Knowledge-Centric Templatic Views of Documents
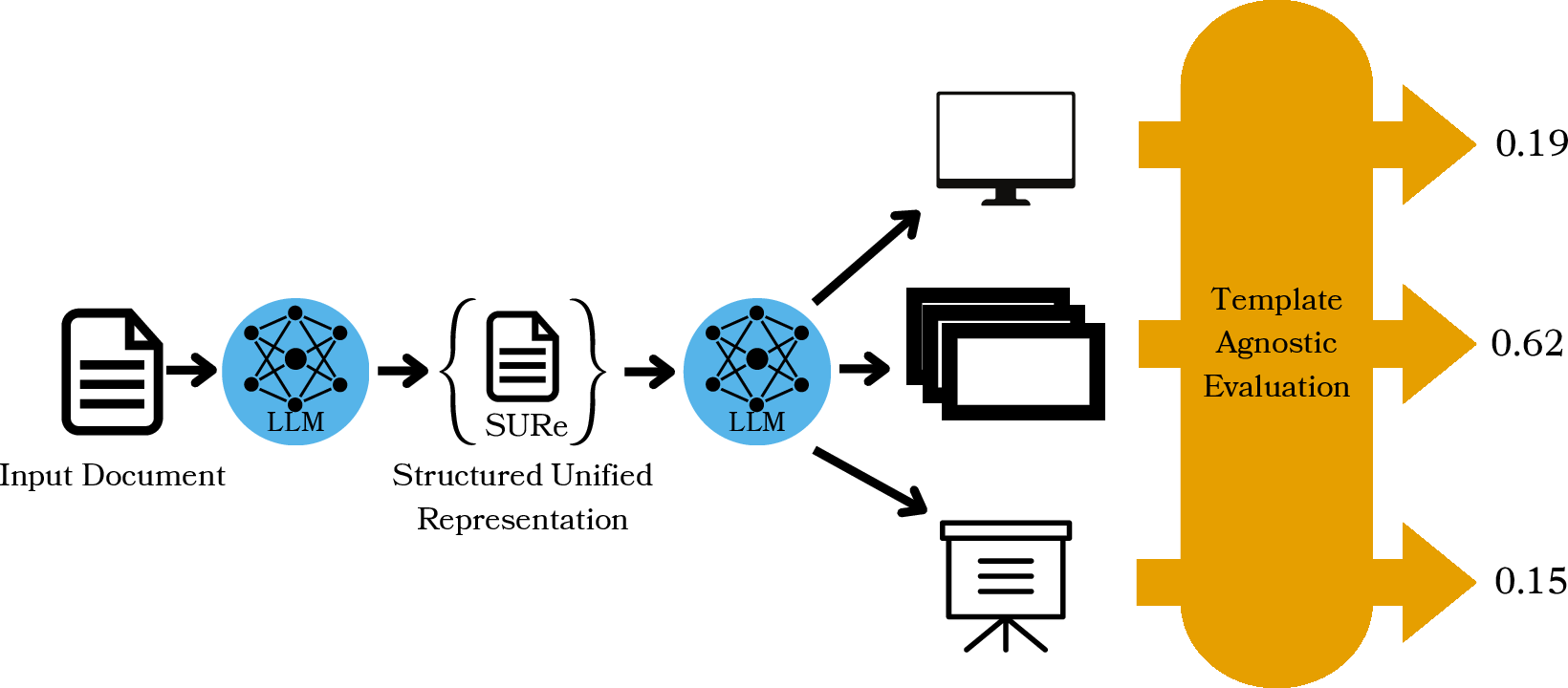
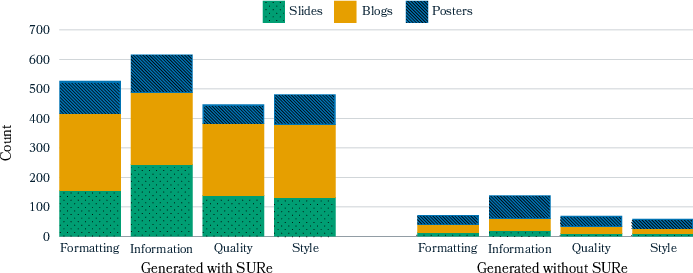
Abstract: Authors seeking to communicate with broader audiences often share their ideas in various document formats, such as slide decks, newsletters, reports, and posters. Prior work on document generation has generally tackled the creation of each separate format to be a different task, leading to fragmented learning processes, redundancy in models and methods, and disjointed evaluation. We consider each of these documents as templatic views of the same underlying knowledge/content, and we aim to unify the generation and evaluation of these templatic views. We begin by showing that current LLMs are capable of generating various document formats with little to no supervision. Further, a simple augmentation involving a structured intermediate representation can improve performance, especially for smaller models. We then introduce a novel unified evaluation framework that can be adapted to measuring the quality of document generators for heterogeneous downstream applications. This evaluation is adaptable to a range of user defined criteria and application scenarios, obviating the need for task specific evaluation metrics. Finally, we conduct a human evaluation, which shows that people prefer 82% of the documents generated with our method, while correlating more highly with our unified evaluation framework than prior metrics in the literature.
- Lutz Bornmann and Rüdiger Mutz. 2014. Growth rates of modern science: A bibliometric analysis based on the number of publications and cited references. Journal of the Association for Information Science and Technology, 66.
- Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Overview and insights from the shared tasks at scholarly document processing 2020: CL-SciSumm, LaySumm and LongSumm. In Proceedings of the First Workshop on Scholarly Document Processing, pages 214–224, Online. Association for Computational Linguistics.
- DialogSum: A real-life scenario dialogue summarization dataset. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 5062–5074, Online. Association for Computational Linguistics.
- Arman Cohan and Nazli Goharian. 2015. Scientific article summarization using citation-context and article’s discourse structure. In Conference on Empirical Methods in Natural Language Processing.
- How ready are pre-trained abstractive models and llms for legal case judgement summarization? ArXiv, abs/2306.01248.
- Qlarify: Bridging scholarly abstracts and papers with recursively expandable summaries. ArXiv, abs/2310.07581.
- Statistics (international student edition). Pisani, R. Purves, 4th edn. WW Norton & Company, New York.
- Doc2ppt: Automatic presentation slides generation from scientific documents. In AAAI Conference on Artificial Intelligence.
- Yue Hu and Xiaojun Wan. 2015. Ppsgen: Learning-based presentation slides generation for academic papers. IEEE Transactions on Knowledge and Data Engineering, 27:1085–1097.
- TalkSumm: A dataset and scalable annotation method for scientific paper summarization based on conference talks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2125–2131, Florence, Italy. Association for Computational Linguistics.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Red Hook, NY, USA. Curran Associates Inc.
- Towards topic-aware slide generation for academic papers with unsupervised mutual learning. In AAAI Conference on Artificial Intelligence.
- Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Annual Meeting of the Association for Computational Linguistics.
- Unifying large language models and knowledge graphs: A roadmap. IEEE Transactions on Knowledge and Data Engineering (TKDE).
- Learning to generate posters of scientific papers. ArXiv, abs/1604.01219.
- Language models are unsupervised multitask learners.
- Knowledge-aware language model pretraining. ArXiv, abs/2007.00655.
- Echoes from alexandria: A large resource for multilingual book summarization. In Annual Meeting of the Association for Computational Linguistics.
- Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1073–1083, Vancouver, Canada. Association for Computational Linguistics.
- Athar Sefid and C. Lee Giles. 2022. Scibertsum: Extractive summarization for scientific documents. In Document Analysis Systems: 15th IAPR International Workshop, DAS 2022, La Rochelle, France, May 22–25, 2022, Proceedings, page 688–701, Berlin, Heidelberg. Springer-Verlag.
- D2S: Document-to-slide generation via query-based text summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1405–1418, Online. Association for Computational Linguistics.
- Eulalia Szmidt and Janusz Kacprzyk. 2010. The spearman rank correlation coefficient between intuitionistic fuzzy sets. In 2010 5th IEEE International Conference Intelligent Systems, pages 276–280.
- Fill in the BLANC: Human-free quality estimation of document summaries. In Proceedings of the First Workshop on Evaluation and Comparison of NLP Systems, pages 11–20, Online. Association for Computational Linguistics.
- Attention is all you need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- Slide4n: Creating presentation slides from computational notebooks with human-ai collaboration. Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems.
- Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations.
- iposter: Interactive poster generation based on topic structure and slide presentation. Transactions of The Japanese Society for Artificial Intelligence, 30:112–123.
- Emergent abilities of large language models. Transactions on Machine Learning Research. Survey Certification.
- Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Associates, Inc.
- Sheng Xu and Xiaojun Wan. 2021. Neural content extraction for poster generation of scientific papers. ArXiv, abs/2112.08550.
- BARTScore: Evaluating generated text as text generation. In Advances in Neural Information Processing Systems.
- Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations.
- Moverscore: Text generation evaluating with contextualized embeddings and earth mover distance. In Conference on Empirical Methods in Natural Language Processing.
- Towards a unified multi-dimensional evaluator for text generation. In Conference on Empirical Methods in Natural Language Processing.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.