- The paper presents a novel query expansion method using an evolving thinking process to surface latent concepts and improve retrieval diversity.
- It utilizes iterative corpus interaction to refine the query in multiple rounds, enhancing semantic coverage and reducing redundancy.
- Experimental results on TREC DL and BRIGHT benchmarks demonstrate superior performance in zero-shot settings with high mAP and ndcg@10 scores.
ThinkQE: Query Expansion via an Evolving Thinking Process
ThinkQE introduces a novel query expansion framework aimed at enhancing exploration and result diversity in web search, addressing the limitations of existing methods that focus too narrowly on single aspects of a query. This paper presents ThinkQE, which utilizes a thinking-based expansion process combined with corpus interaction to iteratively refine query expansions using retrieval feedback.
Introduction
Query expansion (QE) is a critical technique in information retrieval that involves broadening and enriching the initial query to improve retrieval effectiveness. Traditional QE methodologies and retrieval models like BM25 mainly focus on reinforcing core query intent and capturing diverse facets of information needs. Despite recent advances using LLMs, existing QE approaches often fail to offer sufficient exploration and semantic diversity, resulting in expansions that are overly confident and narrow in scope.
Method
ThinkQE leverages two key innovations:
- Thinking-based Expansion: The LLM generates expansions using an explicit thinking chain to surface latent concepts and alternative interpretations. The process begins with retrieving initial documents via BM25, serving as the grounding context.
- Corpus Interaction: The expansion dynamically evolves through multiple iterative rounds of retrieval-feedback interaction, allowing the query to adapt and refine based on new evidence. This iterative loop ensures expanding the semantic scope and capturing diverse relevant documents.
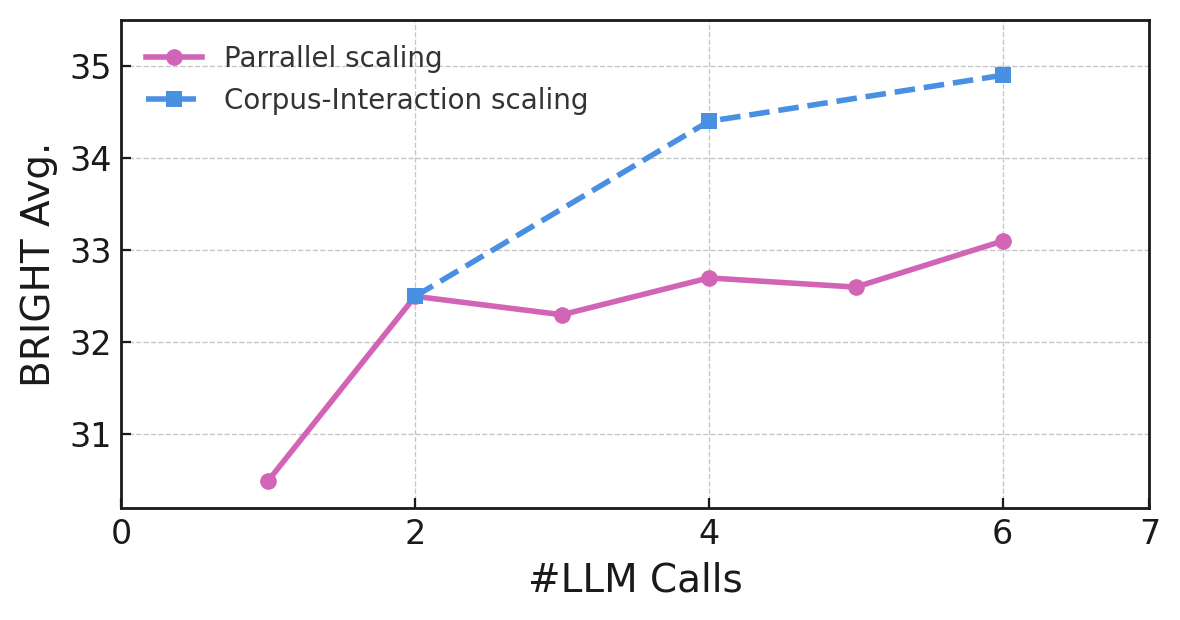
Figure 1: Impact of evolving corpus interaction process.
The query expansion proceeds as follows:
- Initial Retrieval: Begin by retrieving top-K documents using BM25 to serve as context.
- Thinking and Expansion: Generate expansions in a two-phase process (thinking followed by expansion), facilitated by a model trained to articulate reasoning chains.
- Iterative Retrieval and Redundancy Filtering: Iterative expansion involves progressively refining the query using feedback from newly retrieved documents, with redundancy filtering to promote diversity.
- Expansion Accumulation: Concatenate expansions across rounds to form the updated query while mitigating the dilution of original query meaning.
Experimental Results
ThinkQE was evaluated on TREC DL benchmarks and the BRIGHT benchmark, demonstrating superior performance compared to other methods, especially in zero-shot settings. Key findings included:
- DL Benchmarks: ThinkQE outperformed zero-shot expansion methods, achieving top scores in metrics like mAP, ndcg@10, and R@1k.
- BRIGHT Benchmark: The framework excelled in reasoning-oriented sub-domains, achieving competitive results despite being a training-free method.
Analysis
Impact of Thinking Process
Ablation studies confirmed the necessity of the explicit thinking process in enhancing the quality of query expansions. Models incorporating thinking-based reasoning significantly outperformed variants without this component.
Corpus Interaction Strategy
The evolving corpus interaction proved effective, outperforming static expansion strategies by iteratively refining queries based on newly retrieved documents. This dynamic approach facilitated enhanced diversity and coverage.
Redundancy Filtering and Expansion Accumulation
These mechanisms are critical for maximizing retrieval performance. Expansion accumulation enabled building upon prior expansions, while redundancy filtering promoted diverse document retrieval across iterative rounds.
Conclusion
ThinkQE provides a robust method for query expansion, seamlessly integrating LLM-based thinking and dynamic corpus interaction. This framework not only enhances exploration and diversity at test-time but also achieves strong competitive performance across diverse benchmarks without requiring additional training.
Limitations
Despite its advantages, ThinkQE introduces higher latency and computational cost at inference time. Its suitability for multilingual search tasks remains to be evaluated. Furthermore, scaling ThinkQE for production use may require addressing these computational constraints.
The advancements presented by ThinkQE offer valuable insights for future research in query expansion and its applications in AI-driven retrieval systems.