Do Persona-Infused LLMs Affect Performance in a Strategic Reasoning Game?
Abstract: Although persona prompting in LLMs appears to trigger different styles of generated text, it is unclear whether these translate into measurable behavioral differences, much less whether they affect decision-making in an adversarial strategic environment that we provide as open-source. We investigate the impact of persona prompting on strategic performance in PERIL, a world-domination board game. Specifically, we compare the effectiveness of persona-derived heuristic strategies to those chosen manually. Our findings reveal that certain personas associated with strategic thinking improve game performance, but only when a mediator is used to translate personas into heuristic values. We introduce this mediator as a structured translation process, inspired by exploratory factor analysis, that maps LLM-generated inventory responses into heuristics. Results indicate our method enhances heuristic reliability and face validity compared to directly inferred heuristics, allowing us to better study the effect of persona types on decision making. These insights advance our understanding of how persona prompting influences LLM-based decision-making and propose a heuristic generation method that applies psychometric principles to LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question: If you tell an AI to “act like” a certain type of person (a persona), does that actually change how well it makes decisions in a strategy game? The authors test this in PERIL, a Risk-like board game where players try to conquer the world. They find that personas can help—but only when the AI’s personality is translated into clear, consistent decision rules using a special questionnaire.
What were the researchers trying to find out?
They focused on two big questions:
- Does giving an AI a persona that sounds strategic (like a military officer or a professional strategist) help it win more in a strategy game?
- Can a personality questionnaire (a mediator) turn those personas into better, more trustworthy “rules of thumb” for making game decisions?
How did they do the study?
Think of this like teaching an AI to play a board game using simple, explainable habits:
- PERIL (the game): It’s similar to Risk. Players place armies on a map, attack neighboring regions, and move troops around. The goal is world domination.
- Heuristics (rules of thumb): These are simple decision rules the AI uses, like:
- “Attack only if you have twice as many armies.”
- “Place units next to enemy borders.”
- “Move troops to regions that are more connected.”
- Personas: The researchers started with a huge set of personality descriptions (like “a retired intelligence officer” or “a competitive college athlete”). They picked 50 diverse personas that sounded very different from each other.
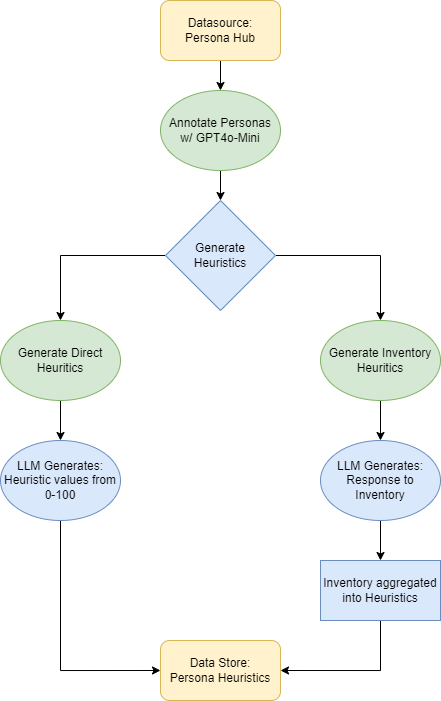
- Two ways to turn personas into decision rules: 1) Direct Heuristics (DH): Tell the AI its persona and ask it to assign importance scores to each rule. This is like saying, “You’re a daring general—now choose how much you care about each rule.” 2) Personality Inventory (PI): Use a short questionnaire (inspired by psychological inventories) that asks “I prefer to…” or “I’m likely to…” statements. The AI, acting as the persona, answers these. Those answers get converted into rule weights. This is the “mediator” that translates personality into consistent decision-making.
- Tournaments and scoring: They ran thousands of two-player matches between AIs with different personas and measured skill using a ranking system similar to chess ratings (TrueSkill).
What did they find, and why does it matter?
- Personas helped, but only with the mediator:
- When the AI used the questionnaire (PI), personas tied to strategic thinking—like “geopolitical strategist” or “retired intelligence officer”—performed better.
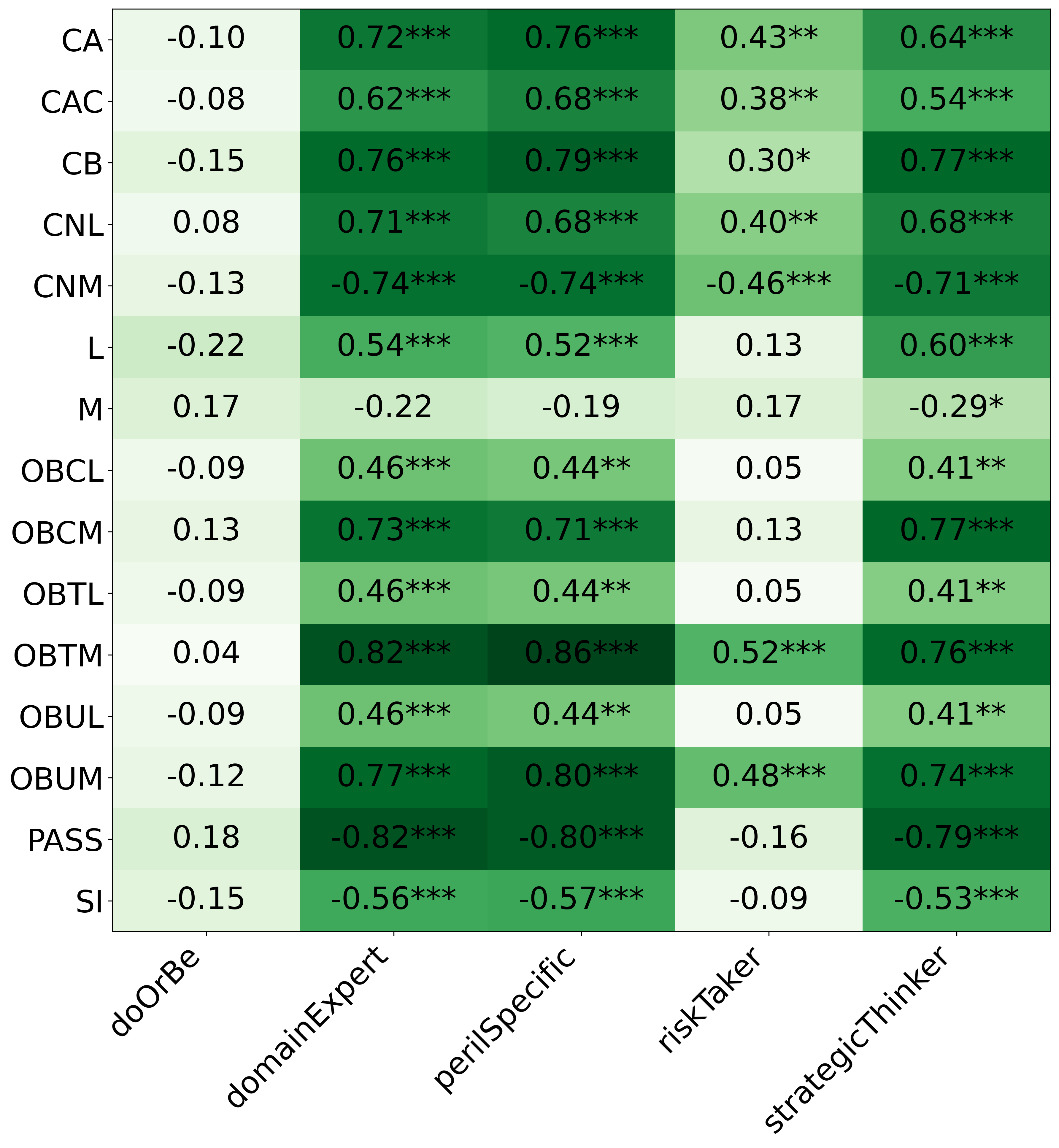
- When the AI directly picked rule weights (DH) without the questionnaire, the results didn’t reliably match the persona. Similar-sounding personas often ended up with similar rules, and “opposite” rules weren’t consistently treated as opposites.
- The questionnaire made behaviors more meaningful:
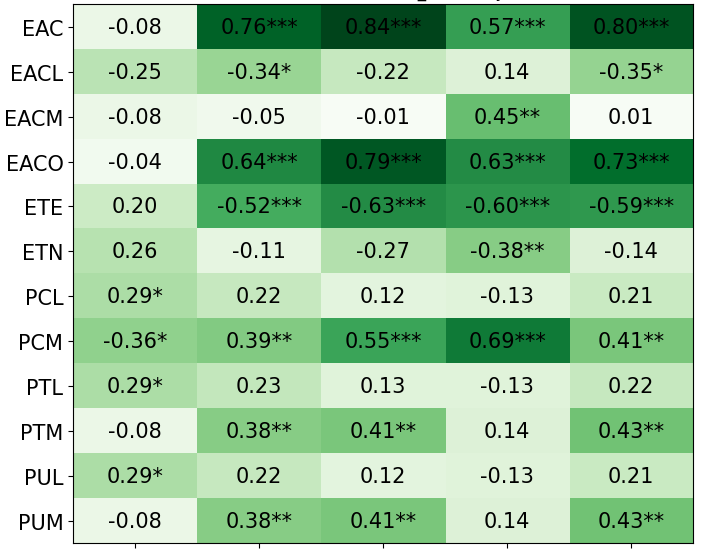
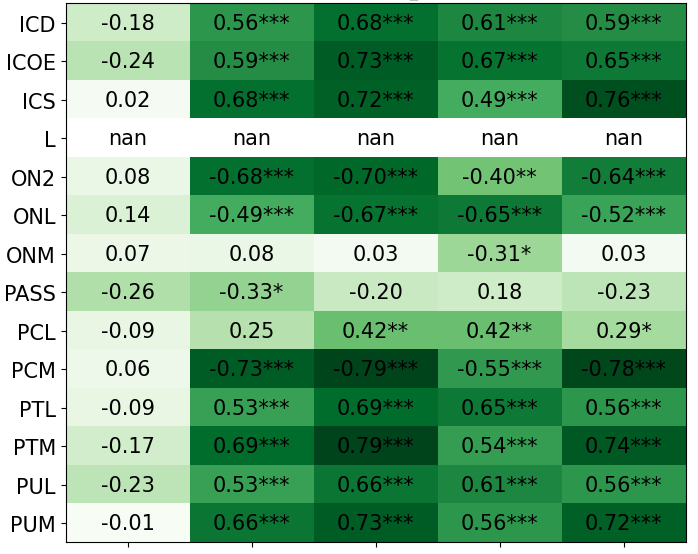
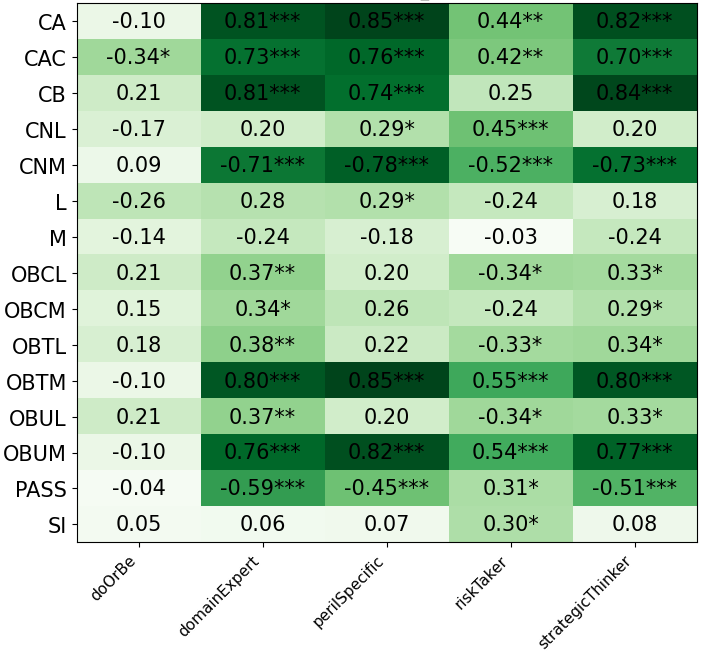
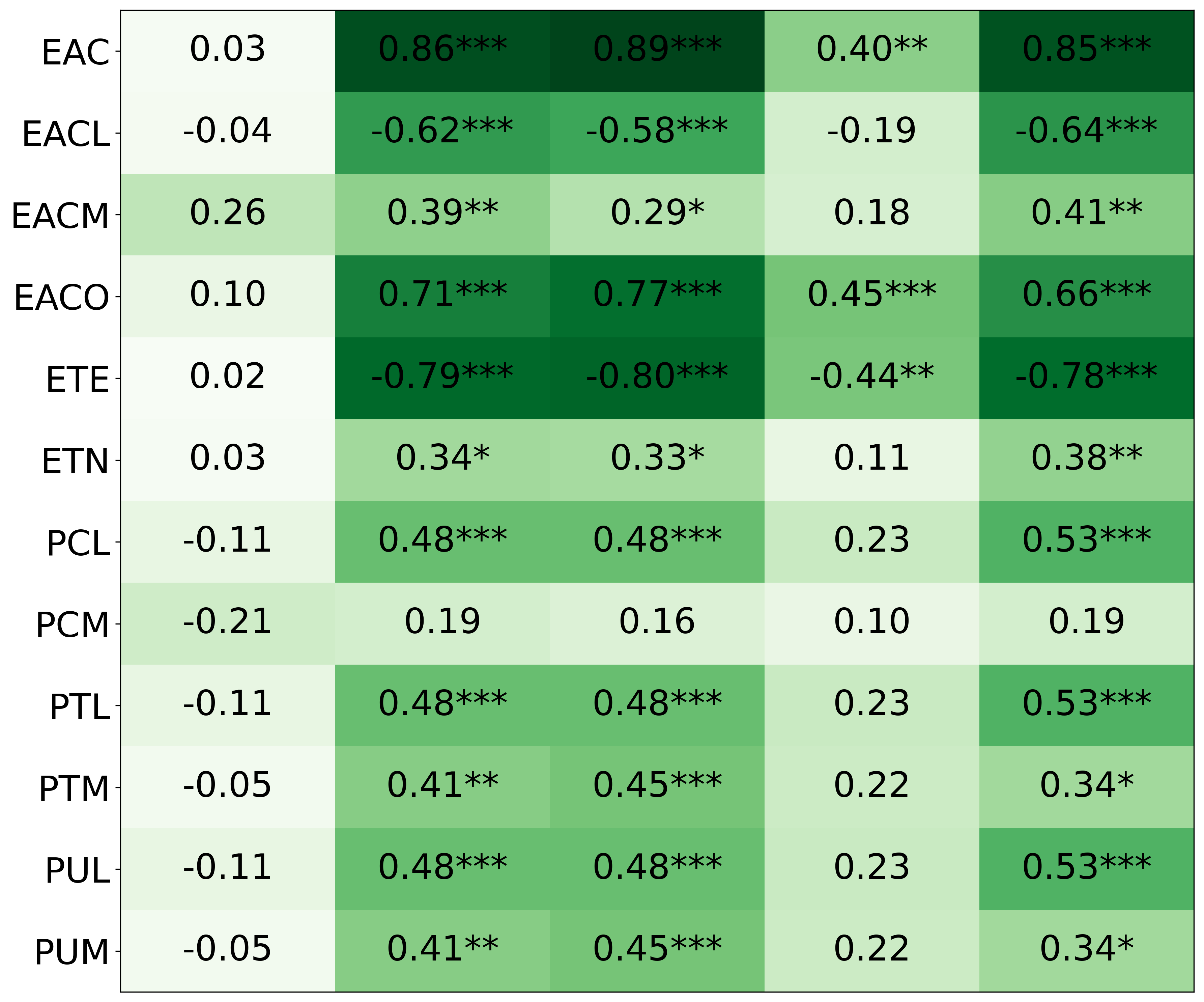
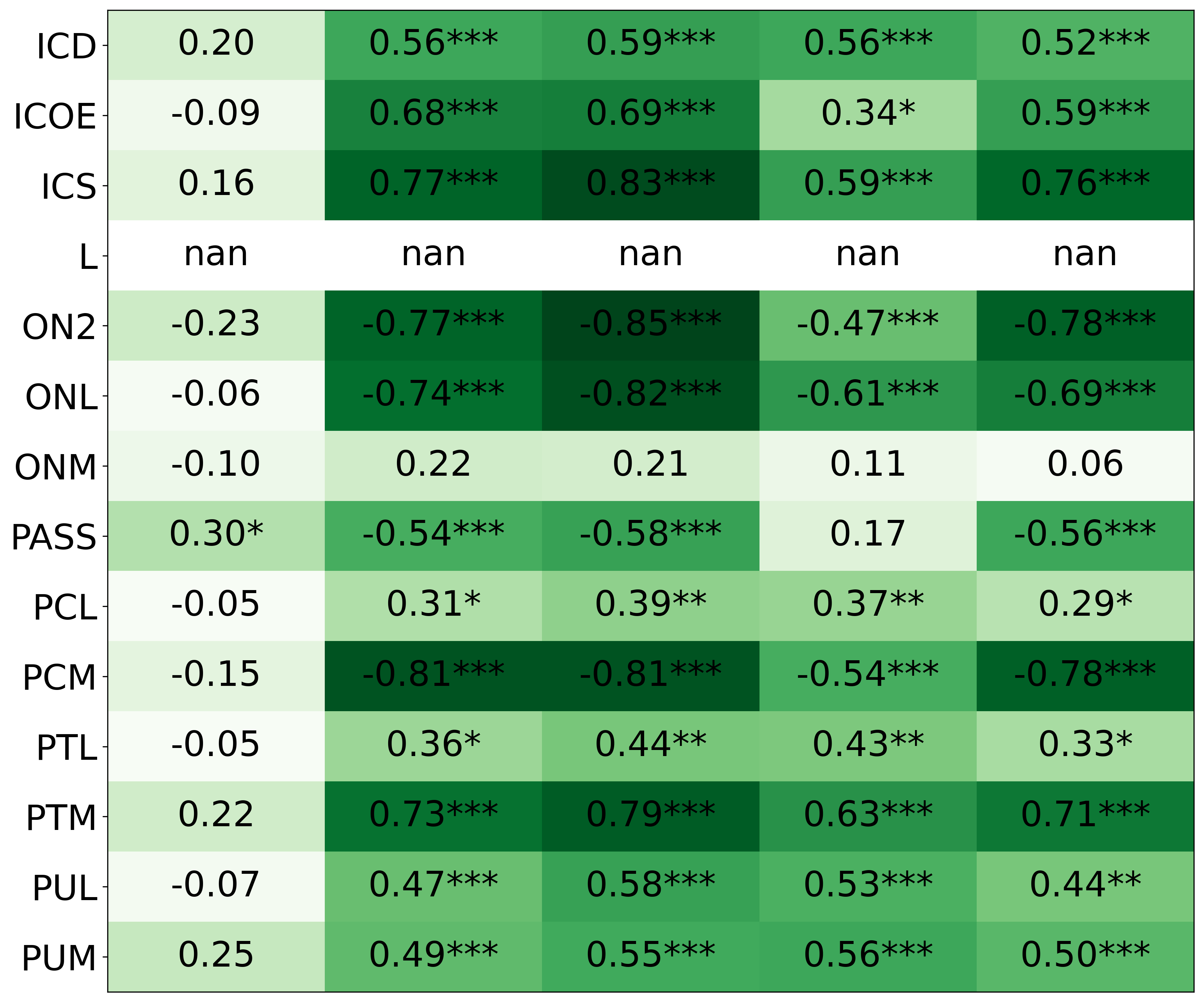
- With PI, the AI’s rule choices matched personality features like “strategic thinker,” “domain expert,” and “good at PERIL,” and those features correlated with higher performance.
- Without PI, those connections were weak or inconsistent.
- Model size mattered less than method:
- Larger models (like GPT-4) made more coherent, opposite-consistent rule sets using the PI method.
- Smaller models were noisier, but still benefited from PI more than DH.
In short: Simply telling an AI “be a bold commander” doesn’t reliably change how it plays. But guiding it through a structured questionnaire that maps personality to decision rules does.
What’s the bigger impact?
- Better simulations and training: If AI agents can reliably act like different personality types, they can be used in realistic training simulations, team planning, or strategy testing.
- More trustworthy AI decisions: Using a mediator (the questionnaire) makes the AI’s choices clearer, more consistent, and easier to explain—important for collaboration and safety.
- Beyond style: Persona prompts change writing style easily, but this work shows you need structure (like a questionnaire) to change actual behavior.
The takeaway: Personas can influence AI decision-making in complex, competitive settings—but you need a good translator between “personality” and “action.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable follow-up research.
- External validity beyond PERIL:
- Does persona-mediated heuristic generation improve performance in other strategic environments (different maps, rules, or games) and in non-gaming decision tasks?
- Do effects transfer to real-time or continuous-control settings where decisions are not turn-based?
- Human-centered validity:
- Do PI-derived heuristics align with human players’ self-reported traits and observed play styles in PERIL (construct and predictive validity)?
- Can human raters predict performance from persona descriptions as well as (or better than) LLM annotators?
- Psychometric rigor of the personality inventory mediator:
- No report of internal consistency (e.g., Cronbach’s alpha), factor structure, or measurement invariance across models; these are needed to justify the “exploratory factor analysis–inspired” claims.
- Item–heuristic mappings were manually curated; coverage balance, cross-loading, and redundancy were not analyzed.
- Sensitivity of outcomes to inventory length, item wording, response scales, and scoring (e.g., ±2/±1) remains untested.
- Mapping function and hyperparameter sensitivity:
- The transformation from inventory scores to heuristic weights (including choice of λ=0.5) lacks ablation; robustness to alternative mappings is unknown.
- No calibration to ensure comparable weight distributions across DH and PI beyond matching the mean.
- Metric correctness and consistency:
- The “opposite-value consistency” formula appears to cap via max(...,100) rather than min(100,...), which would force values to 100 and may invalidate conclusions; needs correction and re-analysis.
- The narrative description of opposite-value consistency (ratio-based) and the reported table statistic (average score differences) do not clearly align; the connection between metric and interpretation is unclear.
- Tournament design and ranking stability:
- TrueSkill reliability is impacted by schedule and ordering effects; low rank correlation across PI runs remains unexplained.
- No round-robin coverage, first-player advantage assessment, or seed/initialization control; these factors may confound rankings.
- No statistical tests for performance differences across personas/groups (beyond correlations), and no multiple-comparisons correction despite many tests.
- Scope of heuristics and adaptivity:
- Heuristic set is limited and static; agents cannot adapt heuristics during play. How would online adaptation (e.g., bandits, RL, or dynamic re-weighting) interact with personas?
- Phase-specific versus global/persona-level influences are not disentangled; which heuristics actually drive wins?
- Two-player restriction:
- Most heuristics reference properties (e.g., “player with most regions”) that are more meaningful with >2 players; effects in multi-player games remain untested.
- Missions and deception:
- Only world-domination mission used; the mission mode (e.g., heterogeneous or secret goals) is untested, leaving open questions about personas under deception or asymmetric information.
- Combat and game stochasticity:
- Combat resolution mechanics and randomness were not described or ablated; the extent to which stochastic outcomes swamp heuristic effects is unknown.
- Baselines and ceilings:
- No comparison against strong non-persona baselines (e.g., hand-tuned or search-based agents, greedy expected-value policies) to quantify the practical benefit of personas.
- No upper bound or oracle analysis to contextualize effect sizes.
- Model and prompting confounds:
- Decoding settings (temperature, top-p, seeds) and prompt variants are not reported; robustness to these choices is unknown.
- The same vendor family (GPT-4 variants) is used for both annotating features and building the mediator, risking shared-bias “leakage”; cross-vendor validation is needed.
- Persona selection and annotation validity:
- Personas are synthetic and selected via a greedy variance criterion; generalizability to more typical or human-derived personas is unclear.
- Persona feature labels (e.g., perilSpecific) come from LLM annotations, not human ground truth; their validity and potential circularity remain open.
- Interpretability and causal mechanisms:
- The link from persona traits to micro-level action patterns is not established; which specific decision patterns differentiate top vs. bottom personas?
- No causal analysis (e.g., ablations per heuristic dimension) to explain why certain personas win.
- Reliability across maps and initial conditions:
- Only one map/topology appears to be used; results may be map-specific.
- Effects of starting positions, reinforcement distributions, and initial deployments are not isolated.
- Small vs. large model behavior:
- Why do smaller models produce noisier PI mappings? Is the issue architecture, instruction-tuning, scale, or prompt sensitivity?
- Could fine-tuning or lightweight adapters improve PI consistency for smaller models?
- Persona persistence over time:
- Do personas degrade or drift if heuristics are updated mid-game or across episodes?
- Would in-the-loop LLM agents (reasoning each turn under a persona) outperform precommitment-only heuristic agents?
- Ethical and bias analyses:
- How do personas encode or amplify social biases (e.g., nationality, age) in adversarial play? Are there fairness or safety implications when deploying persona-driven agents?
- Reproducibility details:
- Complete release of code, prompts, seeds, and raw outputs (PI answers, DH values) is needed for independent re-analysis of metrics, mapping functions, and statistical tests.
- Generalization beyond games:
- Can the mediator approach improve persona-driven decision-making in complex planning (logistics, cyber-defense, resource allocation) where stakes and constraints differ from board games?
Practical Applications
Immediate Applications
Below are applications that can be deployed now using the paper’s open-source PERIL platform, the persona-to-heuristic mediator (inventory-based method), and the evaluation procedures reported.
- Persona-to-heuristic mediator for safer, more controllable agents
- Sectors: software, gaming, customer support
- Tools/products/workflows: Persona Inventory Mediator pipeline that maps persona responses to action heuristics; opposite-value consistency (OVC) checks; feature–heuristic correlation dashboards
- Assumptions/dependencies: Access to a capable LLM (GPT‑4 class performs best in the paper); curated inventory items and heuristic mappings; acceptance that effects have face validity, not clinical validity
- PERIL as a benchmark and tournament harness for strategic reasoning
- Sectors: AI labs, academia, model vendors
- Tools/products/workflows: Open-source PERIL code; two-player TrueSkill tournament harness; prompt variants (DH vs PI) A/B tests
- Assumptions/dependencies: Compute resources; awareness of TrueSkill “locking” over long runs; reproducible seeding and match scheduling
- Red-team and wargaming prototypes with persona-calibrated agents
- Sectors: defense, cybersecurity
- Tools/products/workflows: PERIL “mission mode” for non–world-domination objectives; persona-inventory–derived aggressiveness/caution heuristics
- Assumptions/dependencies: Domain-appropriate missions and heuristics; results are indicative, not operationally validated
- Educational labs for strategy, game AI, and psychometrics-in-LLMs
- Sectors: higher education, workforce training
- Tools/products/workflows: Classroom exercises to design inventories, generate heuristics, and test OVC; student projects evaluating DH vs PI reliability
- Assumptions/dependencies: Instructor time; course integration; access to at least one frontier model for the mediator stage
- QA and governance guardrails for persona features in products
- Sectors: software QA, product governance
- Tools/products/workflows: OVC “linting” in CI pipelines; regression tests for feature–heuristic correlations; release checks that persona changes produce measurable behavior differences
- Assumptions/dependencies: Defined pairs of opposite heuristics; telemetry and evaluation harnesses
- Product A/B tests that compare naive role prompts vs mediated personas
- Sectors: product/UX, conversational AI
- Tools/products/workflows: Controlled experiments measuring decision-level metrics (not just tone) to validate persona impact
- Assumptions/dependencies: Event-level instrumentation; acceptance that naive persona prompts often fail to change behavior
- Synthetic user behavior for recommender/marketing experiments
- Sectors: ads, recommendation systems, marketing analytics
- Tools/products/workflows: Mediator-driven agent cohorts with distinct, reproducible “risk appetite” or “competition focus” profiles
- Assumptions/dependencies: Mapping inventory items to platform-specific actions/policies; careful bias monitoring
- Game studios: tunable NPC behavior via in-game questionnaires
- Sectors: gaming
- Tools/products/workflows: Lightweight inventory presented to players; sliders linked to PERIL-style heuristic weights
- Assumptions/dependencies: NPC behavior surfaces aligned with heuristics; playtesting for balance
- Model selection guidance for persona mediation
- Sectors: ML engineering
- Tools/products/workflows: Use GPT‑4–class models for the mediator step; optionally distill outputs to smaller runtime models; validate with OVC and correlation tests
- Assumptions/dependencies: API availability; budget and latency constraints
- Internal policy guidance: avoid overclaiming persona effects
- Sectors: organizational policy, compliance
- Tools/products/workflows: Require mediator-based evidence (e.g., OVC, correlation, tournament differential) whenever persona prompts affect decisions
- Assumptions/dependencies: Adoption of minimal evaluation standards; documentation workflows
Long-Term Applications
These applications likely require further research, scaling, human validation, or domain adaptation beyond PERIL.
- Psychometrically validated mediators for real domains
- Sectors: healthcare, finance, emergency response
- Tools/products/workflows: Domain-specific inventories linked to action heuristics; exploratory/confirmatory factor analysis; expert review and human-subjects validation
- Assumptions/dependencies: IRB approvals; gold-standard datasets; cross-cultural validity; safety constraints
- Adaptive agents that update heuristics online
- Sectors: software, operations, robotics
- Tools/products/workflows: Closed-loop “auto-calibration” that re-elicits inventory responses as context shifts; RL or Bayesian updating over heuristic weights
- Assumptions/dependencies: Robust safety envelopes; drift detection; interpretability requirements
- Policy and societal simulations with persona-diverse agents
- Sectors: public policy, defense, econ/behavioral science
- Tools/products/workflows: Multi-agent PERIL-like platforms with negotiation, misinformation, and coalition missions; calibrated agent populations
- Assumptions/dependencies: Validation against human data; transparency on limits; interdisciplinary oversight
- Standards and audits for persona-driven systems
- Sectors: regulators, standards bodies, enterprise compliance
- Tools/products/workflows: Certification that systems meet OVC thresholds, show feature–heuristic validity, and avoid spurious persona claims
- Assumptions/dependencies: Consensus metrics; third-party audit infrastructure
- Human–machine teaming simulators with controllable teammate/adversary traits
- Sectors: defense, emergency management, healthcare operations
- Tools/products/workflows: Training platforms where agent profiles (e.g., cautious vs aggressive) are tuned via inventories; performance feedback loops
- Assumptions/dependencies: Integration with existing training curricula; rigorous outcome studies
- Enterprise agent profile marketplaces
- Sectors: enterprise SaaS, CRM, customer support
- Tools/products/workflows: Libraries of pre-validated agent profiles (with documented behavioral deltas) and SDKs for safe integration
- Assumptions/dependencies: IP/licensing; ongoing monitoring; domain adaptation
- Deception-aware and counter-deception multi-agent systems
- Sectors: cybersecurity, defense, fraud detection
- Tools/products/workflows: Mission-mode scenarios with deceptive policies; analysis tools to detect/mitigate deceptive heuristic patterns
- Assumptions/dependencies: New evaluation tasks; safety cases for adversarial interactions
- Personalized decision coaching and training
- Sectors: consumer productivity, education
- Tools/products/workflows: Apps that assess user tendencies via inventories and tailor strategy advice; explainable heuristic sliders
- Assumptions/dependencies: Privacy-preserving data handling; avoidance of clinical claims; user-informed consent
- Risk-governed financial agents
- Sectors: finance
- Tools/products/workflows: Inventory-constrained trading/risk agents that enforce risk appetite and policy compliance at the heuristic level; audit logs of heuristic changes
- Assumptions/dependencies: Regulatory approval; extensive backtesting; model risk management
- Robotics/task allocation with personality-informed autonomy
- Sectors: robotics, logistics, manufacturing
- Tools/products/workflows: High-level heuristic controllers that adapt exploration/aggression levels to operator or mission profiles
- Assumptions/dependencies: Sim-to-real validation; safety certification; human factors studies
Each long-term application hinges on empirically validating that inventory-driven heuristic control preserves safety, fairness, and domain correctness, and on demonstrating benefits over naive persona prompting in real-world decision environments.
Glossary
- Adversarial strategic environment: A setting where agents compete with opposing objectives, requiring strategies that consider opponents' actions. "decision-making in an adversarial strategic environment that we provide as open-source."
- Anthropomorphize (LLMs): Attribute human-like qualities, intentions, or emotions to LLMs. "persona prompting interacts with broader tendencies to anthropomorphize LLMs."
- Dash Cytoscape: A Python library for interactive graph/network visualization within Dash applications. "Using Python and the Dash Cytoscape library \cite{dash_cytoscape}, we implemented a framework for creating custom maps and allowing AI-controlled players to compete"
- ELO score: A rating system originally developed for chess that estimates player skill based on match outcomes. "a generalization of the more well-known ELO score"
- Exploratory factor analysis: A statistical technique used to identify underlying latent variables (factors) from observed measurements. "a structured translation process, inspired by exploratory factor analysis, that maps LLM-generated inventory responses into heuristics."
- Face validity: The extent to which a test or method appears, on its surface, to measure what it claims to measure. "enhances heuristic reliability and face validity compared to directly inferred heuristics"
- Greedy algorithm: An algorithmic strategy that makes the locally optimal choice at each step in hopes of finding a global optimum. "We then used a greedy algorithm to find the 50 personas that maximize the product of the variances across all features :"
- Hallucination rate: The frequency with which an LLM produces confident but incorrect or fabricated information. "multi-agent systems consisting of multiple personas working together can produce differences in reasoning, hallucination rate, and more"
- Heuristic: A rule-of-thumb or simple decision-making strategy used to guide actions in complex environments. "where individual behavioral tendencies such as aggression, patience, caution, and others dictate the heuristics that guide players' decision-making."
- HuggingFace: A platform and repository for machine learning models, datasets, and tools. "Non-GPT models were downloaded from HuggingFace\footnote{https://huggingface.co/models} and run with stock configurations on 6 H100 GPUs."
- LLM: A neural network trained on vast text corpora to generate and understand human-like language. "Although persona prompting in LLMs appears to trigger different styles of generated text"
- Mediator: An intermediate process or mechanism used to translate inputs (e.g., personas) into actionable outputs (e.g., heuristic values). "but only when a mediator is used to translate personas into heuristic values."
- MMLU benchmark: Massive Multitask Language Understanding; a benchmark suite assessing broad academic and professional knowledge. "on a subset of the MMLU benchmark tasks \cite{hendrycks2021measuring}"
- Multi-agent systems: Systems composed of multiple interacting agents that can collaborate or compete. "multi-agent systems consisting of multiple personas working together can produce differences in reasoning, hallucination rate, and more"
- Opposite-value consistency: The expected property that opposite heuristics receive opposite-valued settings for a given persona. "opposite-value consistency: heuristics specifying opposite properties should have opposite values"
- PERIL: A custom strategic world-conquest board game environment used to evaluate AI decision-making. "we implemented a game loosely inspired by the board game Risk\textsuperscript{\textregistered}, which we call PERIL."
- Persona prompting: A prompting technique where an LLM is instructed to adopt and act according to a specified personality description. "persona prompting, a prompting strategy in which a pre-trained LLM is prompted with a description of a personality and asked to act in accordance with it."
- Personality inventory: A standardized questionnaire used to assess personality traits, here used to map personas to heuristic values. "We introduce the use of personality inventory questionnaires to translate personas into heuristic choices in an end-to-end fashion."
- Personality Inventory for DSM-5 (PID-5)—Adult: An APA inventory for assessing maladaptive personality traits in adults. "inspired by the American Psychiatric Association's Personality Inventory for DSM-5 (PID-5)âAdult \cite{Krueger2012}."
- Precommitment: The strategy of fixing rules or heuristics in advance to reduce cognitive load and inconsistency under pressure. "strategic actors may benefit from precommitment, or the fixing of rules and heuristics that will constrain one's behavior ahead of time"
- Psychometric principles: The theoretical and methodological foundations of psychological measurement, including reliability and validity. "propose a heuristic generation method that applies psychometric principles to LLMs."
- Spearman correlation: A nonparametric measure of rank correlation between two variables. "we calculated the Spearman correlation (Table \ref{tbl:featureCorrelations})."
- TrueSkill algorithm: A Bayesian rating system that generalizes ELO to estimate player skill, including for multiplayer games. "To measure player skill level, we use the TrueSkill algorithm \cite{Herbrich2006}, a generalization of the more well-known ELO score"
Collections
Sign up for free to add this paper to one or more collections.