- The paper introduces SoftQE, a method that learns query representations by offline estimating LLM-generated expansions for dense retrieval.
- It employs a dual-encoder strategy with contrastive and distillation losses to align expanded query and original query embeddings.
- Experimental results show marginal improvements in-domain and a 2.83 percentage point gain on out-of-domain BEIR tasks, confirming its robustness.
SoftQE: Learned Representations of Queries Expanded by LLMs
Introduction
"SoftQE: Learned Representations of Queries Expanded by LLMs" introduces a novel method, Soft Query Expansion (SoftQE), aiming to incorporate LLMs into query encoders for dense retrieval systems. This approach seeks to improve retrieval performance by leveraging LLM-expansions without the latency and cost overheads typically associated with LLMs during inference. While improvements over strong baselines on in-domain MS-MARCO metrics are marginal, SoftQE achieves notable enhancement of 2.83 percentage points on various out-of-domain BEIR tasks.
SoftQE Methodology
The SoftQE framework is built upon the premise that while LLM-based query expansions provide semantic depth to queries, deploying these models during runtime is often impractical. SoftQE circumvents this by learning to estimate the representations of LLM query expansions offline.
A key component is forming expanded queries, denoted as q+, by appending pseudo-documents d′ generated by the LLM to the original query q. These pseudo-documents mimic real corpus passages and offer semantic enrichment for dense retrieval models.
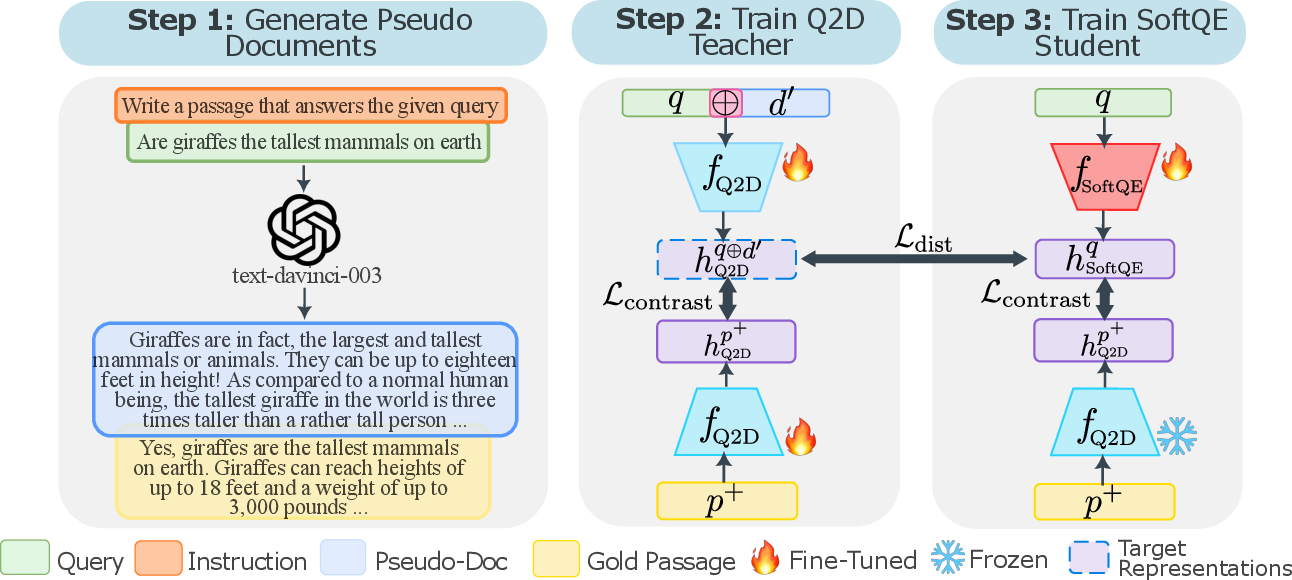
Figure 1: Overview of the SoftQE approach. Step 1: Given a query, prompt an LLM to generate a pseudo-document d′, as in Q2D.
Dual-Encoder Strategy
SoftQE employs a dual-encoder system optimized with a contrastive objective complemented by a distillation loss. The contrastive loss focuses on embedding alignment between queries and their expanded counterparts. An additional metric, mean squared error (MSE), ensures the student encoder aligns closely to the target representations from the teacher model.
The SoftQE objective function is:
$\mathcal{L}_{\text{SoftQE}} = \alpha \mathcal{L}_{\text{dist}(f_{\theta}(q^+), f_{\psi}(q)) + (1 - \alpha) \mathcal{L}_{\text{cont}},$
where α balances alignment between expanded query and original query representations.
Experimental Results
In-Domain Evaluation
SoftQE demonstrates consistent improvement over baseline dense retrieval models like DPR and SimLM on the MS-MARCO and TREC DL datasets. Despite marginal differences, SoftQE proves effective, indicating that LLM-based expansion complements sophisticated dual-encoder designs.
Out-of-Domain Evaluation
Zero-shot performance evaluations on BEIR tasks reveal substantial gains, affirming SoftQE's robustness in cross-domain settings. This suggests the method efficiently distills semantic information beyond initial training corpora, a significant advantage in real-world retrieval applications.
Discussion
Objective Balancing
Various configurations of the SoftQE training loss were explored. Optimal settings involve using a "warm-up" strategy where initially α is set entirely towards distillation, followed by combined optimization. This approach ensures robust alignment with target embeddings while maintaining retrieval accuracy.
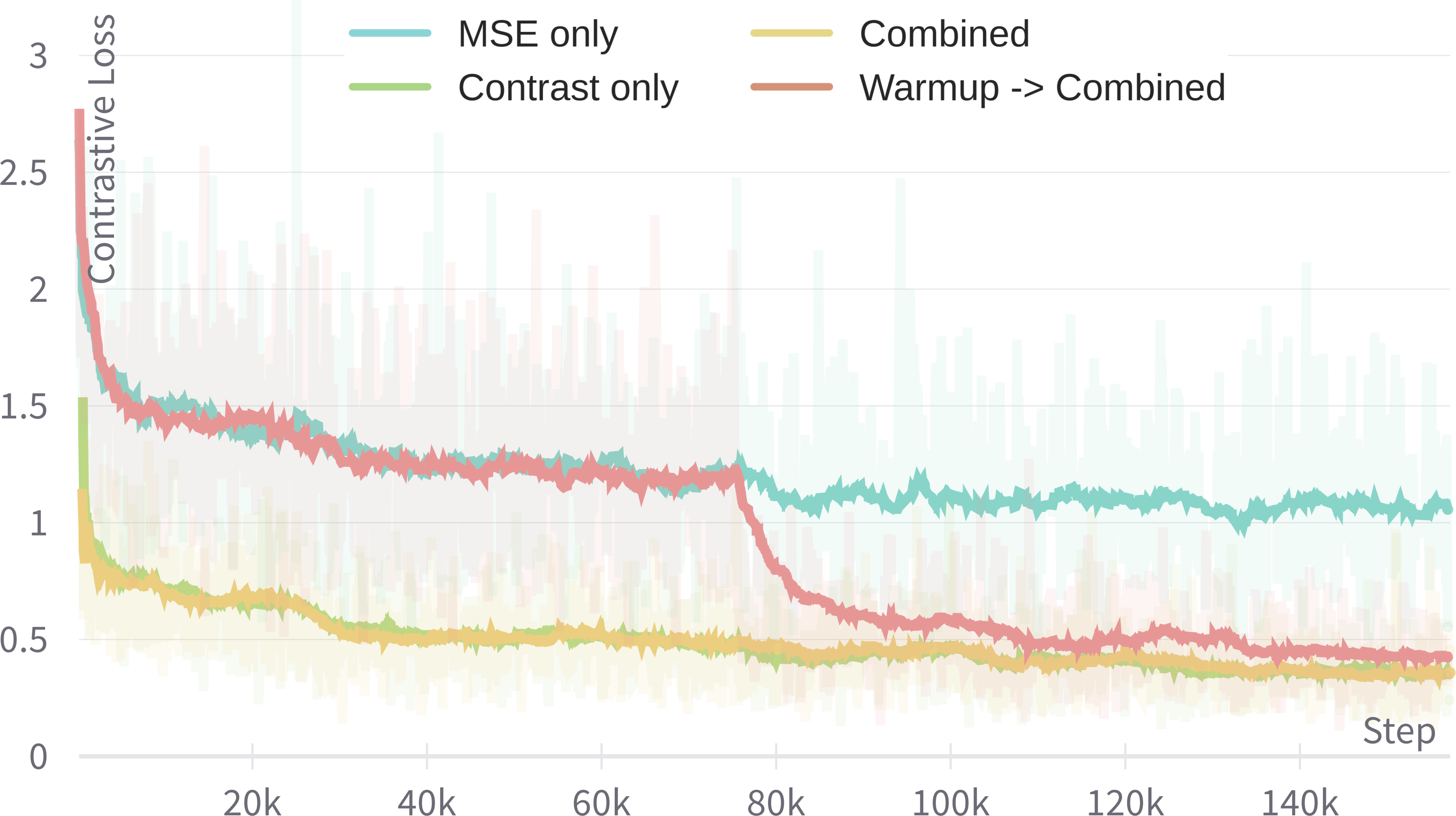
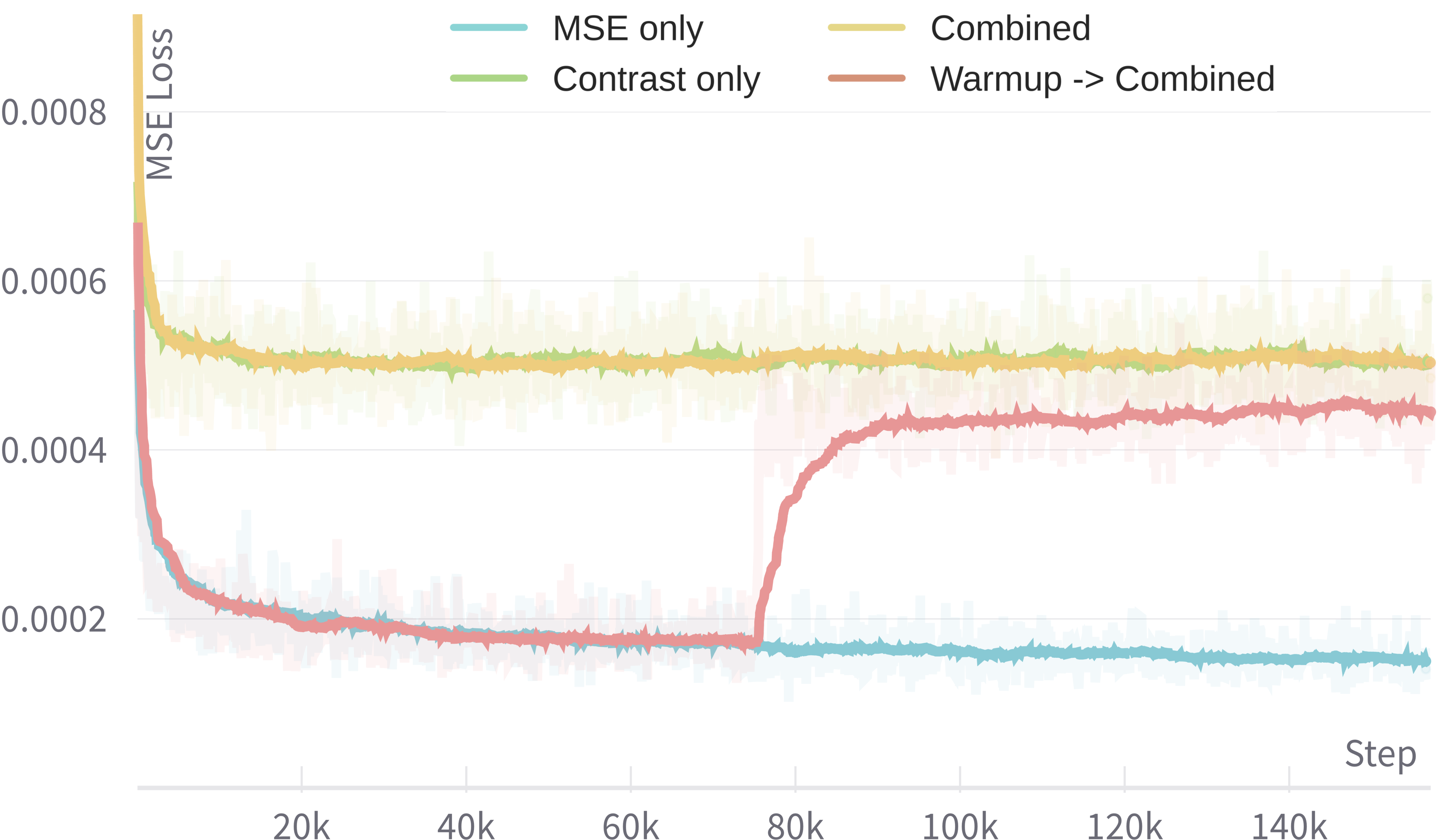
Figure 2: Training curves of four settings of α, illustrating the impact on contrastive and MSE losses.
Independence in Encoder Training
Unfreezing the passage encoder during training showed reduced retrieval efficacy. This result validates SoftQE's reliance on the established Q2D feature space for consistent passage-query embedding alignment, maintaining high-performance retrieval benchmarks.
Implications and Future Work
SoftQE presents a compelling case for integrating LLM-based expansions into dense retrieval systems without runtime overheads. Future research could explore enhanced prompt strategies, potentially leveraging larger architectures like ColBERTv2 for further improvements. The foundational concept of distilling knowledge through LLM-generated naturallanguage inputs opens avenues for optimizing diverse tasks within the field of AI retrieval frameworks.
Conclusion
SoftQE effectively aligns query representations with their expanded forms, optimizing retrieval performance significantly, especially in zero-shot scenarios. This methodology bypasses the runtime costs of LLMs, offering practical advantages in real-time systems. Continued advancements in prompting strategies and application to high-capacity retrieval models hold promise for broader implementations.