- The paper demonstrates that tuning learning rates for adaptive optimizers like AdamW and Nadam yields competitive performance on multiple GLUE tasks.
- Methodology involved systematic hyperparameter tuning, comparing full tuning with learning-rate-only approaches on DistilBERT and DistilRoBERTa models.
- Practical implications suggest that limited tuning can optimize computational efficiency while SGDM remains a viable option under resource constraints.
The paper "Should I try multiple optimizers when fine-tuning pre-trained Transformers for NLP tasks? Should I tune their hyperparameters?" explores the impact of various optimizers and their hyperparameters when fine-tuning pre-trained Transformers for NLP tasks (2402.06948). The authors systematically analyze the effects of these choices using multiple GLUE tasks, evaluating changes in test performance and computational efficiency.
Methodology and Experimental Setup
The authors conducted their study on five GLUE tasks, utilizing two models—DistilBERT and DistilRoBERTa. Seven popular optimizers were tested: SGD, SGD with Momentum (SGDM), Adam, AdaMax, Nadam, AdamW, and AdaBound. For each optimizer and task, extensive hyperparameter tuning was performed using Optuna's optimization framework, with both full hyperparameter tuning and learning rate-only tuning being assessed.
The utilization of hyperparameter optimization was specifically geared toward achieving better performance by exploring a range of values for learning rates, momentum, and other optimization-specific parameters. The experiments included scenarios with default hyperparameters as well to establish baseline performances.
The results indicated that adaptive optimizers such as Adam, AdamW, and Nadam generally offered similar test performance, provided the hyperparameters were appropriately tuned. Significant findings demonstrated that tuning only the learning rate often sufficed to achieve competitive performance, offering a balance between computational cost and output quality. This characteristic makes it feasible for practitioners with limited resources to achieve substantial outcomes without exhaustive tuning.

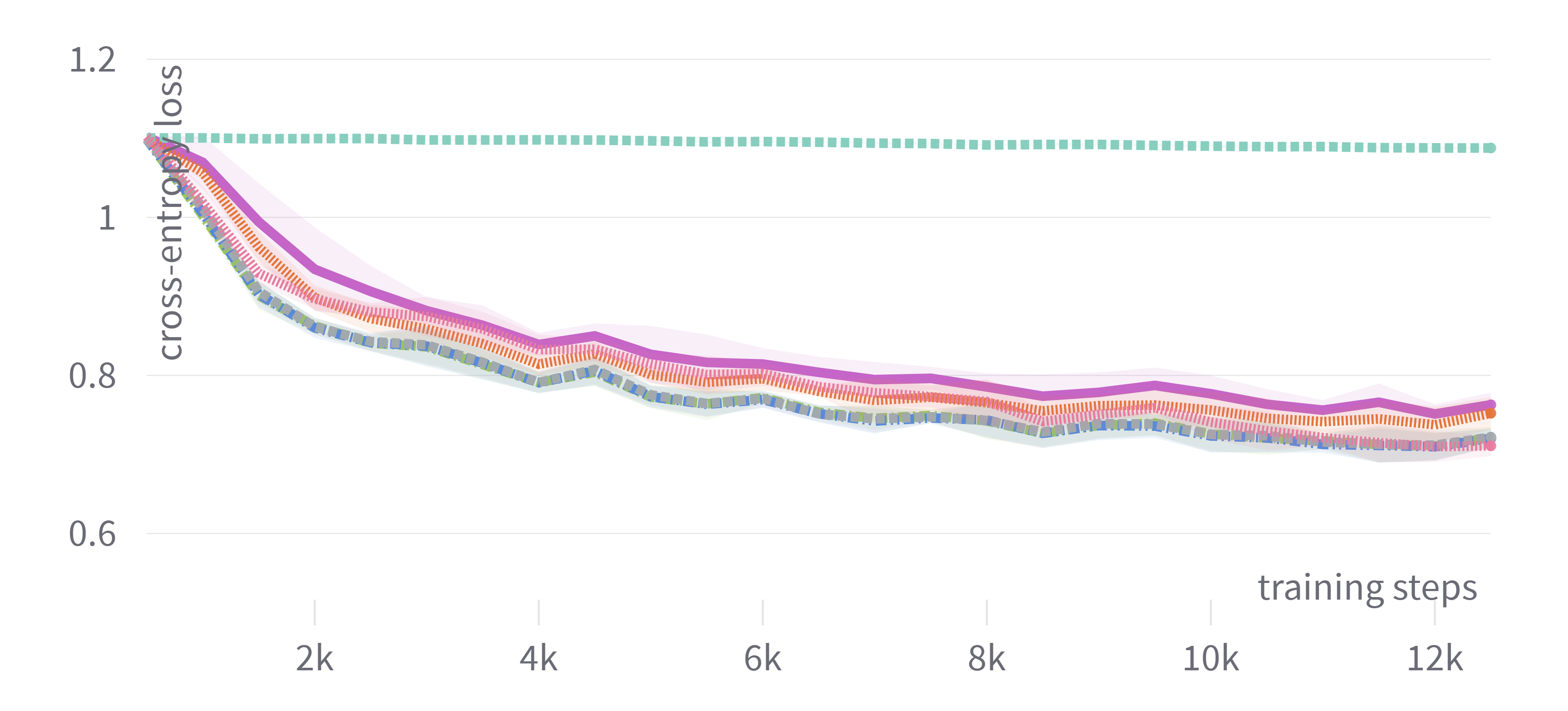
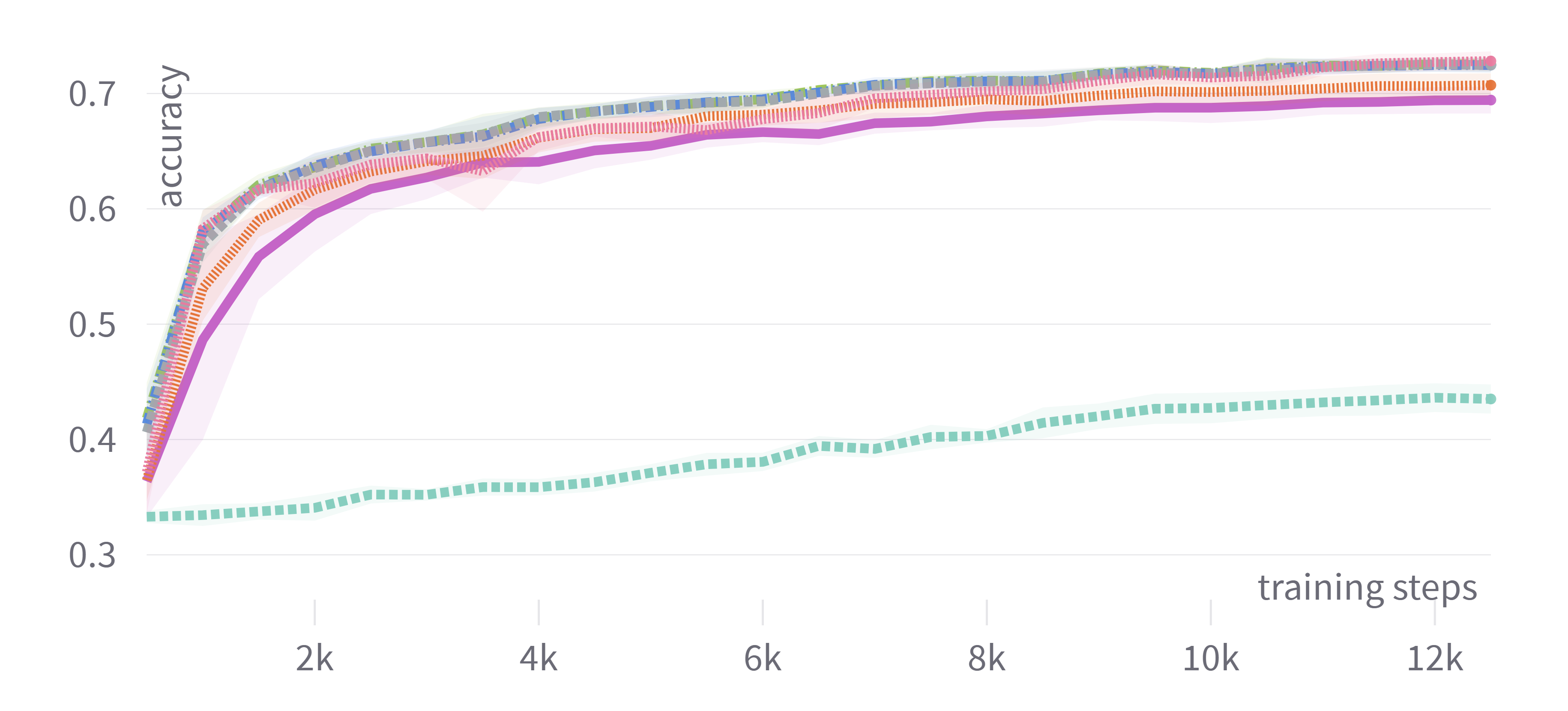
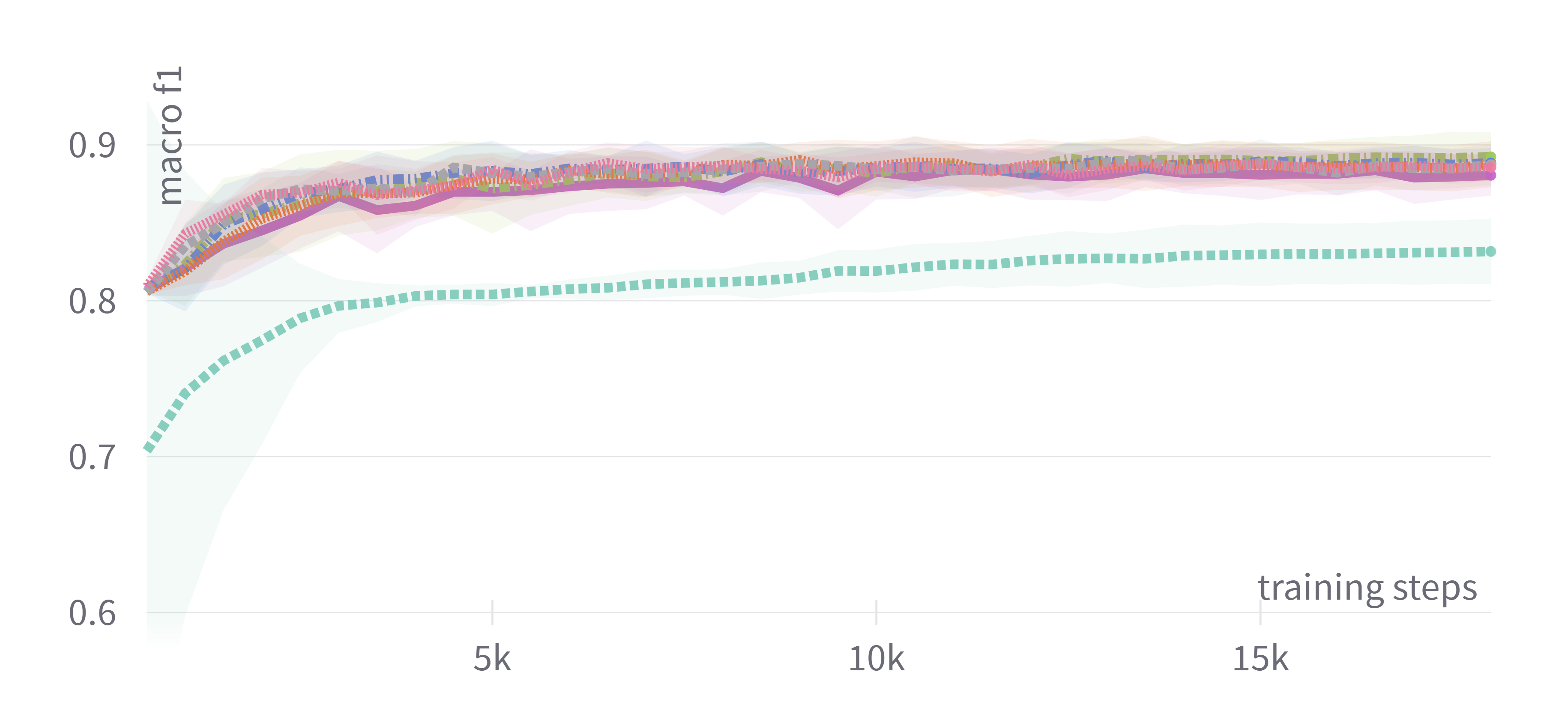
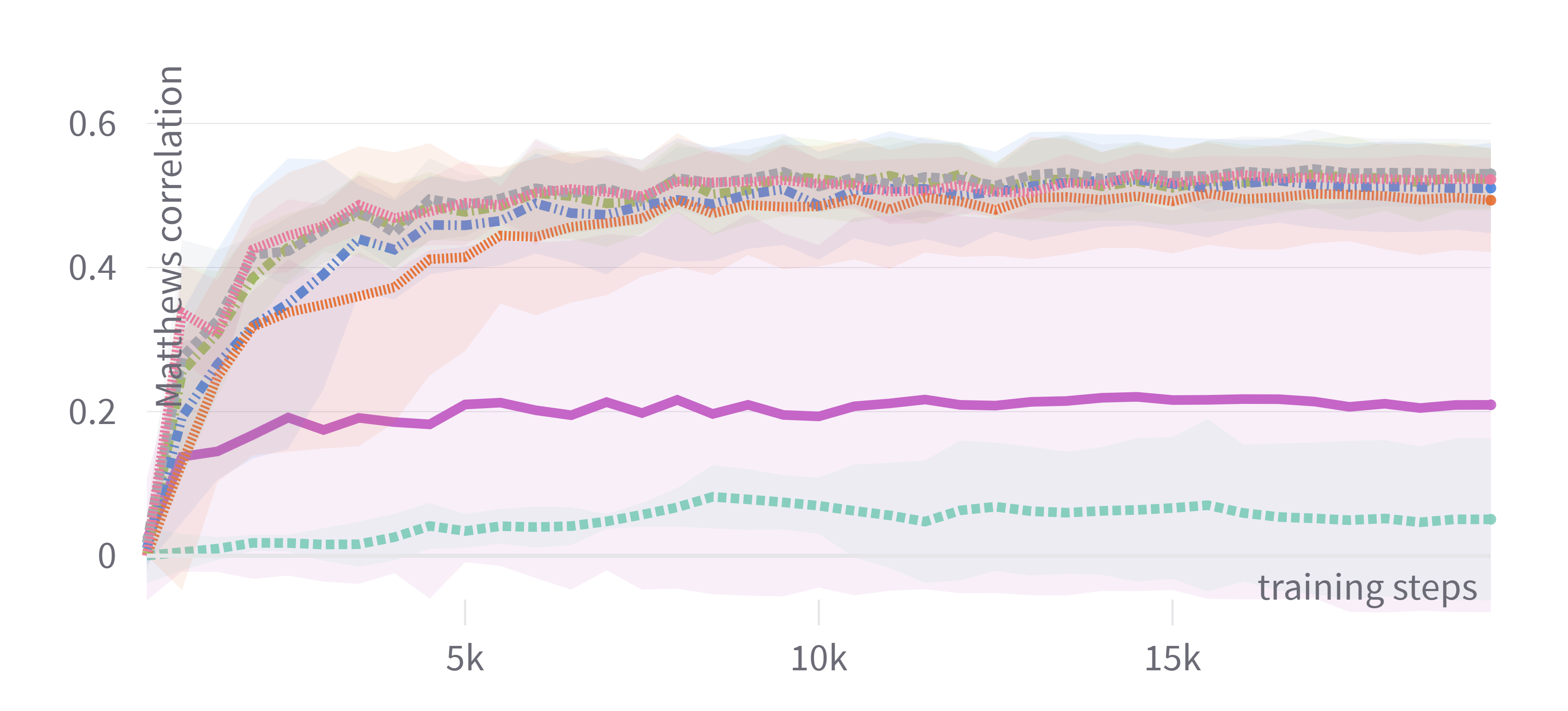
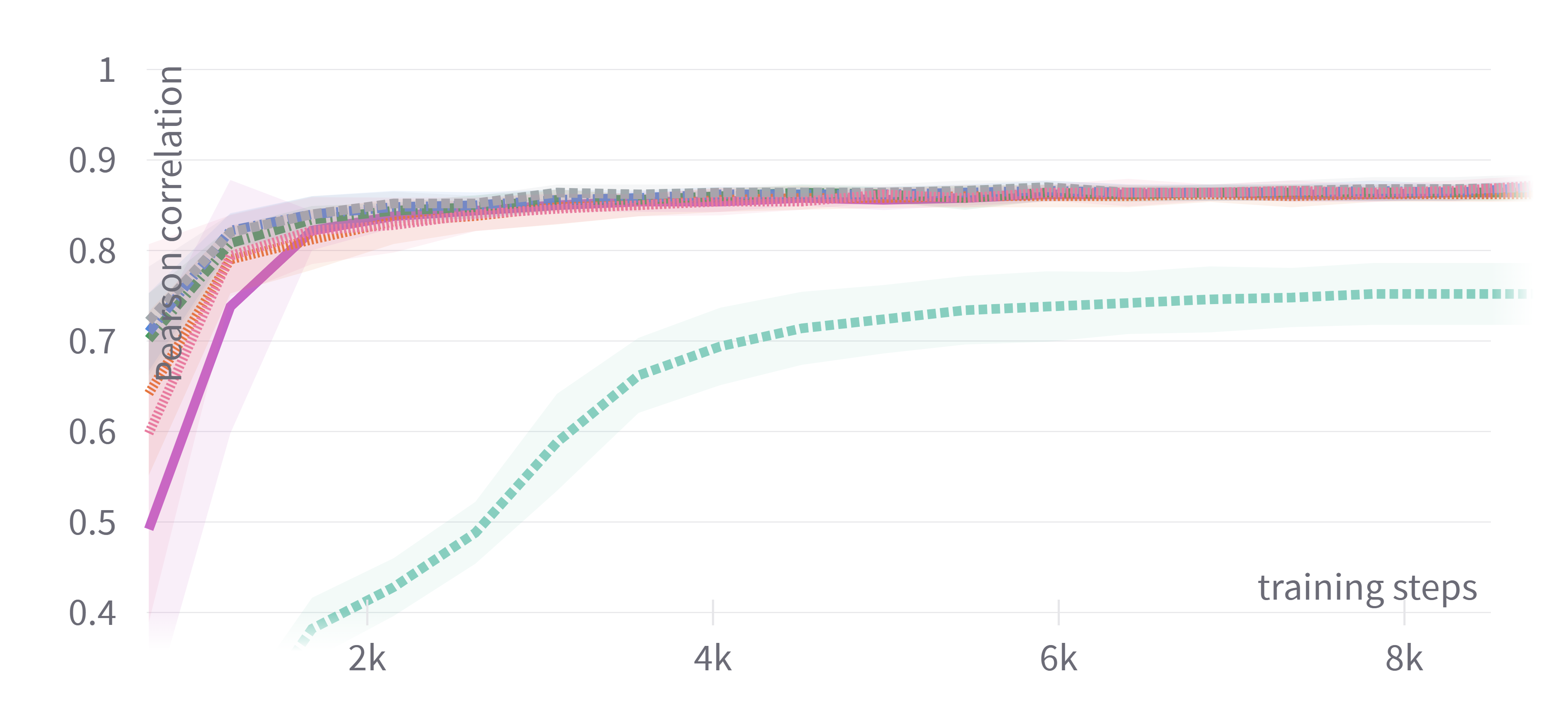
Figure 1: Training loss and evaluation scores for DistilBERT showing consistent performance among adaptive optimizers with tuned hyperparameters.
In contrast, non-adaptive optimizers like plain SGD were less effective even with tuned hyperparameters, significantly lagging in performance. Nevertheless, the introduction of momentum in SGDM enhanced its competitiveness, but primarily only when hyperparameters were tuned comprehensively.
Insights and Practical Implications
For practitioners, the study suggests focusing first on tuning the learning rate of an adaptive optimizer, with AdamW and Nadam identified as reliable choices owing to their consistent top performance across evaluations. The observations imply that comprehensive hyperparameter tuning may not be necessary in many instances, reducing computational demands.
Furthermore, when utilizing optimizers with their default settings due to resource constraints, SGDM emerges as a viable option, given its ability to perform reasonably well across multiple datasets, especially when no tuning is feasible.
Conclusion
The research provides valuable guidance for the application of optimizers in fine-tuning tasks involving Transformers for NLP. It underscores the importance of discerning efficient hyperparameter tuning strategies, especially in constrained computational settings. Future work should explore broader model architectures, additional NLP tasks, and varying budgets to corroborate and expand upon these findings. The study contributes to the ongoing effort to optimize and streamline the application of deep learning methods in real-world scenarios.