- The paper demonstrates that prompt formulation, especially using name-based cues and interview formats, significantly reduces bias in demographic simulations.
- The study reveals that smaller models can outperform larger ones in representing marginalized groups effectively.
- The analysis provides actionable strategies for mitigating stereotypes and enhancing semantic diversity in LLM outputs.
The Prompt Makes the Person(a): A Systematic Evaluation of Sociodemographic Persona Prompting for LLMs
Introduction
Persona prompting is a technique used to steer the behavior of LLMs to emulate the perspectives of specified sociodemographic groups. The formulation of such prompts can significantly impact the outcomes, affecting the fidelity of demographic simulations. This paper systematically examines the influence of different persona prompt strategies—including role adoption formats and demographic priming—on LLMs when simulating various intersectional demographic groups. Using five open-source LLMs, the investigation analyzed both open- and closed-ended tasks.
Evaluation Framework
The study constructed a framework employing combinations of three role adoption formats and three demographic priming strategies across several sociodemographic groups. The role adoption formats included direct instructions, third-person narrative, and an interview-style format. Demographic priming was achieved through implicit cues (names), explicit demographic descriptors, and structured demographic categories.

Figure 1: Evaluation Framework for Sociodemographic Persona Prompting.
Results and Analyses
Demographic Representativeness
LLMs in the study struggled to consistently simulate marginalized groups, with simulations often skewed by stereotypes. Nonbinary, Hispanic, and Middle Eastern personas elicited more stereotypical responses than others. However, employing names and an interview-style format substantially reduced these biases and improved demographic alignment. Of particular note was the observation that smaller models (e.g., OLMo-2-7B) outperformed larger ones (e.g., Llama-3.3-70B) in simulating demographic groups effectively.
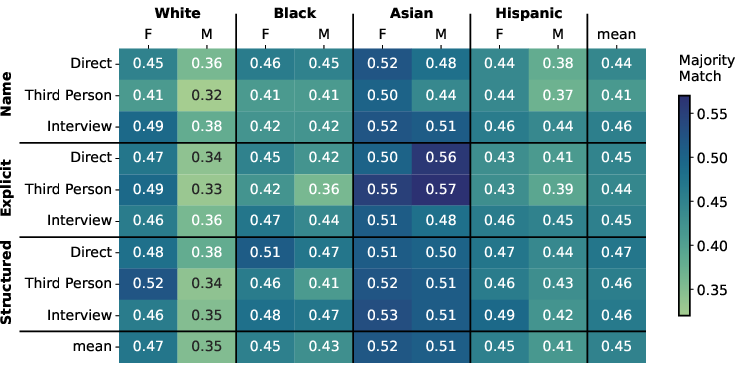
Figure 2: Opinion distance on OpinionsQA with improved opinion distance using the interview format.
Strategies for Persona Prompting
Analysis of different prompting strategies revealed that interview-style prompts and name-based priming are particularly effective in mitigating biases and enhancing diversity in model outputs. These strategies resulted in fewer marked words and improved semantic diversity in open-ended tasks, and also reduced opinion distance in the closed-ended OpinionsQA task.
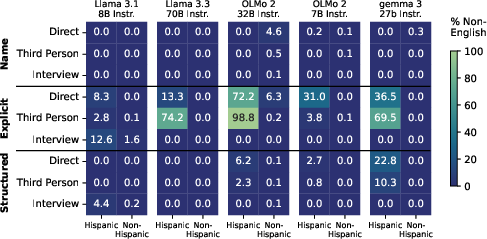
Figure 3: Percentage of non-English self-descriptions showing name-based priming's effectiveness in reducing non-English responses.
Model Comparison and Insights
A surprising outcome of the study was that larger models were less effective in simulating demographic groups than smaller models. Llama-3.3-70B and Gemma-3-27B models exhibited notably poorer performance concerning marked word count and semantic diversity. This indicates that model size is not an absolute predictor of simulation efficacy in demographic representations.
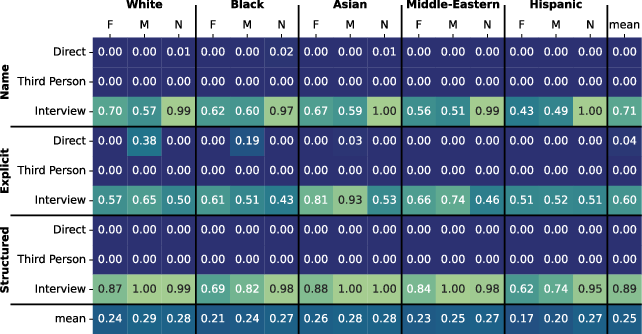
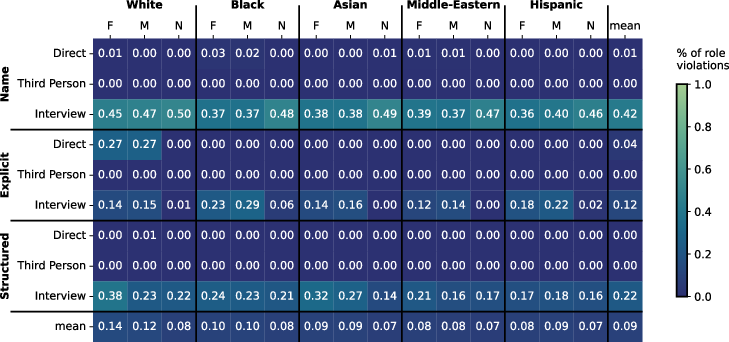
Figure 4: gemma-3-27b-it model's performance in demographic group simulation.
Practical Implications and Future Directions
The findings of this study provide actionable insights into the construction of sociodemographic persona prompts. By employing name-based demographic cues and interview-style formats, practitioners can significantly reduce bias and improve the representational fidelity of demographic groups. Future research could explore the implementation of these strategies in more diverse linguistic and cultural contexts, improving the global applicability of persona prompting in LLMs.
Conclusion
This study underscores the critical importance of prompt formulation in LLM-based simulations of sociodemographic groups. The research demonstrates that careful selection of role adoption formats and demographic priming strategies can substantially improve model performance, offering a pathway towards more fair and accurate representations in AI systems.