OneActor: Consistent Character Generation via Cluster-Conditioned Guidance
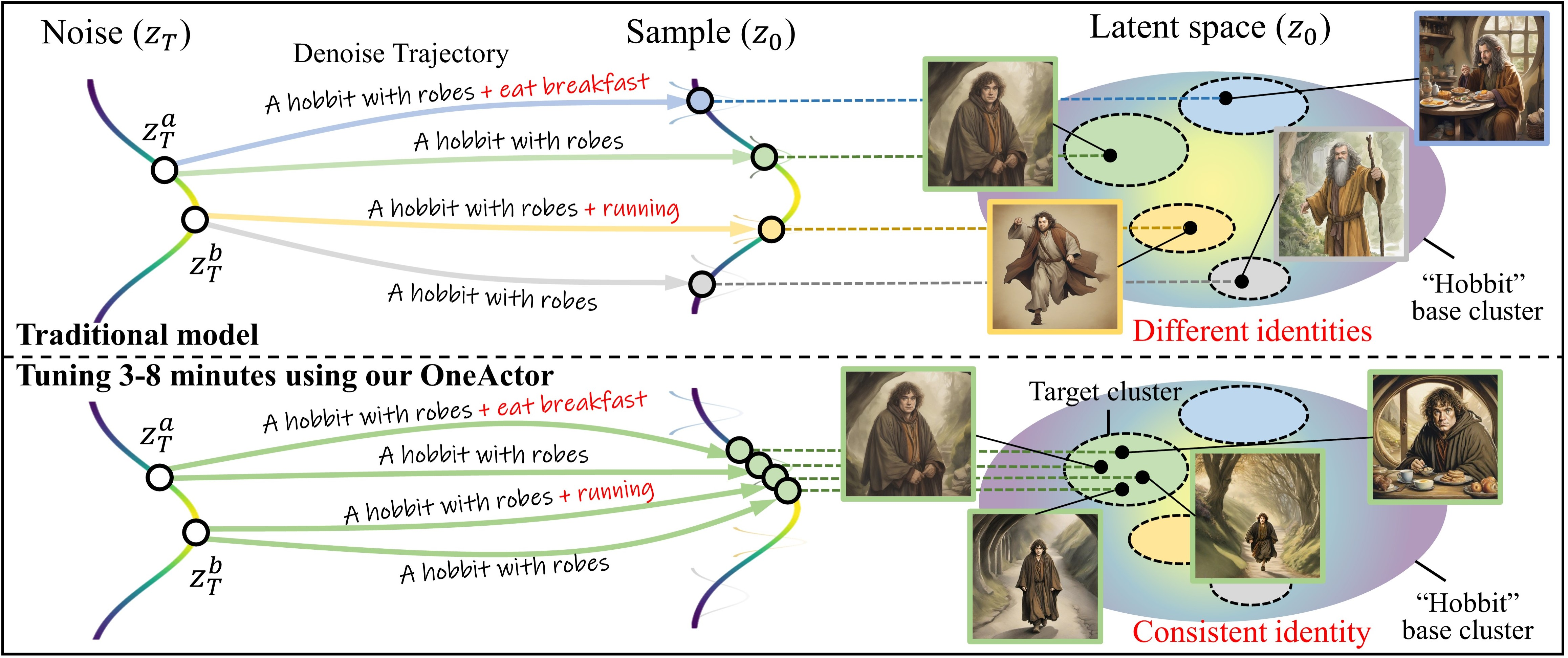
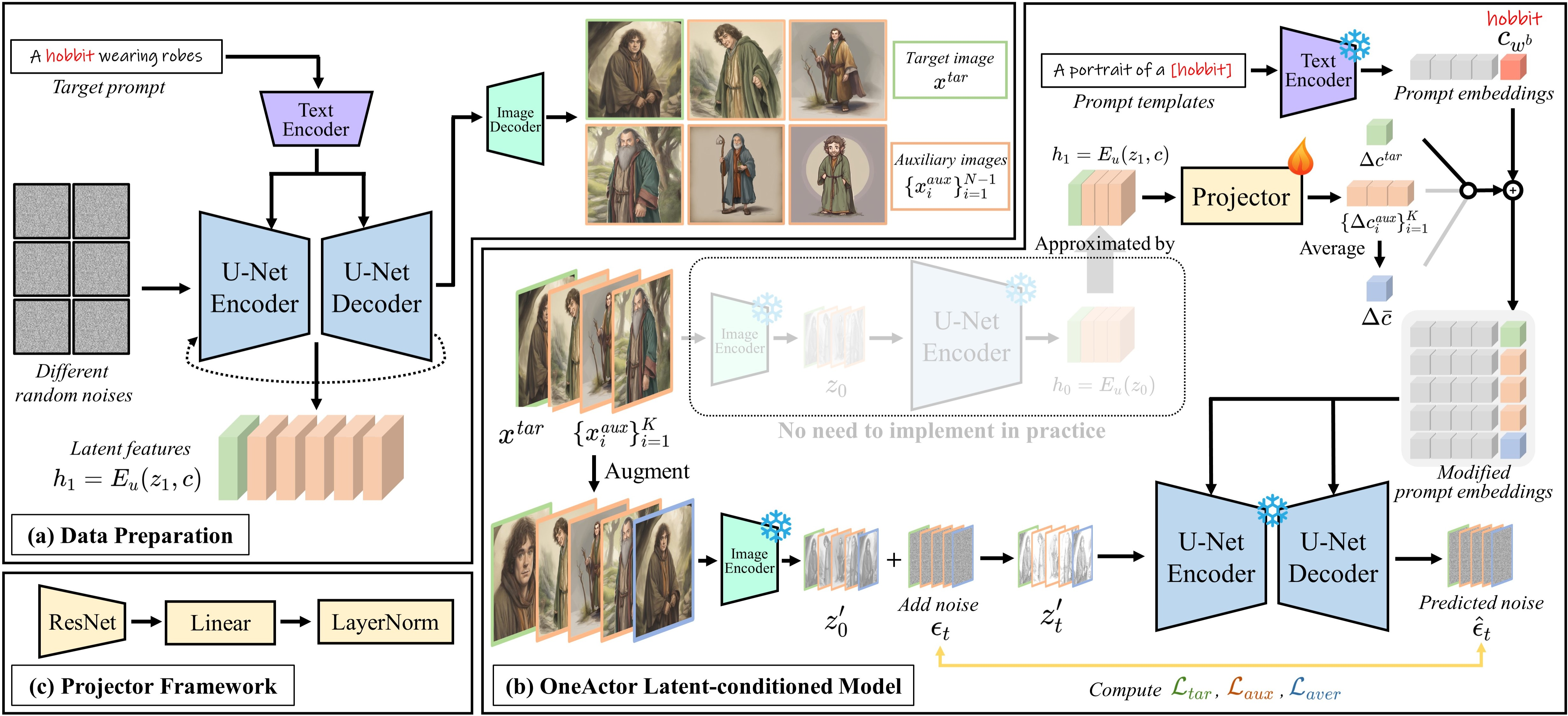
Abstract: Text-to-image diffusion models benefit artists with high-quality image generation. Yet their stochastic nature hinders artists from creating consistent images of the same subject. Existing methods try to tackle this challenge and generate consistent content in various ways. However, they either depend on external restricted data or require expensive tuning of the diffusion model. For this issue, we propose a novel one-shot tuning paradigm, termed OneActor. It efficiently performs consistent subject generation solely driven by prompts via a learned semantic guidance to bypass the laborious backbone tuning. We lead the way to formalize the objective of consistent subject generation from a clustering perspective, and thus design a cluster-conditioned model. To mitigate the overfitting challenge shared by one-shot tuning pipelines, we augment the tuning with auxiliary samples and devise two inference strategies: semantic interpolation and cluster guidance. These techniques are later verified to significantly improve the generation quality. Comprehensive experiments show that our method outperforms a variety of baselines with satisfactory subject consistency, superior prompt conformity as well as high image quality. Our method is capable of multi-subject generation and compatible with popular diffusion extensions. Besides, we achieve a 4 times faster tuning speed than tuning-based baselines and, if desired, avoid increasing the inference time. Furthermore, our method can be naturally utilized to pre-train a consistent subject generation network from scratch, which will implement this research task into more practical applications. (Project page: https://johnneywang.github.io/OneActor-webpage/)
- Denoising diffusion probabilistic models. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html.
- SDXL: improving latent diffusion models for high-resolution image synthesis. CoRR, abs/2307.01952, 2023. doi:10.48550/ARXIV.2307.01952. URL https://doi.org/10.48550/arXiv.2307.01952.
- An image is worth one word: Personalizing text-to-image generation using textual inversion. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023a. URL https://openreview.net/pdf?id=NAQvF08TcyG.
- Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 22500–22510. IEEE, 2023. doi:10.1109/CVPR52729.2023.02155. URL https://doi.org/10.1109/CVPR52729.2023.02155.
- Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. CoRR, abs/2308.06721, 2023. doi:10.48550/ARXIV.2308.06721. URL https://doi.org/10.48550/arXiv.2308.06721.
- ELITE: encoding visual concepts into textual embeddings for customized text-to-image generation. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 15897–15907. IEEE, 2023. doi:10.1109/ICCV51070.2023.01461. URL https://doi.org/10.1109/ICCV51070.2023.01461.
- Storydall-e: Adapting pretrained text-to-image transformers for story continuation. In Shai Avidan, Gabriel J. Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors, Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXXVII, volume 13697 of Lecture Notes in Computer Science, pages 70–87. Springer, 2022. doi:10.1007/978-3-031-19836-6_5. URL https://doi.org/10.1007/978-3-031-19836-6_5.
- Make-a-story: Visual memory conditioned consistent story generation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 2493–2502. IEEE, 2023. doi:10.1109/CVPR52729.2023.00246. URL https://doi.org/10.1109/CVPR52729.2023.00246.
- The chosen one: Consistent characters in text-to-image diffusion models. arXiv preprint arXiv:2311.10093, 2023a.
- Concept decomposition for visual exploration and inspiration. ACM Trans. Graph., 42(6):241:1–241:13, 2023. doi:10.1145/3618315. URL https://doi.org/10.1145/3618315.
- Break-a-scene: Extracting multiple concepts from a single image. In June Kim, Ming C. Lin, and Bernd Bickel, editors, SIGGRAPH Asia 2023 Conference Papers, SA 2023, Sydney, NSW, Australia, December 12-15, 2023, pages 96:1–96:12. ACM, 2023b. doi:10.1145/3610548.3618154. URL https://doi.org/10.1145/3610548.3618154.
- A neural space-time representation for text-to-image personalization. ACM Trans. Graph., 42(6):243:1–243:10, 2023. doi:10.1145/3618322. URL https://doi.org/10.1145/3618322.
- Svdiff: Compact parameter space for diffusion fine-tuning. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 7289–7300. IEEE, 2023. doi:10.1109/ICCV51070.2023.00673. URL https://doi.org/10.1109/ICCV51070.2023.00673.
- Multi-concept customization of text-to-image diffusion. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 1931–1941. IEEE, 2023. doi:10.1109/CVPR52729.2023.00192. URL https://doi.org/10.1109/CVPR52729.2023.00192.
- Key-locked rank one editing for text-to-image personalization. In Erik Brunvand, Alla Sheffer, and Michael Wimmer, editors, ACM SIGGRAPH 2023 Conference Proceedings, SIGGRAPH 2023, Los Angeles, CA, USA, August 6-10, 2023, pages 12:1–12:11. ACM, 2023. doi:10.1145/3588432.3591506. URL https://doi.org/10.1145/3588432.3591506.
- Encoder-based domain tuning for fast personalization of text-to-image models. ACM Trans. Graph., 42(4):150:1–150:13, 2023b. doi:10.1145/3592133. URL https://doi.org/10.1145/3592133.
- Subject-driven text-to-image generation via apprenticeship learning. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/6091bf1542b118287db4088bc16be8d9-Abstract-Conference.html.
- Domain-agnostic tuning-encoder for fast personalization of text-to-image models. In June Kim, Ming C. Lin, and Bernd Bickel, editors, SIGGRAPH Asia 2023 Conference Papers, SA 2023, Sydney, NSW, Australia, December 12-15, 2023, pages 72:1–72:10. ACM, 2023. doi:10.1145/3610548.3618173. URL https://doi.org/10.1145/3610548.3618173.
- Classifier-free diffusion guidance. CoRR, abs/2207.12598, 2022. doi:10.48550/ARXIV.2207.12598. URL https://doi.org/10.48550/arXiv.2207.12598.
- Compositional inversion for stable diffusion models. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors, Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, pages 7350–7358. AAAI Press, 2024. doi:10.1609/AAAI.V38I7.28565. URL https://doi.org/10.1609/aaai.v38i7.28565.
- Zero-shot image-to-image translation. In Erik Brunvand, Alla Sheffer, and Michael Wimmer, editors, ACM SIGGRAPH 2023 Conference Proceedings, SIGGRAPH 2023, Los Angeles, CA, USA, August 6-10, 2023, pages 11:1–11:11. ACM, 2023. doi:10.1145/3588432.3591513. URL https://doi.org/10.1145/3588432.3591513.
- Visual instruction inversion: Image editing via image prompting. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/1e75f7539cbde5de895fab238ff42519-Abstract-Conference.html.
- Deep unsupervised learning using nonequilibrium thermodynamics. In Francis R. Bach and David M. Blei, editors, Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015, volume 37 of JMLR Workshop and Conference Proceedings, pages 2256–2265. JMLR.org, 2015. URL http://proceedings.mlr.press/v37/sohl-dickstein15.html.
- U-net: Convolutional networks for biomedical image segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells III, and Alejandro F. Frangi, editors, Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015 - 18th International Conference Munich, Germany, October 5 - 9, 2015, Proceedings, Part III, volume 9351 of Lecture Notes in Computer Science, pages 234–241. Springer, 2015. doi:10.1007/978-3-319-24574-4_28. URL https://doi.org/10.1007/978-3-319-24574-4_28.
- High-resolution image synthesis with latent diffusion models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 10674–10685. IEEE, 2022. doi:10.1109/CVPR52688.2022.01042. URL https://doi.org/10.1109/CVPR52688.2022.01042.
- Score-based generative modeling through stochastic differential equations. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URL https://openreview.net/forum?id=PxTIG12RRHS.
- Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, pages 770–778. IEEE Computer Society, 2016. doi:10.1109/CVPR.2016.90. URL https://doi.org/10.1109/CVPR.2016.90.
- Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Blip-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/602e1a5de9c47df34cae39353a7f5bb1-Abstract-Conference.html.
- Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 of Proceedings of Machine Learning Research, pages 8748–8763. PMLR, 2021. URL http://proceedings.mlr.press/v139/radford21a.html.
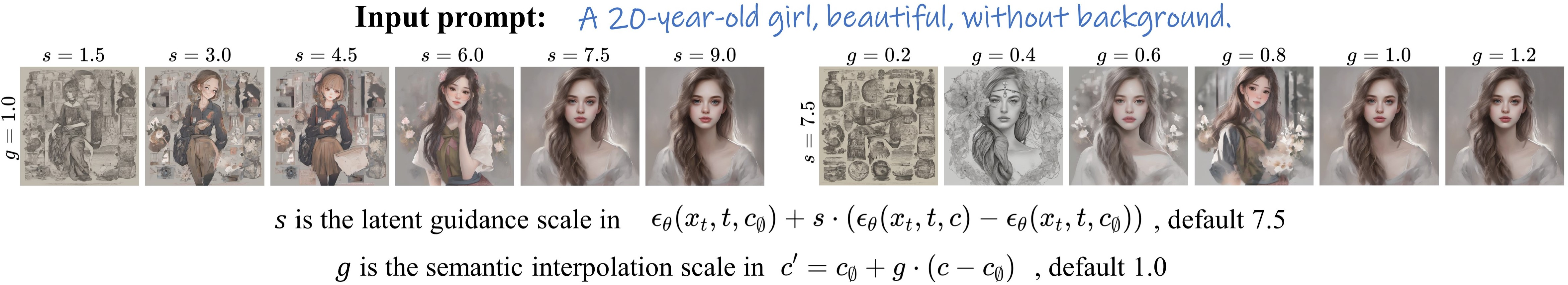
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.