Presentations are not always linear! GNN meets LLM for Document-to-Presentation Transformation with Attribution
Abstract: Automatically generating a presentation from the text of a long document is a challenging and useful problem. In contrast to a flat summary, a presentation needs to have a better and non-linear narrative, i.e., the content of a slide can come from different and non-contiguous parts of the given document. However, it is difficult to incorporate such non-linear mapping of content to slides and ensure that the content is faithful to the document. LLMs are prone to hallucination and their performance degrades with the length of the input document. Towards this, we propose a novel graph based solution where we learn a graph from the input document and use a combination of graph neural network and LLM to generate a presentation with attribution of content for each slide. We conduct thorough experiments to show the merit of our approach compared to directly using LLMs for this task.
- ’auto-presentation’: a multi-agent system for building automatic multi-modal presentation of a topic from world wide web information. In IEEE/WIC/ACM International Conference on Intelligent Agent Technology, pages 246–249.
- Automatic era: Presentation slides from academic paper. In 2016 International Conference on Automatic Control and Dynamic Optimization Techniques (ICACDOT), pages 809–814.
- Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Doc2ppt: Automatic presentation slides generation from scientific documents. In AAAI Conference on Artificial Intelligence.
- Yue Hu and Xiaojun Wan. 2013. Ppsgen: learning to generate presentation slides for academic papers. In Twenty-Third International Joint Conference on Artificial Intelligence. Citeseer.
- Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Thomas N. Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net.
- Deep submodular networks for extractive data summarization. arXiv preprint arXiv:2010.08593.
- Towards topic-aware slide generation for academic papers with unsupervised mutual learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 13243–13251.
- VMSMO: Learning to generate multimodal summary for video-based news articles. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9360–9369, Online. Association for Computational Linguistics.
- Visual instruction tuning. Advances in neural information processing systems, 36.
- Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172.
- G-eval: NLG evaluation using gpt-4 with better human alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore. Association for Computational Linguistics.
- Roberta: A robustly optimized bert pretraining approach. Preprint, arXiv:1907.11692.
- On learning text style transfer with direct rewards. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4262–4273, Online. Association for Computational Linguistics.
- On spectral clustering: Analysis and an algorithm. Advances in neural information processing systems, 14.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR.
- Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
- Garr Reynolds. 2011. Presentation Zen: Simple ideas on presentation design and delivery. New Riders.
- Slidesgen: Automatic generation of presentation slides for a technical paper using summarization. In Twenty-Second International FLAIRS Conference.
- D2S: Document-to-slide generation via query-based text summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1405–1418, Online. Association for Computational Linguistics.
- Presentation slides generation from scientific papers using support vector regression. In 2017 International Conference on Inventive Communication and Computational Technologies (ICICCT), pages 286–291.
- Llama 2: Open foundation and fine-tuned chat models. Preprint, arXiv:2307.09288.
- Phrase-based presentation slides generation for academic papers. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 31.
- Phrase-based presentation slides generation for academic papers. Proceedings of the AAAI Conference on Artificial Intelligence, 31(1).
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Automatically generating engaging presentation slide decks. In EvoMUSART.
- Kaige Xie and Mark Riedl. 2024. Creating suspenseful stories: Iterative planning with large language models. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2391–2407, St. Julian’s, Malta. Association for Computational Linguistics.
- MSMO: Multimodal summarization with multimodal output. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4154–4164, Brussels, Belgium. Association for Computational Linguistics.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Immediate Applications
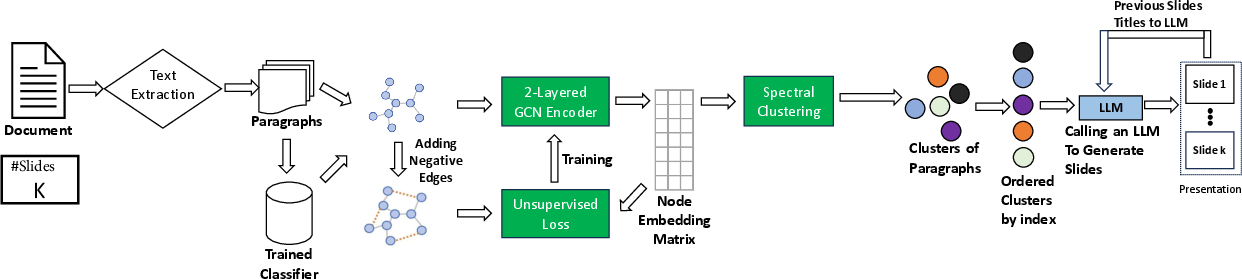
Below are actionable use cases that can be deployed now, leveraging the paper’s GDP pipeline (graph learning + LLM) and its core features: non-linear narrative construction, slide-level attribution to source paragraphs, improved coverage/fluency, and domain-agnostic applicability to long, text-heavy documents.
Industry
- Enterprise document-to-deck generation with traceability
- Sectors: software, consulting, legal, finance, energy
- Workflow: Ingest long reports/PRDs/RFPs/whitepapers → extract paragraphs → build document graph → cluster → generate slides with titles and attributed bullet points → export PPTX/Google Slides.
- Tools/products: “Presenter with Attribution” plugin for PowerPoint/Google Slides; GDP-as-a-Service API; SharePoint/Confluence integration.
- Assumptions/dependencies: High-quality PDF/text extraction; reliable paragraph segmentation; user-provided slide count K; LLM access; organizational content privacy controls.
- Sales enablement and proposal acceleration
- Sectors: B2B SaaS, consulting, manufacturing
- Workflow: Convert proposals and case studies into client-ready decks with slide-level links to source paragraphs for quick edits and compliance.
- Tools/products: CRM/CPQ plugin; proposal-to-deck generator.
- Assumptions/dependencies: Accurate mapping of proposal sections; consistent document formatting.
- Marketing content repurposing
- Sectors: marketing, media
- Workflow: Turn long-form blogs/whitepapers into campaign decks with non-linear narrative tailored to audience; include attributed bullets to speed approvals.
- Tools/products: CMS plugin (e.g., WordPress/HubSpot) exporting decks; brand checklist integration.
- Assumptions/dependencies: Brand style constraints; reviewer approval workflows.
- Knowledge management and auditing
- Sectors: regulated industries (finance, healthcare, aerospace)
- Workflow: Generate training decks from policies/SOPs with slide-to-paragraph attribution to support audits and reduce hallucination risk.
- Tools/products: Compliance auditor dashboard linking slides to source paragraphs.
- Assumptions/dependencies: Document versioning; access controls; policy repositories.
- Analyst report summarization to investor decks
- Sectors: finance
- Workflow: Non-linear narrative captures cross-section insights (market overview → risks → valuations), with paragraph-level citations.
- Tools/products: Deck generator integrated with financial research platforms.
- Assumptions/dependencies: Correct financial terminology; domain-specific LLM prompts.
- Technical support and field manuals
- Sectors: manufacturing, energy, telecom
- Workflow: Convert long technical manuals into stepwise training decks with attributed instructions and safety notes.
- Tools/products: LMS integration; offline deck export for field use.
- Assumptions/dependencies: Consistent manual structures; text-heavy documents.
Academia and Education
- Research paper to talk slides
- Sectors: academia, edtech
- Workflow: Ingest papers → generate non-linear decks that mirror human presentation narrative; attribution aids last-minute edits and fact-checking.
- Tools/products: Conference prep assistant; integrated with arXiv/Institutional repositories.
- Assumptions/dependencies: PDF quality; slides count K set by presenter.
- Course material and lecture prep
- Sectors: education
- Workflow: Convert chapters/long readings into lecture decks, preserving narrative (problem → methods → results) with slide-level citations.
- Tools/products: LMS plugin (Moodle/Canvas); instructor dashboard.
- Assumptions/dependencies: Text-centric readings; instructor curation.
Policy and Government
- Legislative briefings and stakeholder decks
- Sectors: public policy, government
- Workflow: Turn long bills/reports into briefings with traceable bullets back to statutory text; supports transparency and reduces misinterpretation.
- Tools/products: Briefing generator for committees; public portal with clickable citations.
- Assumptions/dependencies: Document standardization; privacy and FOIA considerations.
Healthcare
- Clinical guideline and policy brief slides
- Sectors: healthcare administration
- Workflow: Convert guidelines/policies into training decks; attribution supports compliance and reduces risk of clinical misstatements.
- Tools/products: Hospital policy-to-training deck tool.
- Assumptions/dependencies: Text-only focus (no images/diagrams yet); domain prompting.
Daily Life
- Book/article-to-presentation generator for study groups
- Sectors: consumer productivity
- Workflow: Create study decks from long readings; non-linear narrative supports thematic discussion; attributed slides aid citation.
- Tools/products: Browser/Notion plugin with deck export.
- Assumptions/dependencies: Clean text extraction; user-defined slide count.
Long-Term Applications
These depend on further research, scaling, or development—especially multimodal handling, template/style intelligence, and automation of agenda/slide count.
Multimodal and Template Intelligence
- Multimodal document-to-deck (images/tables/diagrams)
- Sectors: healthcare, engineering, research, finance
- Innovation: Integrate VLMs (e.g., CLIP/LLaVA) for figure/table extraction and slide construction with captions and chart reproductions.
- Tools/products: “Multimodal Presenter” with visual attribution.
- Dependencies: Robust OCR/table/figure parsing; domain-specific visual understanding; privacy/compliance for images.
- Style and template recommendation
- Sectors: marketing, corporate communications
- Innovation: Automatic selection of slide layouts, colors, and themes matched to content intent and audience persona.
- Tools/products: Theme selector; brand compliance checker.
- Dependencies: Brand guidelines; intent detection; user preference models.
Advanced Narrative and Personalization
- Audience-aware narrative shaping
- Sectors: education, enterprise training, sales
- Innovation: Personalize non-linear narratives for different roles (exec vs. technical) using graph-level re-weighting and constrained generation.
- Tools/products: Narrative designer; persona switcher.
- Dependencies: Role metadata; evaluation of comprehension outcomes.
- Automated agenda and slide-count inference
- Sectors: all
- Innovation: Predict K and agenda topics from document graph (avoiding manual K input), with constraints on time and audience.
- Tools/products: Time-bounded deck planner.
- Dependencies: Reliable topic segmentation; pacing models.
Reliability, Governance, and Collaboration
- End-to-end fact-checking and hallucination detection
- Sectors: regulated industries, public sector
- Innovation: Use attribution + retrieval to auto-flag bullets not supported by source paragraphs; integrate trust scores.
- Tools/products: Fact-checker panel; compliance audit trails.
- Dependencies: High-precision citation alignment; organizational policies.
- Collaborative editing on the document graph
- Sectors: enterprise productivity
- Innovation: Editable paragraph-slide graph; users can move nodes, see downstream effects, and re-generate affected slides.
- Tools/products: Graph workspace; versioning with change impact preview.
- Dependencies: Real-time graph ops; UI scalability.
Cross-Document and Knowledge Integration
- Cross-document synthesis decks
- Sectors: consulting, research, policy
- Innovation: Build a unified graph across multiple documents; cluster nodes into cross-source slides with source-level attribution for synthesis.
- Tools/products: Multi-source synthesizer; cross-repo search integration.
- Dependencies: Document normalization; deduplication; citation management.
- Knowledge base integration for ongoing updates
- Sectors: enterprise KM
- Innovation: Reusable graph representations of documents enabling auto-updated decks when source docs change.
- Tools/products: “Live Decks” connected to repositories.
- Dependencies: Change detection; incremental clustering; governance.
Evaluation and Metrics Transfer
- Narrative non-linearity and coverage as standard quality metrics
- Sectors: edtech, NLG tooling
- Innovation: Adopt the paper’s non-linearity and coverage metrics to evaluate other generative summarizers and slide generators.
- Tools/products: NLG evaluator SDK; analytics dashboards.
- Dependencies: Agreement studies with human raters; task-specific calibrations.
Multilingual and Accessibility
- Multilingual doc-to-deck with source-language attribution
- Sectors: global enterprises, NGOs
- Innovation: Generate decks in different languages while preserving citations to original paragraphs; support parallel corpora.
- Tools/products: Localization-aware presenter.
- Dependencies: Robust multilingual LLMs; translation quality control.
- Accessibility-first decks
- Sectors: public sector, education
- Innovation: Auto-generate alt-text and screen-reader friendly structure based on the graph and attribution.
- Tools/products: Accessibility checker and generator.
- Dependencies: Standards compliance (e.g., WCAG); multimodal support.
Real-Time and Streaming
- Real-time meeting notes to attributed slides
- Sectors: enterprise productivity
- Innovation: Stream transcriptions → segment into “paragraphs” → build evolving graph → generate ongoing slides for live briefings.
- Tools/products: Meeting assistant presenter.
- Dependencies: High-quality ASR; latency constraints; dynamic graph updates.
Sector-Specific Extensions
- Clinical trial/protocol decks with risk and rationale tracing
- Sectors: healthcare, pharma
- Innovation: Non-linear narrative linking rationale, methods, endpoints, and risks with precise citations.
- Tools/products: Protocol-to-deck generator.
- Dependencies: Domain ontologies; strict compliance workflows.
- Regulatory impact summaries
- Sectors: finance, energy, public policy
- Innovation: Auto-extract implications across sections and present decision-ready slides; maintain traceability to specific clauses.
- Tools/products: Regulatory navigator.
- Dependencies: Legal text parsing; expert validation cycles.
Notes on feasibility across applications:
- The current pipeline is text-only; multimodal adoption is a key dependency for technical and healthcare-heavy domains.
- Slide count K must be provided at inference; automated K/agenda inference requires additional modeling.
- Attribution depends on accurate paragraph segmentation and graph thresholding; noisy PDFs/OCR can reduce precision.
- Privacy, governance, and LLM access costs must be addressed for enterprise deployment.
- Domain adaptation (prompts/classifiers) may be required for specialized jargon (finance, legal, clinical).
Collections
Sign up for free to add this paper to one or more collections.