- The paper demonstrates an innovative HoneyGPT framework that leverages large language models to balance flexibility, interaction depth, and deception in terminal honeypots.
- It employs a Chain of Thought strategy and prompt pruning to optimize responses and manage context limitations during attacker engagements.
- Baseline and field evaluations reveal HoneyGPT’s superior performance in capturing novel attack vectors and dynamically simulating diverse systems.
HoneyGPT: Breaking the Trilemma in Terminal Honeypots with LLMs
Introduction
The concept of honeypots has long been integral to cybersecurity, serving as strategic deception mechanisms designed to attract and engage with unauthorized users. Their evolution, however, has been hampered by a trilemma: balancing flexibility, interaction depth, and deceptive capability. Traditional honeypots often lack the ability to dynamically adapt to evolving attacker tactics, thus restricting their efficacy. The advent of LLMs presents an opportunity to address these limitations, enabling the creation of more adaptive and interactive honeypot systems. The HoneyGPT framework, leveraging ChatGPT, exemplifies this innovative leap by offering cost-effectiveness, high adaptability, and enhanced interactivity in honeypot development.
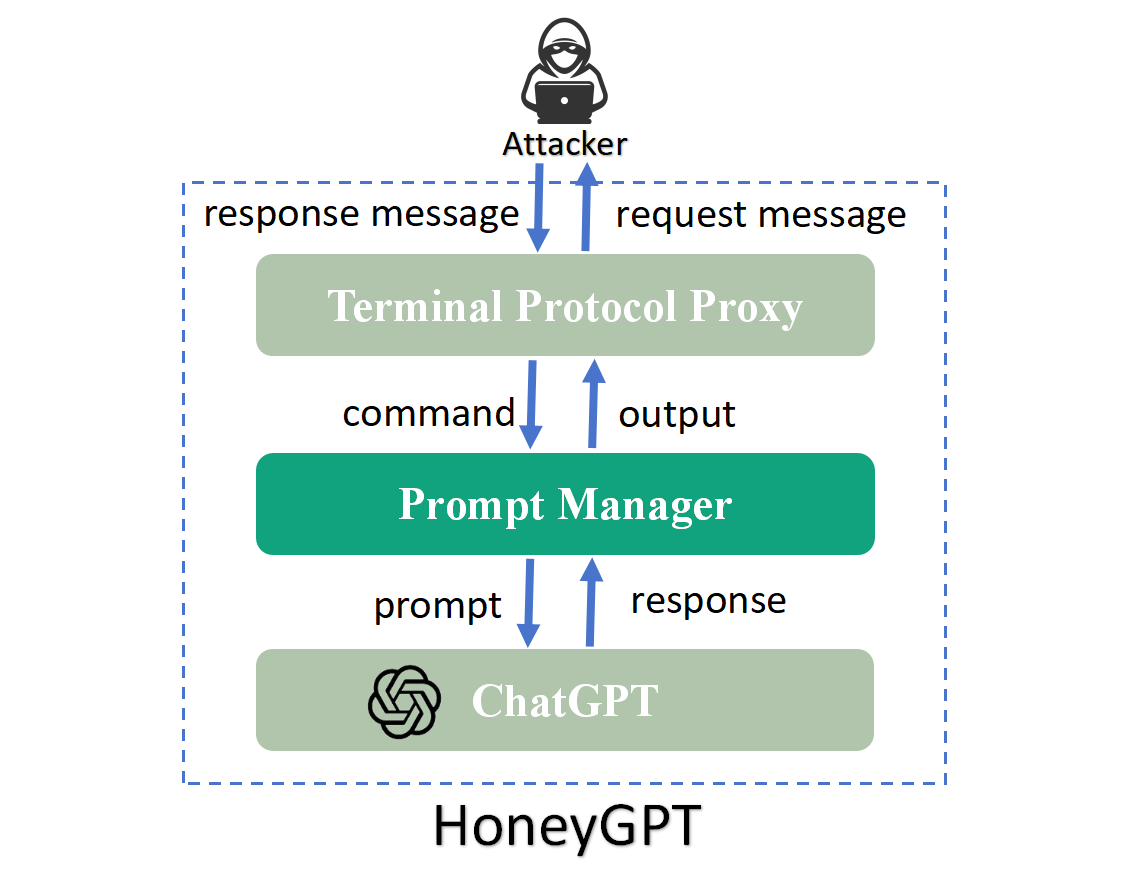
Figure 1: HoneyGPT Framework
Architecture and Design
HoneyGPT's architecture fundamentally transforms how honeypots interact with attackers. At its core, the framework comprises three main components: the Terminal Protocol Proxy, the Prompt Manager, and ChatGPT (Figure 2).
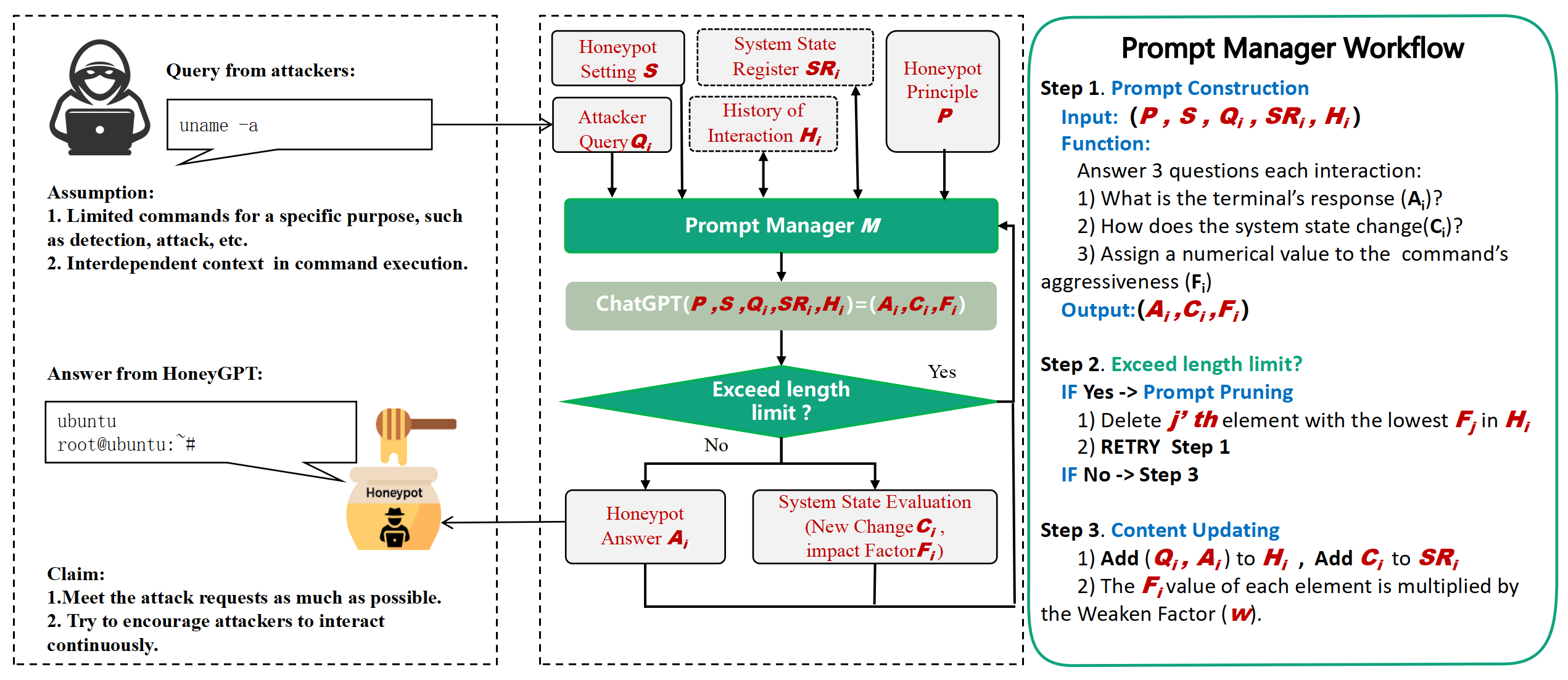
Figure 2: HoneyGPT Architecture
The Terminal Protocol Proxy manages protocol tasks such as connection setup and message parsing. The Prompt Manager constructs prompts based on attacker commands, interfacing with ChatGPT to generate realistic responses. This setup facilitates the generation of responses that align closely with attackers' expectations, enhancing engagement depth.
Key Features:
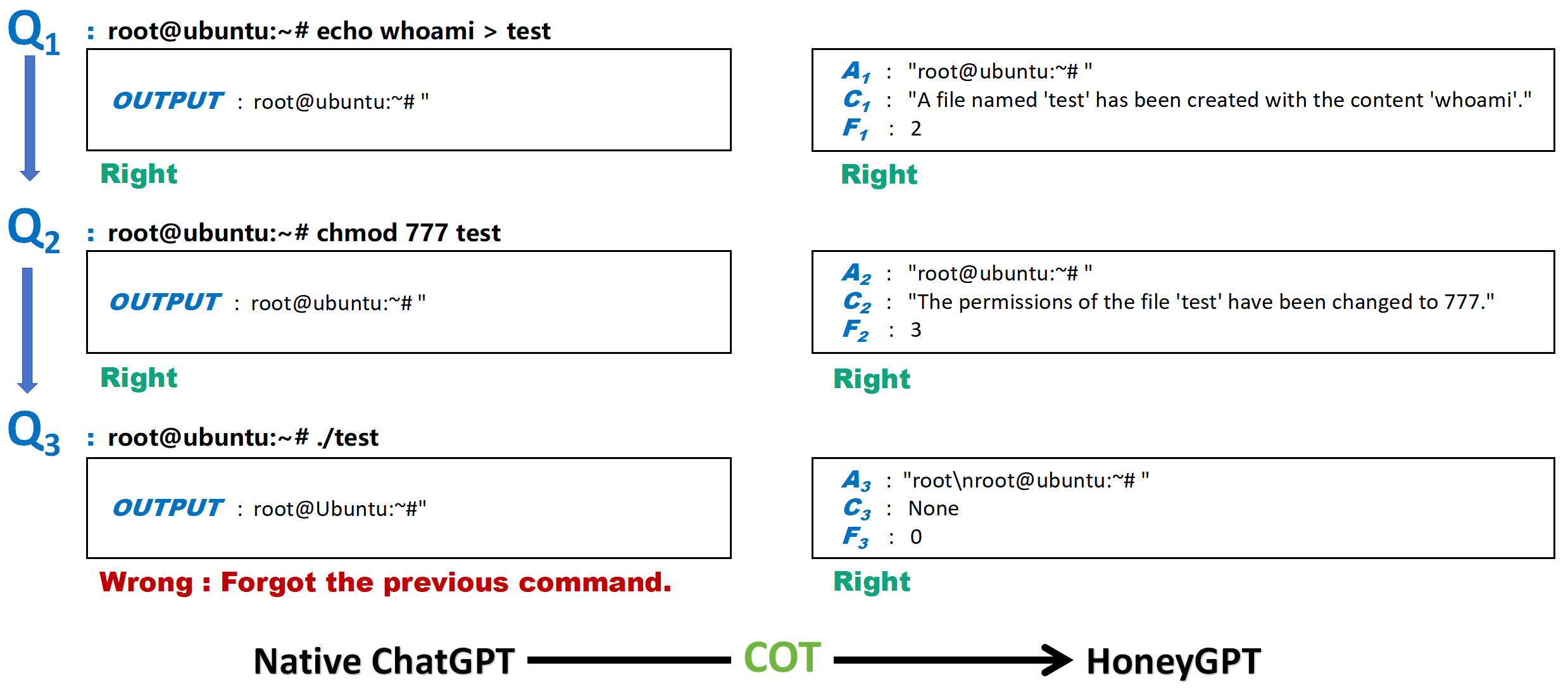
- Chain of Thought (CoT) Strategy: HoneyGPT employs a CoT approach, breaking down complex interaction sequences into manageable sub-problems, enhancing its ability to process extended dialogue tasks accurately.
- Prompt Pruning: To manage LLM context limitations, HoneyGPT employs a pruning algorithm that optimizes interaction memory by dynamically adjusting the prompt length based on interaction relevance.
Evaluation
The evaluation regime for HoneyGPT includes both baseline and field assessments, focusing on key metrics such as deception, interaction, and flexibility.
Baseline Evaluation
The baseline comparison illustrates HoneyGPT's superior performance against both Cowrie and real systems:
Field Evaluation
During field deployment, HoneyGPT achieved deeper engagements with attackers compared to traditional honeypots. It successfully captured novel attack vectors, demonstrating its capacity to adjust to dynamic threat environments.
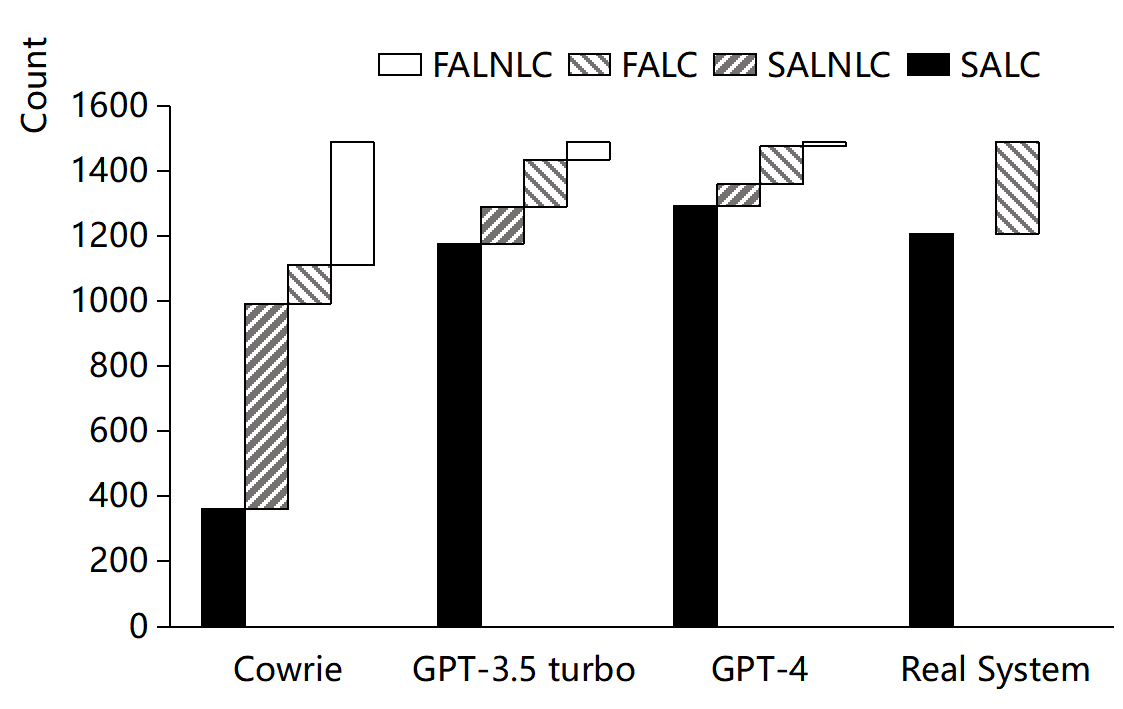
Figure 4: Distribution of Deception Categories Across Different Honeypots
Limitations and Future Work
While HoneyGPT represents a significant advancement, several challenges persist:
- Context and Token Limitations: LLM constraints on prompt context length complicate handling of extended command sequences.
- Request Limitation: Handling high-concurrency environments remains constrained by commercial LLM rate limits.
- Static Attack Patterns: Fixed attack sequences limit the efficacy of HoneyGPT in prolonging interactions.
Future enhancements could focus on addressing these limitations through proprietary LLM development and integration of advanced error recognition capabilities.
Conclusion
HoneyGPT marks a notable advancement in honeypot technology, effectively breaking the trilemma by integrating advanced LLMs. It demonstrates enhanced capabilities in engaging attackers and uncovering new attack vectors, positioning itself as a potent tool in cybersecurity defense strategies. Continued development in this domain promises further improvements in adaptability and interaction depth, paving the way for next-generation honeypot technologies.