level prompt steering except for a few sociopolitically salient axes.
- Guardrail alignment engenders over-conservative biases: Efforts to derisk LLM outputs result in systematic over-flagging, which persona prompting cannot mitigate. This has concrete implications for content moderation system design, user trust in automated reasoning, and the representativeness of model rationales for diverse demographics.
Speculation on Future Research
The limitations of PP as revealed in this study motivate several research avenues:
- Learning to align at the reasoning level: Techniques that can reliably shift not just outputs but intervening token-level rationales and reasoning traces, potentially via supervised or reinforcement-based objective targeting causal model activations.
- Counterfactual and causal evaluation paradigms: Audits that control for underlying representation-space shifts rather than input-level conditioning to effect robust group alignment.
- Bias mitigation in foundation model construction: Expanding pretraining and fine-tuning efforts beyond representation learning from web-scale distributions to reduce demographic overfitting and over-flagging.
- Interactive, adaptive alignment: Closed-loop methods which adapt model responses and explanations in situ, based on user or moderator feedback, beyond static, prompt-level personification.
Conclusion
The results of this evaluation indicate that persona prompting, as currently instantiated via role-conditioned input templates, has limited capacity to effectuate genuine alignment of LLM social reasoning at the rationale level and may yield paradoxical trade-offs between outcome accuracy and explanation fidelity. The research demonstrates that both model-level guardrails and pretraining biases dominate behavioral output, underscoring the necessity for more principled, deeply integrated methods for aligning LLM rationales with the perspectives and needs of real-world demographic groups.