Towards Reliable Latent Knowledge Estimation in LLMs: Zero-Prompt Many-Shot Based Factual Knowledge Extraction
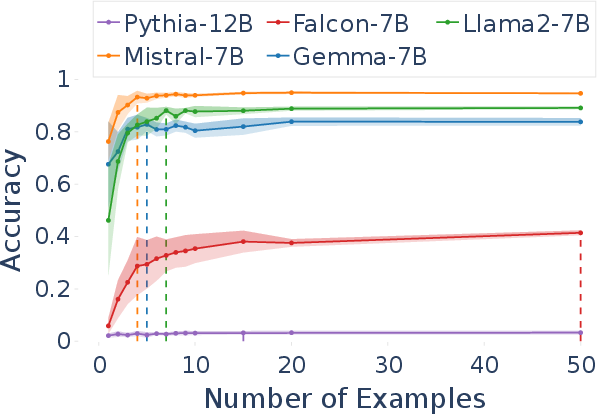
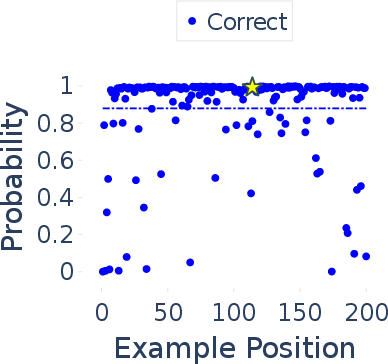
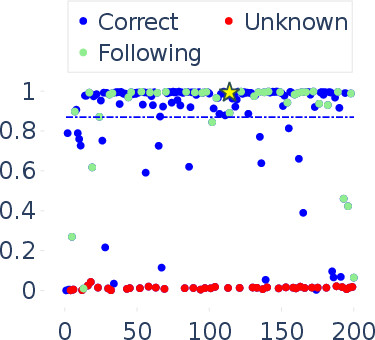
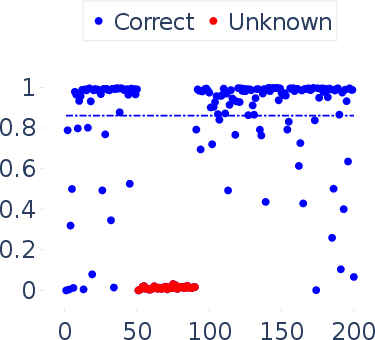
Abstract: In this paper, we focus on the challenging task of reliably estimating factual knowledge that is embedded inside LLMs. To avoid reliability concerns with prior approaches, we propose to eliminate prompt engineering when probing LLMs for factual knowledge. Our approach, called Zero-Prompt Latent Knowledge Estimator (ZP-LKE), leverages the in-context learning ability of LLMs to communicate both the factual knowledge question as well as the expected answer format. Our knowledge estimator is both conceptually simpler (i.e., doesn't depend on meta-linguistic judgments of LLMs) and easier to apply (i.e., is not LLM-specific), and we demonstrate that it can surface more of the latent knowledge embedded in LLMs. We also investigate how different design choices affect the performance of ZP-LKE. Using the proposed estimator, we perform a large-scale evaluation of the factual knowledge of a variety of open-source LLMs, like OPT, Pythia, Llama(2), Mistral, Gemma, etc. over a large set of relations and facts from the Wikidata knowledge base. We observe differences in the factual knowledge between different model families and models of different sizes, that some relations are consistently better known than others but that models differ in the precise facts they know, and differences in the knowledge of base models and their finetuned counterparts. Code available at: https://github.com/QinyuanWu0710/ZeroPrompt_LKE
- Ask me anything: A simple strategy for prompting language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR.
- Inducing relational knowledge from bert. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7456–7463.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Discovering Latent Knowledge in Language Models Without Supervision. arXiv preprint. ArXiv:2212.03827 [cs].
- FacTool: Factuality Detection in Generative AI – A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios. arXiv preprint. ArXiv:2307.13528 [cs] version: 2.
- T-rex: A large scale alignment of natural language with knowledge base triples. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018).
- Promptbreeder: Self-referential self-improvement via prompt evolution. Preprint, arXiv:2309.16797.
- Jennifer Hu and Roger Levy. 2023. Prompting is not a substitute for probability measurements in large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5040–5060.
- RefChecker for fine-grained hallucination detection.
- Do large language models know about facts? arXiv preprint arXiv:2310.05177.
- Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.
- How can we know when language models know? on the calibration of language models for question answering. Transactions of the Association for Computational Linguistics, 9:962–977.
- How can we know what language models know? Transactions of the Association for Computational Linguistics, 8:423–438.
- Measuring the knowledge acquisition-utilization gap in pretrained language models. arXiv preprint arXiv:2305.14775.
- Evaluating the Factual Consistency of Abstractive Text Summarization. arXiv preprint. ArXiv:1910.12840 [cs].
- Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, page 611–626, New York, NY, USA. Association for Computing Machinery.
- P-adapters: Robustly extracting factual information from language models with diverse prompts. In International Conference on Learning Representations.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Check your facts and try again: Improving large language models with external knowledge and automated feedback. arXiv preprint arXiv:2302.12813.
- Language models as knowledge bases? arXiv preprint arXiv:1909.01066.
- Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. arXiv preprint arXiv:2310.11324.
- On early detection of hallucinations in factual question answering. arXiv preprint arXiv:2312.14183.
- Head-to-Tail: How Knowledgeable are Large Language Models (LLM)? A.K.A. Will LLMs Replace Knowledge Graphs? arXiv preprint. ArXiv:2308.10168 [cs].
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Language models are open knowledge graphs. arXiv preprint arXiv:2010.11967.
- Survey on factuality in large language models: Knowledge, retrieval and domain-specificity. arXiv preprint arXiv:2310.07521.
- Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- A survey on large language models for recommendation. arXiv preprint arXiv:2305.19860.
- LLM lies: Hallucinations are not bugs, but features as adversarial examples. arXiv preprint arXiv:2310.01469.
- KoLA: Carefully benchmarking world knowledge of large language models. In The Twelfth International Conference on Learning Representations.
- Why johnny can’t prompt: how non-ai experts try (and fail) to design llm prompts. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1–21.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068.
- Siren’s song in the ai ocean: A survey on hallucination in large language models. arXiv preprint arXiv:2309.01219.
- Efficiently programming large language models using sglang. Preprint, arXiv:2312.07104.
- Large language models for information retrieval: A survey. arXiv preprint arXiv:2308.07107.
- Zeyuan Allen Zhu and Yuanzhi Li. 2023. Physics of language models: Part 3.1, knowledge storage and extraction. arXiv preprint arXiv:2309.14316.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.