- The paper demonstrates that persona variables account for less than 10% of annotation variance using mixed-effect regression models.
- The study shows that persona prompting yields modest improvements in LLM predictions, especially in datasets with low variability.
- The authors recommend cautious use of persona prompting and advocate for improved dataset designs to better capture diverse perspectives.
Quantifying the Persona Effect in LLM Simulations
Introduction
The paper "Quantifying the Persona Effect in LLM Simulations" presents an in-depth exploration of how persona variables influence the capability of LLMs in simulating human language use and behavior. This is particularly relevant in subjective NLP tasks where annotations often reflect low inter-annotator agreement due to their inherent subjectivity.
Methodology
The authors utilize a mixed-effect linear regression model to assess the explanatory power of persona variables on annotation variance across various datasets. The model segregates the variance attributable to persona variables from the inherent variability in the text samples annotated, leveraging a random intercept to control for text effects.
Findings on Variance Explanation
The study reveals that persona variables explain less than 10% of the variance in human annotations across a variety of NLP datasets, a finding underscored by conditional and marginal R-squared values. This contrasts with a higher R-squared value in contexts like the ANES survey dataset, where more predictable behavioral patterns are observed.
Impact of Persona Prompting
Persona prompting, as explored in this study, involves prepending text samples with details about persona variables in a zero-shot LLM setting. While persona prompting demonstrates modest improvements across some models and tasks, these gains are not consistent and remain limited. Most notably, persona prompting seems beneficial in contexts where annotator disagreements, though frequent, are narrowly ranged.
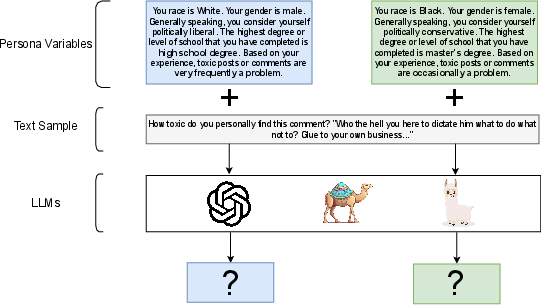
Figure 1: Illustration of persona prompting used to investigate LLMs' capacity to simulate diverse perspectives.
Sample Types and Persona Prompting Utility
The efficacy of persona prompting was particularly highlighted in datasets characterized by high entropy yet low standard deviation in annotations. Here, LLMs could adjust predictions to align more closely with individual personas. The study's detailed analysis suggests that improvements from persona prompting are most pronounced in samples exhibiting frequent disagreements among annotators within confined ranges.
Controlled Text Randomness and Persona Utility
Using the ANES dataset to control for text randomness, the study investigates LLMs’ abilities to simulate personas when persona utilities vary. The results indicate a near-linear correlation between the extent to which persona factors influence human responses and LLM predictions. Larger models, fine-tuned with persona prompting, captured up to 81% of the variance found in human responses for high-utility scenarios.
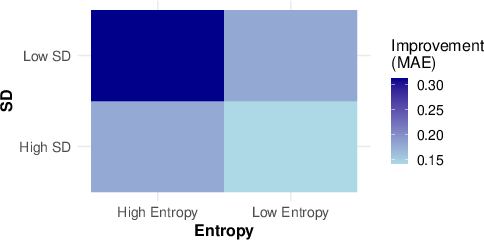
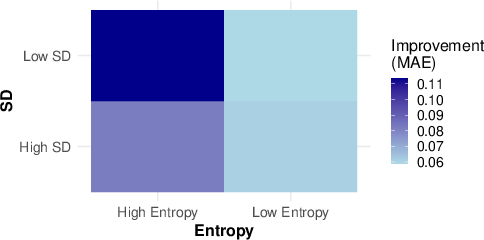
Figure 2: Mean improvement in MAE with persona prompting across models and datasets with varying annotation entropy and standard deviation.
Implications and Recommendations
The findings suggest that while persona prompting can marginally enhance LLM performance, it is constrained by the limited variance that persona variables explain in most existing datasets. Consequently, the authors recommend caution in employing LLMs for simulating diverse perspectives without validation. They also advocate for more strategic dataset design to advance the incorporation of nuanced persona variables in future research endeavors.
Conclusion
This paper provides a nuanced understanding of the limitations and potential of persona prompting in LLM simulations. It emphasizes the need for more complex and comprehensive persona information to effectively utilize LLMs in capturing diverse perspectives across NLP tasks. The insights from this study pave the way for future research in refining LLM simulations through enhanced dataset designs and more sophisticated prompting methodologies.