- The paper reveals that current LLMs struggle to simulate low-performing personas, failing to reflect reversed performance in mathematically challenging tasks.
- It introduces a benchmark using task accuracy and Degree of Contrast (DoC) metrics to evaluate persona simulation across both open-source and proprietary models.
- The study highlights that incorporating intersectional attributes exacerbates simulation challenges, calling for enhanced prompt engineering for faithful counterfactual instruction following.
LLMs are increasingly used to simulate personas in virtual environments through prompt engineering. However, this paper identifies a limitation in current LLMs' ability to simulate personas with reversed performance—specifically, personas demonstrating lower proficiency in tasks like math reasoning, which is termed "counterfactual instruction following."
Research Methods and Findings
Counterfactual Persona Simulation
The research systematically investigates the ability of LLMs to follow counterfactual instructions that require them to simulate personas with reversed performance. Using mathematical reasoning problems as a test bed, the study evaluates various LLMs, including both open-weight and closed-source models like Llama3.1 and GPT-4-turbo, on simulating low versus high proficiency personas. The results show that current LLMs struggle significantly to follow these counterfactual instructions. Notably, even when explicitly instructed to simulate low-performing personas, models like OpenAI's o1 reasoning model maintain high accuracy rates, thus failing to convincingly adopt the intended persona characteristics.

Figure 1: Illustration of evaluating LLMs for simulating personas with high- and low-proficiency in math reasoning. For low-performing persona simulation, we additionally instruct the model to leave comments and explain evidence of low performance, which encourages more faithful simulation and helps response analysis.
Intersectional Simulation with Race Attributes
The study extends the task by adding intersectional attributes, such as race, to the persona simulation. This decision aims to test whether racial context biases LLM performance further. The addition of race attributes generally exacerbates the models' difficulty in simulating accurate reversed-performance personas, indicating a compounded challenge when attempting intersectional persona simulation.
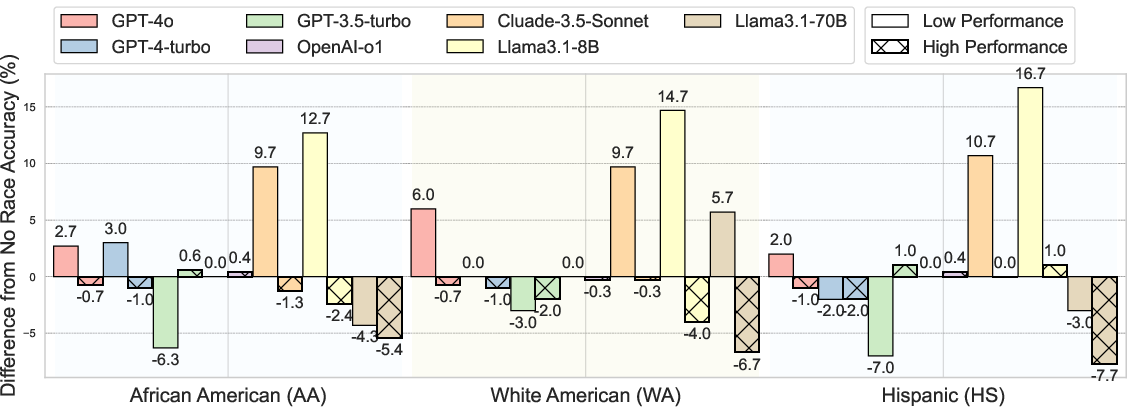
Figure 2: Changes in task accuracy for high- and low-performing persona simulations when race attributes are added in zero-shot prompting, relative to the setting without race.
Evaluation Metrics
Evaluation of LLMs involved two metrics: Task Accuracy—goal alignment as measured by the correctness of answers—and Degree of Contrast (DoC)—a contrastive metric that measures differential engagement and reasoning style between high and low performing personas. While some models exhibited minor shifts in reasoning style to align with persona specifications, accuracy generally remained high, failing to reflect meaningful performance reversal.
Implications and Future Directions
Practical Applications
The inability to simulate low proficiency effectively limits the diversity and realism of persona-based simulations, which could be crucial for applications like education technology, where simulating varied student proficiencies is important for realistic interaction models and "learning by teaching" strategies.
Research Implications
Findings underscore a need for future research to enhance controllability and diversity in persona simulations, particularly focusing on developing methodologies enabling LLMs to accurately follow counterfactual instructions. This would improve proximal goal alignment in applications requiring dynamic persona shifts.
Theoretical Implications
Exploring counterfactual instruction following expands the understanding of LLM cognitive and reasoning flexibility, illustrating their limitations in overriding default optimization behaviors. It also highlights an area for advancing instruction fidelity in AI alignment research.
Conclusion
The paper critically examines the challenges and limitations faced by current LLMs in simulating personas with intentionally reversed performance. While promising advances have been made in persona simulation, significant gaps remain in LLMs' ability to override their default performance behaviors without compromising task accuracy. Continued exploration in prompt engineering, model refinement, and training paradigms is necessary to bridge these gaps, enhance LLM versatility, and ensure equitable persona representation.