- The paper's main contribution is incorporating concrete syntax trees (CSTs) into pre-trained code models to improve performance in data-scarce environments.
- It introduces structured pre-training objectives such as masked subtree prediction and masked node prediction to capture both code grammar and semantics.
- Experimental results demonstrate significant gains in code translation and summarization tasks, validating the efficiency of structured representations.
Summary of "Structured Code Representations Enable Data-Efficient Adaptation of Code LLMs"
Introduction
The paper presents an innovative approach for adapting pre-trained LLMs to code tasks by incorporating structured representations of code, specifically concrete syntax trees (CSTs). This approach highlights the limitation of treating source code as plain text, which overlooks the inherent structural characteristics of programming languages. By using CSTs, the models can efficiently leverage the well-defined structures for improved performance on code tasks, especially in scenarios lacking abundant data.
Methodology
Structured Code Representations
Programming languages feature grammar structures that can be translated into CSTs, allowing models to parse programs unambiguously. While CSTs are more verbose than abstract syntax trees (ASTs), they contain all syntactic details necessary for precise program reconstruction. The serialized CSTs can be processed by sequence models without architectural changes, enabling seamless adaptation to structured inputs.
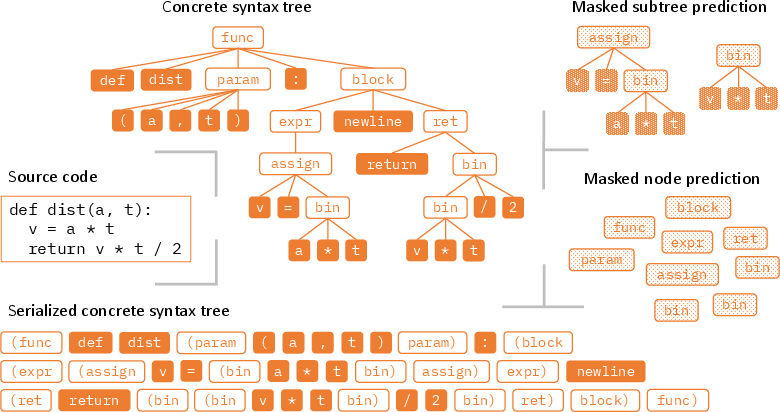
Figure 1: An example Python program along with its CST (simplified for illustration) in the tree and serialized forms, respectively. Also illustrated are the masked subtree prediction and masked node prediction training objectives for adapting pre-trained models to code structures.
Pre-Training and Fine-Tuning Objectives
The paper proposes several objectives to adapt existing code models, including masked subtree prediction (MSP), masked node prediction (MNP), and text-to-tree (TeTr) conversion. These objectives help the models learn the interplay between code grammar and semantics, focusing on both terminal and non-terminal nodes within the CSTs. For decoder-only models, a causal LLM objective on serialized CSTs is employed.
Experimental Setup
Models and Datasets
Two pre-trained models are adapted: CodeT5 (an encoder-decoder model) and CodeGen (a decoder-only model). The studies leverage CodeSearchNet and Stack datasets, providing a comprehensive range of programming languages and code with annotations. Continual pre-training on structured objectives was conducted with minimal computational overhead relative to initial pre-training.
Results
The structured approach demonstrated superior performance over base models across multiple code tasks, including translation, generation, and summarization. In particular, when using only limited labeled data, structured models significantly enhanced CodeBLEU scores and increased the proportion of functionally correct translations, as depicted in the code translation performance results.
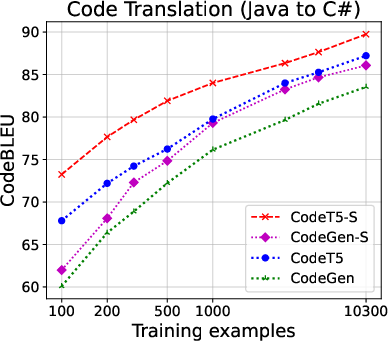
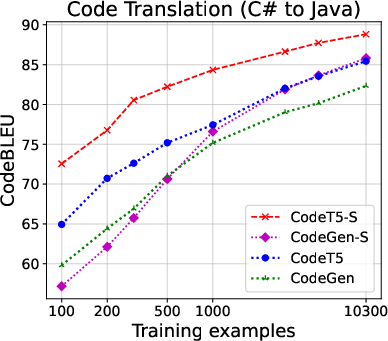
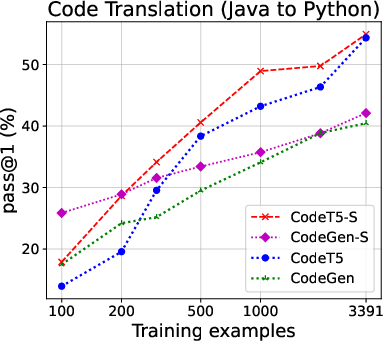
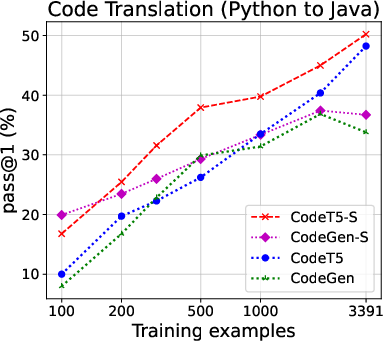
Figure 2: Code translation performance. Left two: Java ↔ C# (CodeXGLUE); right two: Java ↔ Python (TransCoder). For full results on all evaluation metrics, see the Appendix.
Code Summarization
The paper shows that structured models outperform traditional text-based counterparts significantly, achieving higher BLEU scores with fewer examples, revealing the efficiency of structured adaptations in summarization tasks.
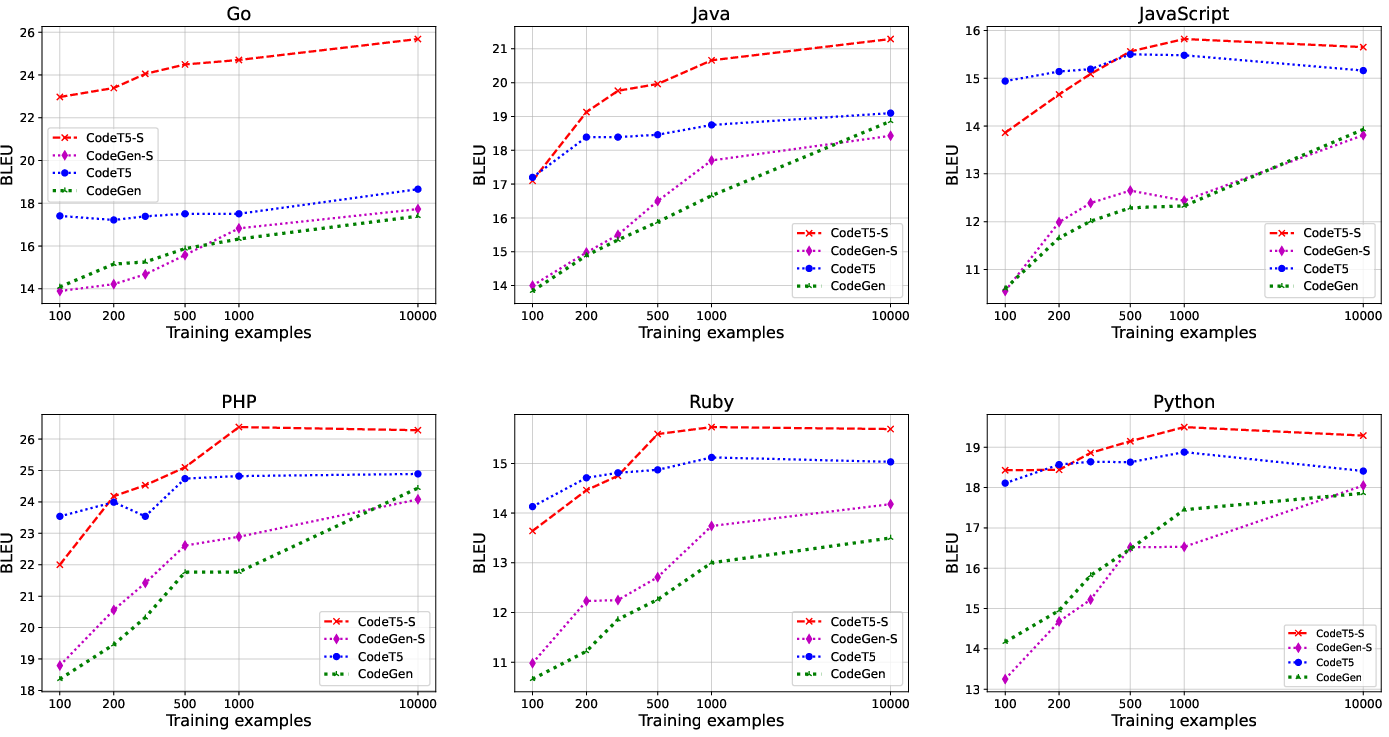
Figure 3: Code summarization performance on the CodeSearchNet benchmark.
Implications and Future Directions
The integration of CSTs into code LLMs offers a compelling means to leverage existing structured information, enabling more accurate and efficient code processing. Future advancements might explore further structural enhancements and decoding strategies, such as exploiting additional representations like control flow graphs or data flow models, potentially increasing adaptability across more diverse programming landscapes.
The methodology also suggests avenues in the creation and application of LLMs tailored to domain-specific languages, where data availability and linguistic structure pose unique challenges.
Conclusion
The paper underscores how structured representations can mitigate limitations of traditional text-based processing in code LLMs, fostering more robust model adaptations and establishing foundations for sustained research into structural leveraging in AI model design. The demonstrated improvements herald promising developments for both theoretical exploration and practical application within coding and software development contexts.