- The paper presents an approach using LLMs to automate honeytoken creation, reducing detection rates from 29% to 15.15% under trawling attacks.
- The study optimizes prompt structures across 210 experiments, generating various honeytoken types such as honeywords and robots.txt files.
- The research demonstrates a scalable and adaptable cybersecurity defense strategy with LLMs, suggesting promising avenues for real-time deception enhancements.
Summary of "Act as a Honeytoken Generator! An Investigation into Honeytoken Generation with LLMs"
Introduction and Background
This paper explores the application of LLMs for generating honeytokens—a cybersecurity deception technique aimed at misleading attackers. Traditional methods for creating honeytokens, while effective, are often labor-intensive and lack versatility across different types. With the advent of advanced LLMs such as GPT-4 and LLaMA2, there is an opportunity to automate the generation of diversified honeytokens, significantly enhancing scalability and adaptability in cyber defense strategies.
Honeytokens are pieces of deceptive data, such as fake passwords or bogus system files, designed to alert security systems when accessed by unauthorized users. Unlike honeypots, which are entire fake systems, honeytokens can be embedded within legitimate systems, serving as a high-efficiency, low-interaction security measure. This research leverages the capabilities of LLMs to create a variety of convincing honeytokens across different formats, including honeywords, robots.txt files, and databases.
Methodology and Experimentation
The authors employed LLMs to generate seven distinct types of honeytokens, including configuration files, databases, log files, and honeywords. The primary challenge addressed was optimizing prompt structures to efficiently generate realistic and credible honeytokens. The study tested 210 unique prompts, dissected into four core building blocks: generator instructions, user input, special instructions, and output format.
For the honeywords and robots.txt files, a rigorous evaluation was performed using custom metrics to assess plausibility and effectiveness. Honeywords were evaluated based on their indistinguishability from real passwords using a trawling guessing attack tool, while robots.txt files were compared to industry-standard metrics derived from popular website practices.
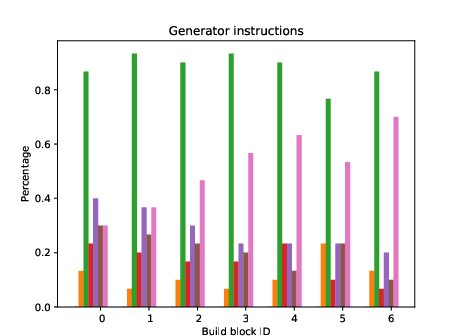
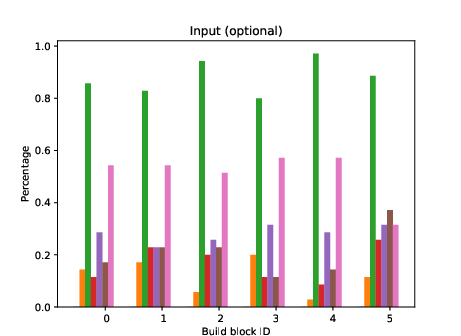
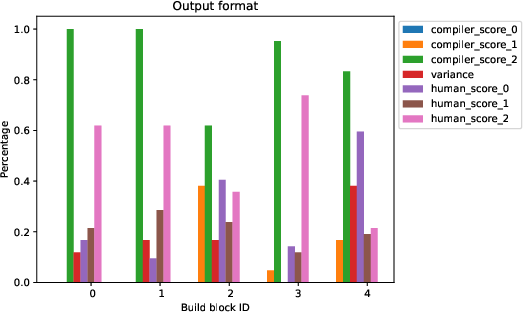
Figure 1: Analysis of change of score if one parameter is present.
Results and Discussion
The study identified optimal prompts for generating honeytokens with LLMs, demonstrating significant results in terms of realism and deception capability. Honeywords generated with the method had a 15.15% detection success rate, markedly lower than previous methods that reported upwards of 29% success rates, indicating enhanced security properties.
A comparative study across different LLMs—GPT-3.5, GPT-4, LLaMA2, and Gemini—revealed varying levels of performance, with GPT models generally producing the most well-structured and believable honeytokens. The analysis highlights the potential of LLMs in cybersecurity applications, transforming them into a versatile tool for generating diverse and complex honeytokens.
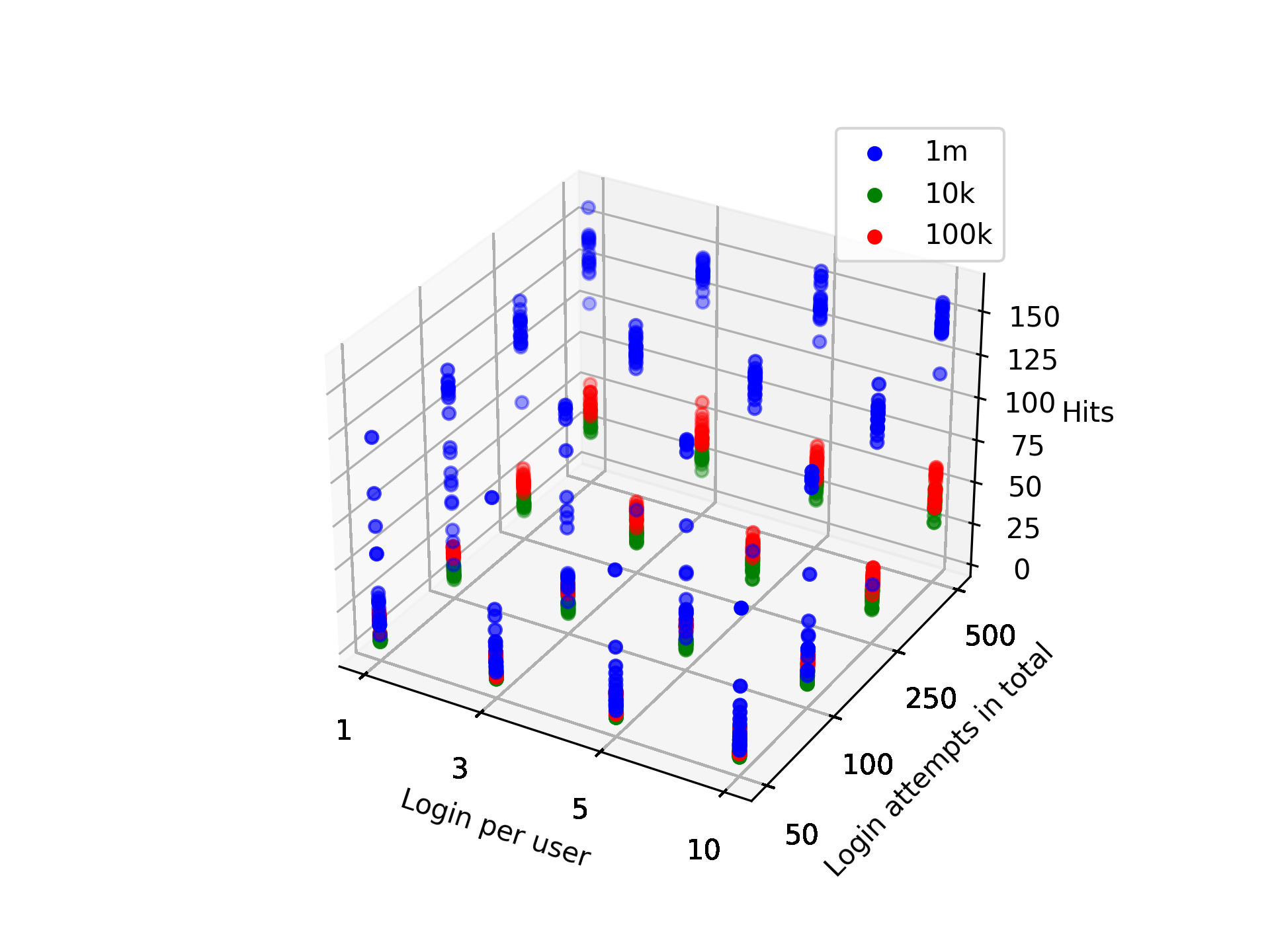
Figure 2: Hit rate of real password detection algorithm depending on maximal allowed login attempts per user and maximal total login attempts. Each color represents a different size of the training set. 1000 examples were presented, each example consisting of 1 real password and 19 honeywords generated with ChatGPT.
Implications and Future Work
This research opens avenues for integrating LLMs into proactive cybersecurity strategies, providing a scalable solution for honeytoken generation that can adjust to evolving threats. The findings suggest that LLMs can be further fine-tuned to enhance honeytoken credibility and effectiveness, potentially leading to the development of more sophisticated deception technologies.
Future work could explore the application of LLMs in other forms of cybersecurity deception, incorporating additional NLP methods like few-shot and zero-shot learning in prompt optimization. Moreover, leveraging LLMs in real-time environments to collect empirical data on honeytoken performance and evolving attacker behavior would be invaluable in refining these defensive measures.
Conclusion
The paper presents a novel approach to honeytoken generation using LLMs, showcasing its feasibility and effectiveness across several honeytoken types. This method significantly reduces the manual effort traditionally required in cyber deception setup, paving the way for more scalable and adaptable security solutions that could redefine cyber defense strategies in the future. Through meticulous evaluation, the study verifies that LLMs can produce high-quality honeytokens that are effective in misleading attackers, safeguarding systems, and preserving data integrity.