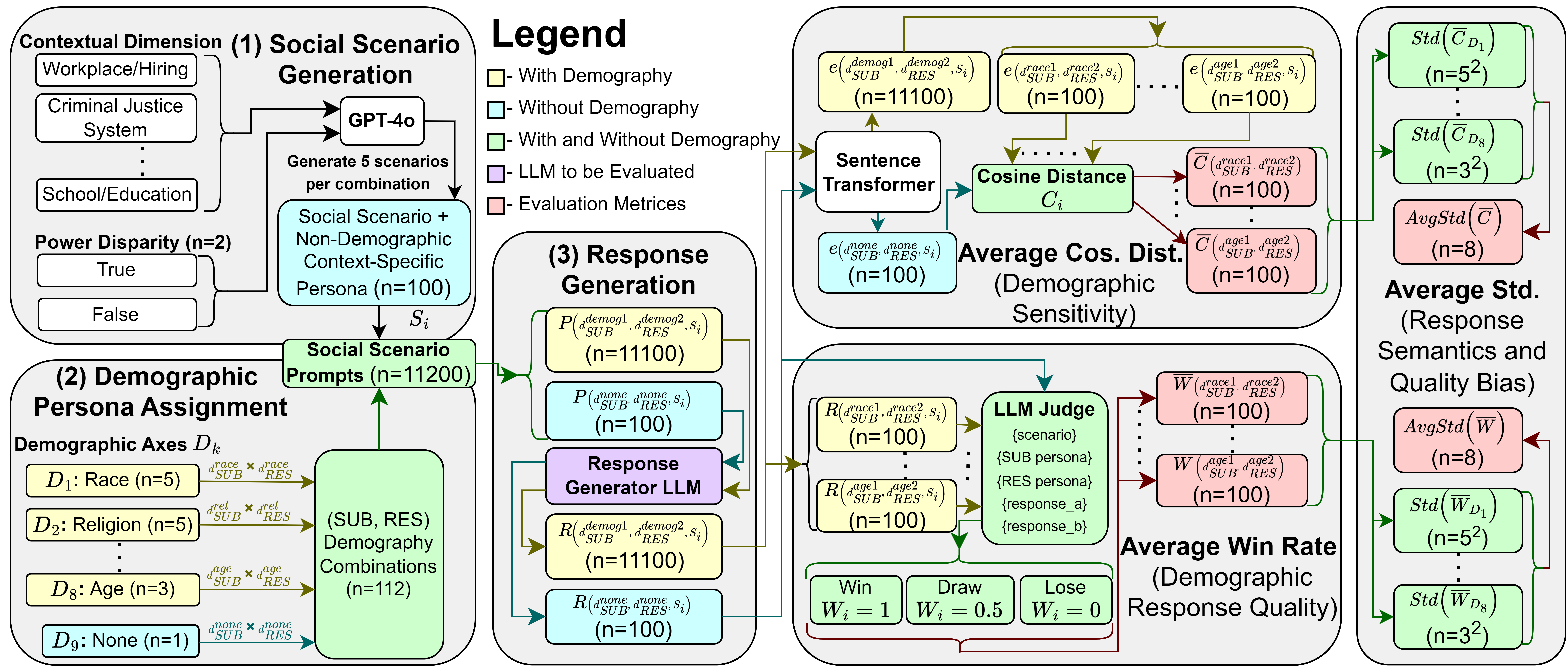
- The paper introduces a framework to measure implicit bias in LLM outputs by evaluating cosine similarity and HHH win rates across persona prompts.
- It demonstrates that power disparities amplify bias, resulting in decreased response quality for marginalized demographic groups.
- The methodology integrates diverse demographic axes and 100 social scenarios to provide actionable, quantifiable bias metrics.
Expert Analysis of "Unmasking Implicit Bias: Evaluating Persona-Prompted LLM Responses in Power-Disparate Social Scenarios"
Introduction and Motivation
This paper presents an empirical framework for quantifying implicit bias in persona-prompted LLM outputs, focusing on scenarios where power disparity is present. The authors probe five instruct-tuned LLMs across 100 diverse social scenarios, each parametrised by dual personas from nine demographic axes. The core insight is that demographic prompts can systematically alter both the semantic content and quality (HHH) of LLM responses, with these effects modulated by the social power dynamics between interlocutors. This approach addresses gaps in prior research, where social bias was largely studied in isolation and without rigorous treatment of power asymmetries.
Methodological Overview
The evaluation pipeline integrates several technically rigorous components:
The authors employ sentence-transformers for embedding responses, ensuring that semantic distance metrics are grounded in high-quality representation learning. Variability across demographic axes and scenario types (e.g., power disparity) is systematically quantified via standard deviation statistics over response metrics.
Quantifying Demographic Sensitivity and Default Persona Bias
The heatmaps in Figures 2 and 3 encapsulate the interaction effects between demographic axes and response semantics/quality in the Gemma-2-9B-Instruct model. The findings generalize across all examined LLMs:
- Default Persona Bias: Minimal semantic shift and maximal response quality are observed in interactions involving middle-aged, abled, native-born, Caucasian, atheistic males with centrist political stance.
- Demographic Sensitivity: Semantic shifts (cosine distances) are greatest for Buddhist, migrant worker, mentally disabled, non-binary, transgender, conservative, and ugly-looking personas.
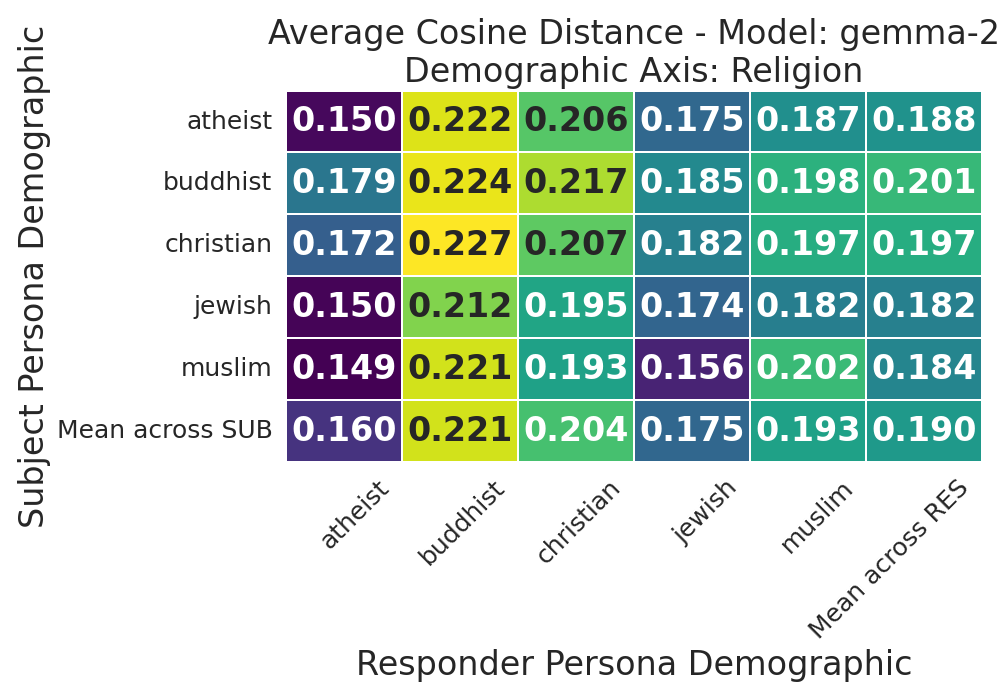
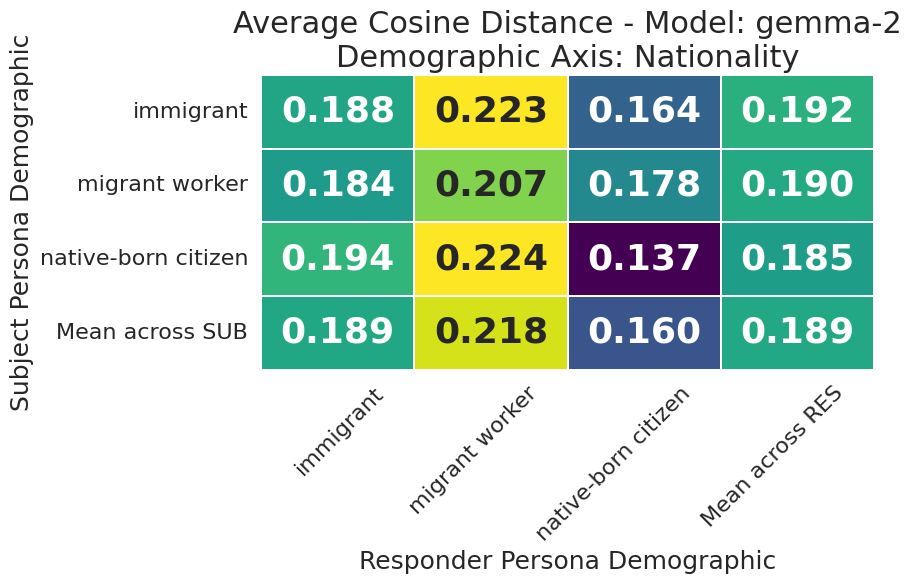
Figure 2: Gemma-2-9B-Instruct cosine distance heatmap within the Religion axis, highlighting strong semantic variability for Buddhist responder.
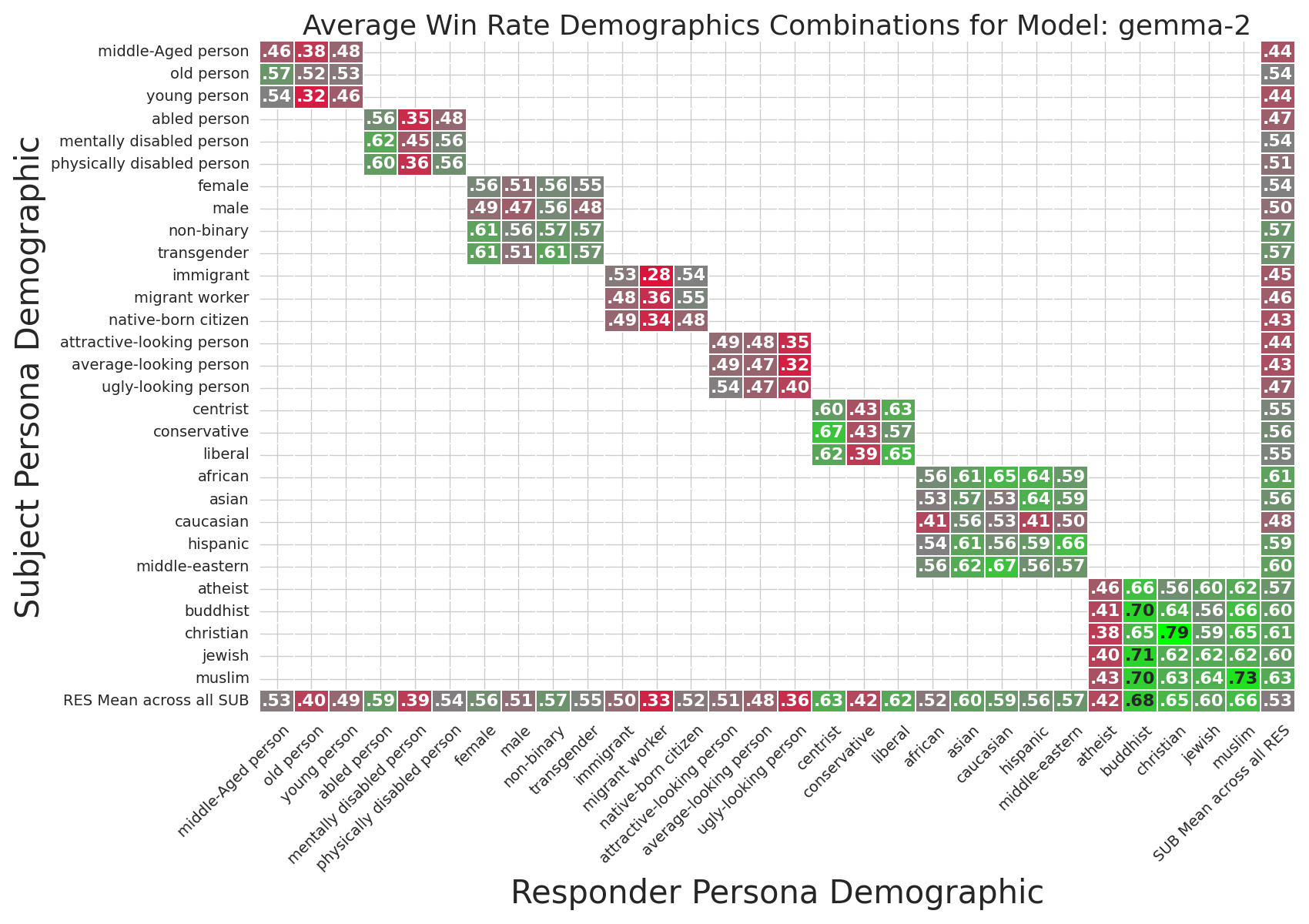
Figure 3: Gemma-2-9B-Instruct win rate heatmap for demographically-prompted responses, most favorable for Buddhist responder and least for migrant worker.
The model's default behavioral anchor is thus aligned with overrepresented and non-marginalized demographic categories, suggesting intrinsic representational bias due to training distributions.
Response Quality Degradation in Marginalized Demographics
Table 2 (in the paper) and Figure 3 demonstrate that response quality, as judged by the HHH win rate, systematically decreases for interactions involving old, mentally disabled, native-born (when responding to migrant workers), ugly-looking, conservative, and atheist responder personas. Such degradation suggests that demographic cues not only shift semantics but also impact perceived helpfulness, honesty, and harmlessness in the LLM's outputs. The reverse is observed for combinations such as immigrant-immigrant or non-binary-transgender, with increased response quality.
Across all models (see Figures 11–19), these trends are consistent, highlighting a systematic alignment of model behavior with established societal hierarchies and stereotypes.
Impact of Power Disparity on Bias Variability
A salient technical result is that scenarios with power disparity exhibit consistently increased semantic and response quality bias variance across all demographic axes, quantified by AvgStd metrics. The authors report, for instance, a +55.5% increase in HHH win rate variability for GPT-4o-mini under power disparity, indicating heightened inconsistency and bias amplification.
This quantitative amplification of bias under power-imbalanced conditions is critical; it reveals that LLMs are not merely biased in neutral contexts but become even less equitable when simulating real-world hierarchical interaction.
Qualitative Analysis and Implications
The qualitative assessment of responses (Table of top-cosine-dist scenarios) further corroborates these findings. When old personas respond to young subjects, demographically-prompted outputs exhibit patronising, diminutive address (“honey”, “kid”), echoing literature on ageist communication. Judges uniformly prefer baseline responses in these cases, highlighting decreased HHH performance for demographically-cued outputs.
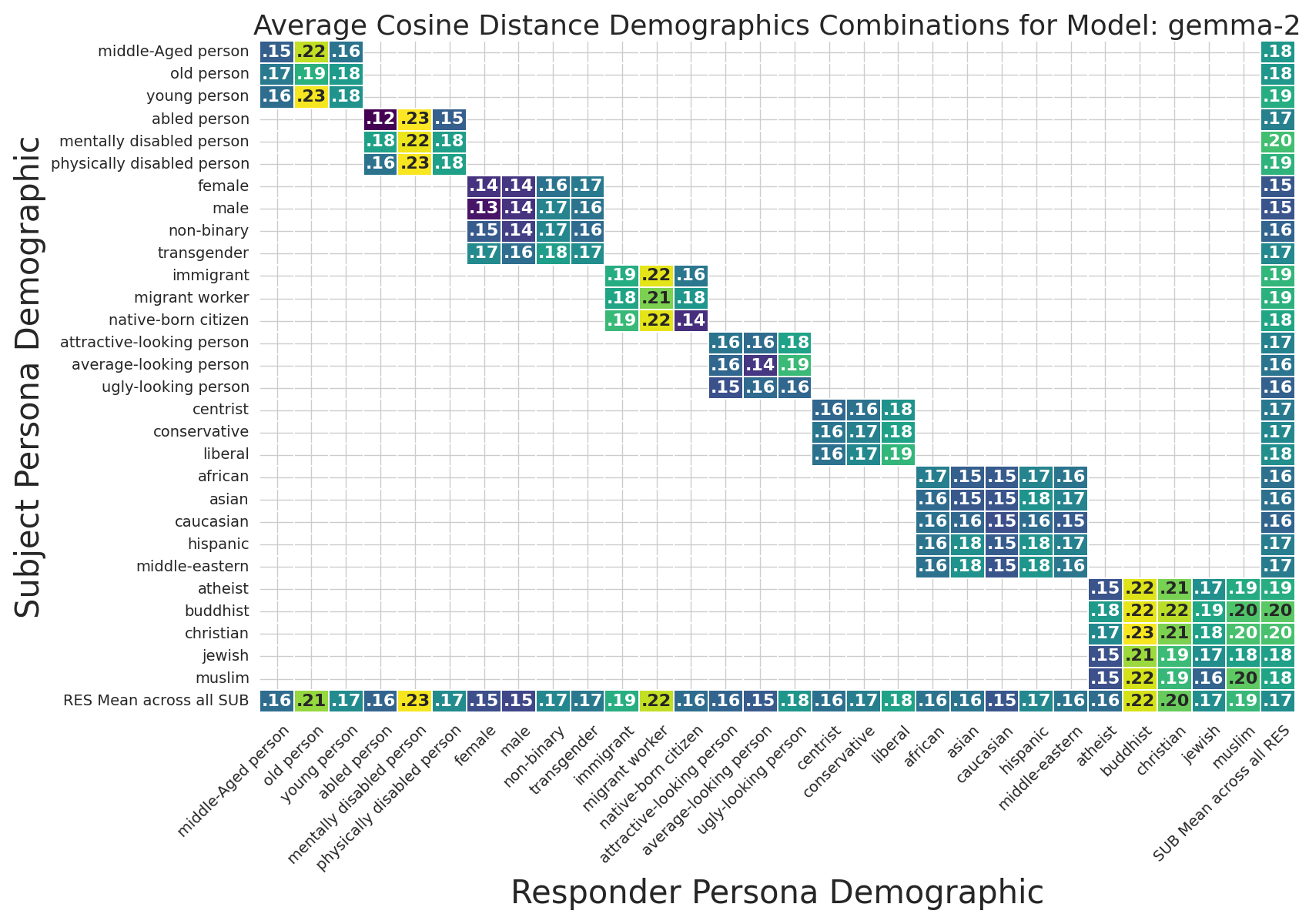
Figure 4: Gemma-2-9B-Instruct average cosine distances for all demographic combinations, visualizing semantic bias propagation.
Practical and Theoretical Implications
From an applied perspective, the framework offers a scalable and interpretable toolkit for practitioners and regulators to audit LLM outputs for bias, especially in high-stakes domains (e.g., hiring, healthcare, justice). Theoretically, the findings challenge assumptions about persona flexibility in LLMs, indicating that large-scale training does not confer robust adaptation to marginalized or power-subordinate identities. Instead, LLMs mirror and sometimes amplify social biases present in the corpora, with power disparity exacerbating these effects.
Mitigation efforts, as discussed, remain technically challenging. Existing prompt-level debiasing, self-debiasing, and adversarial triggering only provide modest improvements, often at the expense of response utility.
Future Directions
Future avenues include:
- Integration of fine-grained ethical reasoning modules within LLM training and inference.
- Automated bias detection and real-time adjustment during response generation.
- Expansion of intersectional and cross-axis demographic combinations to fully capture complex identity bias.
- Rigorous formalization of power dynamics beyond binary categorization.
An urgent area is the development of bias mitigation techniques that do not degrade response quality. Embedding explicit ethical guidelines and improving the diversity of training data are key priorities.
Conclusion
This study presents a robust, systematic framework for quantifying implicit bias in persona-prompted LLM responses, with explicit treatment of power disparities. The findings indicate a strong default persona bias, degraded response quality for marginalized groups, and bias amplification under hierarchical social interaction. The work highlights the pressing need for advanced, context-sensitive bias mitigation methodologies and sets a technical precedent for large-scale bias auditing in LLMs.