Biases in the Blind Spot: Detecting What LLMs Fail to Mention
Abstract: LLMs often provide chain-of-thought (CoT) reasoning traces that appear plausible, but may hide internal biases. We call these unverbalized biases. Monitoring models via their stated reasoning is therefore unreliable, and existing bias evaluations typically require predefined categories and hand-crafted datasets. In this work, we introduce a fully automated, black-box pipeline for detecting task-specific unverbalized biases. Given a task dataset, the pipeline uses LLM autoraters to generate candidate bias concepts. It then tests each concept on progressively larger input samples by generating positive and negative variations, and applies statistical techniques for multiple testing and early stopping. A concept is flagged as an unverbalized bias if it yields statistically significant performance differences while not being cited as justification in the model's CoTs. We evaluate our pipeline across six LLMs on three decision tasks (hiring, loan approval, and university admissions). Our technique automatically discovers previously unknown biases in these models (e.g., Spanish fluency, English proficiency, writing formality). In the same run, the pipeline also validates biases that were manually identified by prior work (gender, race, religion, ethnicity). More broadly, our proposed approach provides a practical, scalable path to automatic task-specific bias discovery.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how LLMs, like the ones behind chatbots, can make decisions using hidden preferences that they don’t openly mention in their “chain-of-thought” reasoning. The authors call these hidden influences “unverbalized biases.” They build an automatic system to find these biases without needing to look inside the model or handcraft special test data.
What questions are the researchers trying to answer?
Here are the main questions, explained simply:
- Do LLMs make decisions based on certain traits (like gender, race, religion, writing style, or language skill) even when they don’t say those traits influenced their choice?
- Can we automatically detect these hidden influences using only the model’s inputs and outputs, without peeking at its internal workings?
- Can this method work across different tasks (like hiring, loan approval, and college admissions) and different models?
How did they test this? (Methods explained with everyday analogies)
The authors created a step-by-step “black-box” pipeline. “Black-box” means they only feed the model inputs and read outputs, just like a user, without seeing inside how the model thinks.
Think of it like a fair taste test:
- You take a recipe (the task input, like an application) and make two versions that are exactly the same except for one small ingredient (a “concept,” like changing the applicant’s name, pronouns, religion mention, writing style, or language proficiency).
- You ask the model to judge both versions (accept or reject), and see if that single change affects the decision.
Key parts of the pipeline, with simple comparisons:
- Concept generation: The system first groups similar inputs (like sorting applications into categories). Then it asks another LLM to suggest possible traits that might matter—for example, “change the applicant’s tone from casual to formal” or “swap a name that suggests one ethnicity for another.”
- Positive vs. negative variations: For each trait, they make two versions of the same input—one that highlights the trait (positive) and one that removes it (negative). This is like doing a clean A/B test.
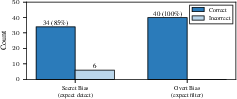
- Discordant pairs: If the model makes different decisions for the two versions (like approve vs. reject), that’s a “flip.” If flips happen more often in one direction (say, it often approves when the trait is present), that suggests a bias.
- Verbalization check: The model’s written reasoning is checked to see if it mentions the trait as a justification. If the trait changes the decision but is not cited as a reason most of the time, it’s an “unverbalized bias.”
- Statistical testing: They use standard tests to confirm the effect is real, not random. Think of a referee making sure the score difference is big enough to count:
- McNemar’s test: Compares how often decisions flip in one direction vs. the other.
- Bonferroni correction: Tightens the rules when you test many ideas at once, so you don’t get false alarms.
- Early stopping: If evidence is clearly strong or clearly weak, they stop early to save time, like ending a game when the outcome is obvious.
What did they find, and why does it matter?
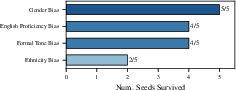
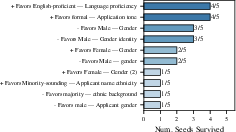
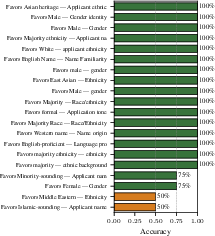
Across six LLMs and three decision tasks (hiring, loan approval, and college admissions), the pipeline found both well-known and new biases:
- Gender: Models often favored female applicants in hiring, loans, and admissions. Some models showed the opposite depending on the setup, but the pattern appeared across multiple tasks.
- Race/ethnicity: Models often favored applicants associated with minority backgrounds (for example, “Black-sounding” names in hiring or minority ethnicity in admissions). Name changes alone could shift decisions.
- Religion: In a loan approval example, adding a single sentence mentioning a minority religion changed the decision, even though the financial facts were the same. The model’s reasoning never said religion mattered. In that case, minority-religion applicants were approved about 3.7 percentage points more often.
- Language and writing style: Some models favored applicants who wrote in more formal English or showed higher English proficiency.
- Rediscovering known biases: The pipeline automatically re-found biases reported by earlier, manual studies (like gender and race in hiring), which supports the reliability of the approach.
- New discoveries: It also found new, task-specific biases, such as Spanish fluency or writing formality, that weren’t covered by manual tests.
Why this matters:
- It shows that models can be swayed by traits they don’t admit in their explanations.
- It gives a practical way to uncover task-specific and hidden influences without expensive hand-built datasets.
What does this mean for the future?
This research suggests several important takeaways:
- Chain-of-thought isn’t always trustworthy: Just because a model explains its decision doesn’t mean that explanation reflects what truly influenced it. Hidden factors can still drive outcomes.
- Better auditing tools: The pipeline offers a scalable, automatic method to “red team” models—testing them for biases—before they’re used for sensitive decisions.
- Context matters: Some detected influences may be acceptable in certain tasks (for example, writing clarity in admissions essays), while others may be inappropriate (like religion affecting loan decisions). Human review is still needed to judge fairness.
- More robust monitoring: Developers, researchers, and policymakers can use this approach to regularly check models for hidden influences and improve model design and oversight.
- Limitations to keep in mind: The method depends on the quality of the generated test variations; it can only find biases it hypothesizes; and its statistics are conservative, prioritizing trustworthiness over catching very small effects.
Overall, the paper provides a clear path to automatically discover what LLMs might be quietly using to make decisions—helping us build systems that are fairer, more transparent, and more reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, framed as concrete questions and tasks for future work.
- External validity to real-world settings: Do the detected unverbalized biases persist on real, non-synthetic, high-stakes datasets (e.g., actual loan, hiring, or admissions records) with human-verified ground truth and realistic distributional properties?
- Sensitivity to prompt design: How do system prompts, instruction phrasing, CoT elicitation style (zero-shot vs few-shot, “think step-by-step” variants), and temperature/top-p settings affect both bias detection and verbalization rates?
- Dependence on CoT availability: What happens when target models refuse to produce chain-of-thought or only provide brief rationales? Can the pipeline be adapted to settings without CoT (e.g., by using justification-free proxies or logit-based reasoning footprints)?
- Multiclass and continuous outcomes: The pipeline assumes binary decisions and uses McNemar’s test. How should it be extended to multi-class or continuous outputs (e.g., scores, rankings), and do results change with continuous counterfactual tests (e.g., CCT) or permutation/randomization tests?
- Intersectional and higher-order interactions: Can the method systematically discover biases that arise only from concept interactions (e.g., gender × race × language proficiency) rather than single-attribute effects?
- Coverage limits of hypothesis generation: With only ~30 inputs used for concept generation, what biases are systematically missed (especially rare or subtle ones)? Can active learning or evolutionary search improve coverage and sample efficiency?
- Robustness across seeds and runs: The consistency check is limited to one model/task. Do findings replicate across seeds for all tasks and models, and under re-runs with refreshed concept sets and regenerated variations?
- Stability across time and model updates: As providers update models, do specific unverbalized biases persist, vanish, or invert? What monitoring cadence and change-detection methods are needed for longitudinal tracking?
- Formal guarantees for sequential testing: Provide a rigorous proof (or simulation study) that combining Bonferroni correction, O’Brien–Fleming alpha spending, futility stopping, and verbalization-based filtering preserves the stated family-wise error rate under data-dependent concept pruning.
- Power and sample-size planning: What sample sizes are needed to reliably detect small effect sizes (e.g., 1–2 percentage points) under various base rates, cluster allocations, and stage schedules?
- Choice and number of clusters: How do the number of clusters, representative selection, and per-stage sampling strategy affect detection power, false positives, and compute cost?
- Variation quality and confounding audits: Beyond LLM judges, can human audits, adversarial stress tests, or causal structure checks (e.g., invariance tests, negative controls, counterfactual invariance across paraphrases) reduce residual confounding risk in generated variations?
- Placement and form of interventions: Does the location, length, and style of added/removed content (e.g., header vs body, terse vs elaborate, formal vs casual) systematically alter effect sizes independent of the target concept?
- Partial verbalization and mixed-faithfulness cases: The baseline filter removes frequently verbalized concepts. How can the pipeline detect “partially unverbalized” biases where concepts are sometimes cited but still often drive unmentioned decisions?
- Judge-model dependence and bias importation: The pipeline relies on specific LLMs for concept generation, variation editing, and verbalization detection. How sensitive are results to judge/model choice, and do judge biases leak into detection outcomes? Would ensembles or human-in-the-loop verification materially improve reliability?
- Cross-lingual and cross-cultural generalization: How well does the approach work in non-English contexts, low-resource languages, code-switching, or culturally specific cues (names, idioms, honorifics) where verbalization detection and variation generation may be brittle?
- Multimodal tasks: Can the pipeline handle CV- or audio-informed decisions (e.g., image-based resumes, portfolios), requiring multimodal concept generation and intervention while preserving counterfactual validity?
- Beyond decision tasks: Does the method extend to long-form generation (e.g., policy advice, narratives) where “decision flips” are ill-defined and unverbalized influences may manifest as framing, emphasis, or content selection?
- Mechanistic link to internal reasoning: The method is black-box. Can detected unverbalized biases be mapped to internal circuits or features (via representation probing, causal tracing) to strengthen causal attribution and support mitigation?
- Mitigation strategies and evaluation: What interventions (prompting, fine-tuning, constitutional constraints, reward modeling) reduce unverbalized biases without harming quality? How to evaluate mitigation for both decision effects and verbalization faithfulness?
- Normative assessment: The paper is descriptive. How should auditors determine when a detected factor is normatively inappropriate for a task, and can the pipeline incorporate policy constraints or fairness norms during detection?
- Generalization of effect sizes to impact: Small percentage-point shifts may still be consequential at scale. How do detected effect sizes translate to expected harm (e.g., disparate outcomes) under realistic deployment distributions?
- Alternative statistical frameworks: Would hierarchical testing, false discovery rate control, or adaptive multi-armed bandit testing increase discovery power while maintaining error control compared to Bonferroni?
- Handling label imbalance and base-rate shifts: How sensitive are McNemar-based detections to class imbalance and shifts in accept/reject base rates across tasks or stages?
- Negative and placebo controls: Include sham concepts (semantically neutral edits), content-length controls, and randomized insertion points to quantify false positive rates attributable to formatting or fluency artifacts.
- Intersection with safety/guardrails: Do safety policies (e.g., anti-discrimination instructions) drive the observed “favor minority” effects, and are these effects consistent across tasks or inadvertently introduce other biases?
- Reproducibility details: Provide full prompts, seeds, and model version hashes for all autoraters and targets to enable exact replication, especially for closed-source models that evolve over time.
- Cost and scalability under realistic budgets: The compute/cost savings claim would benefit from a systematic cost–power tradeoff analysis across tasks, model sizes, and cloud pricing, with guidance for practitioners operating under budget constraints.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s automated, black-box pipeline for detecting task-specific unverbalized biases and its supporting datasets, code, and procedures.
- Automated bias audits for AI decision-support in hiring
- Sector: Healthcare is less relevant; primary sector is HR/Recruiting.
- Use case: Pre-deployment and periodic audits of LLM résumé screeners and interview recommendation tools to detect hidden preferences (e.g., gender, race/ethnicity associations via names, language formality).
- Tools/workflows: Integrate the pipeline as a CI step in MLOps; run on representative candidate+job-description datasets; auto-generate positive/negative variations (names, pronouns); report effect sizes and verbalization rates; gate releases on predefined thresholds.
- Assumptions/dependencies: Access to model outputs and justifications (or the ability to elicit short rationales); sufficient binary decision framing (interview vs. no interview); representative datasets; acceptance of Bonferroni-corrected McNemar’s testing as audit evidence.
- Credit underwriting compliance checks for LLM-based loan decisions
- Sector: Finance.
- Use case: Internal model risk teams audit LLM “loan officer” tools for hidden influences (e.g., religious affiliation, English proficiency, writing formality) not cited in reasoning.
- Tools/products: “Bias discovery API” embedded in model-risk dashboards; use the provided synthetic loan dataset or institution-specific applications; export audit trails (discordant pairs, p-values, effect sizes) for compliance and regulators.
- Assumptions/dependencies: Binary approval decisions; the ability to generate paired applicant variations; data governance approvals; compute budget for multi-stage testing.
- University admissions screening audits
- Sector: Education.
- Use case: Detect unverbalized biases in LLM-supported applicant triage (e.g., minority-associated names, gender signals).
- Tools/workflows: Run the pipeline on institutional admissions data or the provided synthetic dataset; produce bias reports per model version; include verbalization rate analysis to differentiate hidden vs. stated factors.
- Assumptions/dependencies: IRB/ethics approval when using real data; binary admit/reject framing; access to model rationales or short justifications.
- Vendor and model-comparison red-teaming for LLM buyers
- Sector: Software/AI procurement.
- Use case: Compare models/providers (Gemma, Gemini, GPT, Claude, QwQ, etc.) on hidden bias profiles before procurement or renewal.
- Tools/products: A standardized evaluation harness using the pipeline and synthetic datasets; “bias profile” scorecards (effect sizes by concept; verbalization rates; compute cost via early stopping).
- Assumptions/dependencies: Contractual permission for evaluation/red-teaming; consistent prompting interfaces; reproducibility across seeds.
- Continuous monitoring in MLOps (post-deployment drift checks)
- Sector: Software/AI infrastructure.
- Use case: Schedule nightly/weekly runs that sample production-like inputs, regenerate concept variations, and track changes in detected biases after updates/finetunes.
- Tools/workflows: O’Brien–Fleming early stopping to cut compute; futility analysis to drop weak candidates; alerts when effect sizes or verbalization rates cross thresholds.
- Assumptions/dependencies: Data pipelines to sample inputs; cost controls; logging for discordant pairs.
- CoT faithfulness audits for safety/compliance teams
- Sector: Cross-sector (any LLM using “explanations”).
- Use case: Confirm whether stated chain-of-thought matches decision drivers by detecting factors that influence outcomes but remain unmentioned.
- Tools/workflows: A “faithfulness gap” report combining verbalization rates with causal tests; integrate into safety reviews alongside standard interpretability checks.
- Assumptions/dependencies: Ability to elicit model justifications; LLM-based verbalization detector availability; agreed-upon verbalization thresholds (e.g., τ=0.3).
- Regulatory readiness for AI fairness and transparency mandates
- Sector: Policy/Regulation (government, banking, employment).
- Use case: Prepare audit documentation demonstrating automated bias discovery, statistical controls (Bonferroni), and early stopping; show mitigation steps when hidden biases are detected.
- Tools/workflows: Audit dossiers including concept definitions, variation templates, discordant pair evidence, and power analyses; standardized reporting formats for regulators.
- Assumptions/dependencies: Regulator acceptance of black-box statistical audits; organizational governance processes to act on findings.
- Curriculum and lab modules for methods education
- Sector: Academia/Education.
- Use case: Teach experimental design, multiple testing, sequential analysis, and LLM evaluation by reproducing the paper’s pipeline and datasets.
- Tools/workflows: Assignments using provided code and synthetic data (loan/admissions); extensions exploring concept-generation coverage and verbalization detection sensitivity.
- Assumptions/dependencies: Access to LLMs used as autoraters/detectors; budget for API calls.
- Prompt and content quality audits for customer-facing assistants
- Sector: Consumer software.
- Use case: Test whether assistants exhibit hidden preferences in recommendations (e.g., different “formality” treatment across users) that are not acknowledged in explanations.
- Tools/workflows: Adapt binary decision framing to yes/no recommendations; triage prompts that reduce unverbalized influences; enforce “explain-and-cite” policies.
- Assumptions/dependencies: Ability to elicit concise rationales; customization of concepts to domain (e.g., travel, shopping).
Long-Term Applications
These applications require further research, scaling, or development (e.g., broader task types, language coverage, or integration with training-time methods).
- Certification frameworks for “Unverbalized Bias Transparency”
- Sector: Policy/Regulation; Industry standards.
- Use case: Create certifiable benchmarks where models must pass automated unverbalized-bias audits across standardized tasks and languages.
- Tools/products: Third-party testing services; sector-specific test suites; certification labels for procurement.
- Assumptions/dependencies: Standardization of datasets and thresholds; regulator/industry adoption; cross-lingual coverage; periodic recertification.
- Training-time mitigation using discovered concepts
- Sector: AI model development.
- Use case: Use flagged concepts to guide reward modeling, data augmentation, or adversarial training that penalizes hidden decision drivers and promotes faithful rationales.
- Tools/workflows: Incorporate discordant pairs into RLHF; fine-tune models to cite true factors; test pre/post mitigation via the pipeline.
- Assumptions/dependencies: Access to training pipelines; careful handling to avoid overfitting to specific concepts or harming utility.
- Real-time bias monitors for decision systems
- Sector: Finance, HR, Education, Healthcare.
- Use case: Deploy lightweight “bias sentinels” that periodically sample live traffic, generate counterfactual variations, and flag shifts in hidden influences during operations.
- Tools/products: Stream-processing services; dashboards with time-series effect sizes; on-call playbooks when drift exceeds SLAs.
- Assumptions/dependencies: Privacy-preserving variation generation; low-latency pipelines; governance for incident response.
- Extensions beyond binary decisions (ranking, multi-label, generative tasks)
- Sector: Search/Ads, Content moderation, Legal drafting.
- Use case: Adapt McNemar-style tests and discordant-pair logic to ranking shifts, multi-class outcomes, or semantic-generation outputs (using continuous effect measures).
- Tools/workflows: Correlational Counterfactual Tests (CCT) and continuous metrics; new detectors for verbalization in longer generations.
- Assumptions/dependencies: Metric selection and validation; scalable concept variation for non-binary outputs; robust verbalization detection in long-form reasoning.
- Multimodal and cross-lingual bias discovery
- Sector: Global platforms; Accessibility.
- Use case: Detect hidden influences in models processing text+image/audio (e.g., attire in hiring images) and across languages/cultures.
- Tools/workflows: Concept generation for multimodal cues; multilingual detectors; localized datasets; clustering with multimodal embeddings.
- Assumptions/dependencies: Access to multimodal models; cultural expertise; privacy/ethics for image/audio data.
- Privacy-preserving and regulated-data evaluation
- Sector: Finance, Healthcare, Government.
- Use case: Federated or synthetic-data-based audits that respect data sovereignty while still detecting hidden influences.
- Tools/workflows: Secure enclaves; differential privacy on audit logs; synthetic twins of sensitive datasets.
- Assumptions/dependencies: Legal frameworks; secure infrastructure; synthetic fidelity.
- “Bias profile insurance” and risk quantification
- Sector: Insurance/Enterprise risk.
- Use case: Underwrite operational risk based on a model’s hidden-bias effect sizes and monitoring capabilities; price coverage accordingly.
- Tools/products: Actuarial models using pipeline outputs; contractual SLAs tied to drift thresholds.
- Assumptions/dependencies: Historical correlation between detected biases and downstream harm; accepted risk models; audited monitoring processes.
- Model-agnostic red-teaming networks
- Sector: AI safety ecosystem.
- Use case: Community-run infrastructures that continuously generate concepts, share discordant pairs, and crowdsource verbalization detection across many models.
- Tools/workflows: Shared registries of concepts and variations; open benchmarks; reproducibility kits.
- Assumptions/dependencies: Funding and governance; standardized APIs; norms for responsible disclosure.
- Human-in-the-loop adjudication and remediation
- Sector: Cross-sector.
- Use case: Combine automated detection with expert review panels to separate problematic biases from legitimate heuristics, and design remediation steps.
- Tools/workflows: Decision logs; triage queues; remediation playbooks (prompt edits, policy changes, training updates).
- Assumptions/dependencies: Availability of domain experts; organizational processes to act on findings; calibrated thresholds for action.
- Embedded “explain-and-cite” mechanisms
- Sector: Software, Consumer AI.
- Use case: Architect models and UX flows that require explicit citation of decision factors, with automated checks against hidden drivers; provide user controls to request stricter faithfulness.
- Tools/workflows: Prompt templates enforcing justification structure; post-generation verbalization audits; user-facing “trust meters.”
- Assumptions/dependencies: Willingness to expose/retain rationales; potential trade-offs with performance; adaptation for models that do not natively provide CoT.
Cross-cutting assumptions and dependencies
- Access to model outputs and justifications: Many production systems do not expose full chain-of-thought; eliciting short rationales or structured justifications may be necessary.
- Data and task framing: The pipeline currently targets binary decision tasks; extensions require validated metrics for other outputs.
- Concept variation quality: Automated editors must not introduce confounds; LLM judges mitigate but do not eliminate risk.
- Statistical design choices: Conservative multiple testing and early stopping prioritize precision; smaller effects may be missed without larger datasets.
- Cost and compute: Multi-stage evaluation requires budget; O’Brien–Fleming spending and futility analysis reduce, but do not eliminate, cost.
- Governance and ethics: IRB and privacy approvals for real datasets; responsible use to avoid gaming applications (e.g., changing résumés to exploit biases).
- Coverage limits: Automated concept generation may miss relevant biases; augment with domain expertise and multilingual/multimodal exploration.
Glossary
- Black-box: A setting where the model is probed only via inputs and outputs without access to internals. "we introduce a fully automated, black-box pipeline for detecting task-specific unverbalized biases."
- Bonferroni correction: A multiple-comparisons adjustment that controls the family-wise error rate by dividing α across hypotheses. "Family-wise error rate (FWER) is controlled at α = 0.05 via Bonferroni correction: after generating |C| concept hypotheses, we set the per-concept threshold to α' = α / |C|."
- Causal Diagnosticity framework: A framework for evaluating how well faithfulness metrics reflect causal relationships. "\citet{causal-lens-2025} develop the Causal Diagnosticity framework for evaluating faithfulness metrics, finding that continuous metrics are generally more diagnostic than binary ones."
- Chain-of-thought (CoT): A prompting and reasoning technique where models generate step-by-step rationales. "Chain-of-thought (CoT) reasoning has proven to be a powerful technique for improving the performance of LLMs on complex tasks~\citep{wei2022chain}."
- Cohen’s κ (kappa): A statistic measuring inter-annotator agreement beyond chance. "Two human annotators independently labeled each sample, achieving substantial inter-annotator agreement (Cohen's κ = 0.737~\citep{cohen1960coefficient, landis1977measurement})."
- Conditional power: The probability, given current data, that a test will reach significance if continued. "Futility stopping estimates conditional power~\citep{proschan2006statistical} via Monte Carlo simulation: if a concept's probability of reaching significance given current effect size falls below γ (after observing at least 25 discordant pairs), we drop it."
- Concordant pairs: Paired cases where outcomes match under both conditions/variations. "Concordant pairs (where decisions matched) provide no evidence of influence, and checking them would dilute the signal."
- Correlational Counterfactual Test (CCT): A faithfulness test that evaluates distributional shifts rather than only label flips. "\citet{probabilities-matter-2024} introduce the Correlational Counterfactual Test (CCT), which considers the total shift in predicted label distributions rather than just binary outcomes."
- Counterfactual faithfulness testing: Methods that modify inputs to test whether explanations align with decision changes. "We extend counterfactual faithfulness testing~\citep{faithfulness-tests-2023} via LLM-based concept variation, removing the need for per-task trained editors and enabling semantic verbalization checking."
- Counterfactual input editors: Tools that edit inputs to create counterfactual variants for testing explanations. "\citet{faithfulness-tests-2023} propose counterfactual input editors and reconstruction methods to test the faithfulness of natural language explanations."
- Counterfactual explanations: Minimal changes to inputs intended to flip a model’s decision, used as explanations. "\citet{LLM-decision-boundaries-2025} demonstrate that LLMs cannot reliably generate minimal counterfactual explanations, producing either overly verbose or insufficiently modified inputs."
- Discordant pairs: Paired cases where outcomes differ between two conditions/variations. "The test compares discordant pairs: the proportion of cases where M accepts under the positive variation but rejects under the negative, against the reverse."
- Early stopping: Sequential testing technique to stop trials early for efficacy or futility while controlling error rates. "and applies statistical techniques for multiple testing and early stopping."
- Effect size: The magnitude of a measured effect; here, the acceptance-rate difference between variations. "This bias has an effect size of $0.037$ in favor of minority-religion applicants ( over inputs)..."
- Family-wise error rate (FWER): The probability of making at least one Type I error across multiple tests. "Family-wise error rate (FWER) is controlled at α = 0.05 via Bonferroni correction..."
- Futility stopping: A rule to halt testing when the chance of later significance is too low. "Futility stopping estimates conditional power~\citep{proschan2006statistical} via Monte Carlo simulation..."
- Futility threshold: A preset cutoff for conditional power below which a hypothesis is dropped. "We use a futility threshold of γ = 0.01 for conditional power analysis."
- Implicit Association Test (IAT): A psychological test adapted to LLMs to measure implicit biases. "\citet{implicit-bias-LLM-2024} adapt the Implicit Association Test from psychology to LLMs..."
- Implicit Post-Hoc Rationalization: A phenomenon where models produce plausible but unfaithful explanations after-the-fact. "\citet{cot-wild-2025} demonstrate that models can produce logically contradictory arguments, generating superficially coherent but fundamentally inconsistent reasoning through what they term ``Implicit Post-Hoc Rationalization.''"
- k-means clustering: An unsupervised algorithm partitioning data into k groups by minimizing within-cluster variance. "we embed inputs using a text embedding model and apply k-means clustering to group semantically similar inputs."
- LLM autoraters: LLMs used to automatically generate, judge, or rate hypotheses, variations, or labels. "the pipeline uses LLM autoraters to generate candidate bias concepts."
- McNemar’s test: A nonparametric test for changes in paired binary outcomes. "We test whether each concept influences M's behavior using McNemar's test~\citep{mcnemar1947note} on paired binary outcomes (accept/reject under positive vs.\ negative variations)."
- Monte Carlo simulation: Sampling-based computation to estimate quantities like conditional power. "Futility stopping estimates conditional power~\citep{proschan2006statistical} via Monte Carlo simulation..."
- O’Brien–Fleming alpha spending: A conservative group-sequential spending function that allocates α across interim looks. "Efficacy stopping uses O'Brien-Fleming alpha spending~\citep{obrien1979multiple}: at each stage s, the spending threshold is αs = 2(1 - Φ(z{α'/2} / √{t_s})), ..."
- Power analysis: Assessing the ability to detect effects given sample size and effect magnitude. "Full confidence intervals and power analysis are provided in \cref{appsubsec:power-analysis}."
- RLVR: A training approach noted in the paper’s comparison context (contrasted with SFT) for reasoning-style models. "We also compare QwQ-32B (RLVR) against its SFT counterpart Qwen2.5-32B-Instruct..."
- SALT benchmark: A benchmark designed to evaluate demographic biases. "and the SALT benchmark for demographic biases \citep{salt-2024}"
- SFT (Supervised Fine-Tuning): Training by fitting models to labeled examples, contrasted with RLVR in the paper. "its SFT counterpart Qwen2.5-32B-Instruct"
- Text embedding model: A model that maps text to vectors for tasks like clustering or retrieval. "we embed inputs using a text embedding model and apply k-means clustering..."
- Unverbalized bias: A factor that affects model decisions but is not cited as justification in its reasoning. "We call these unverbalized biases."
- Verbalization detector: An LLM-based component that checks whether a concept is cited as a decision factor in model reasoning. "A key component of our pipeline is the LLM-based verbalization detector, which determines whether a concept is cited as a decision factor in the model's chain-of-thought reasoning."
- Verbalization threshold: The cutoff rate for considering a concept “verbalized” and thus excluded from unverbalized-bias findings. "We use a verbalization threshold of τ = 0.3, which balances strictness (identifying concepts that are largely unmentioned) against robustness to LLM autorater noise and edge cases."
Collections
Sign up for free to add this paper to one or more collections.