Bi-VLA: Vision-Language-Action Model-Based System for Bimanual Robotic Dexterous Manipulations
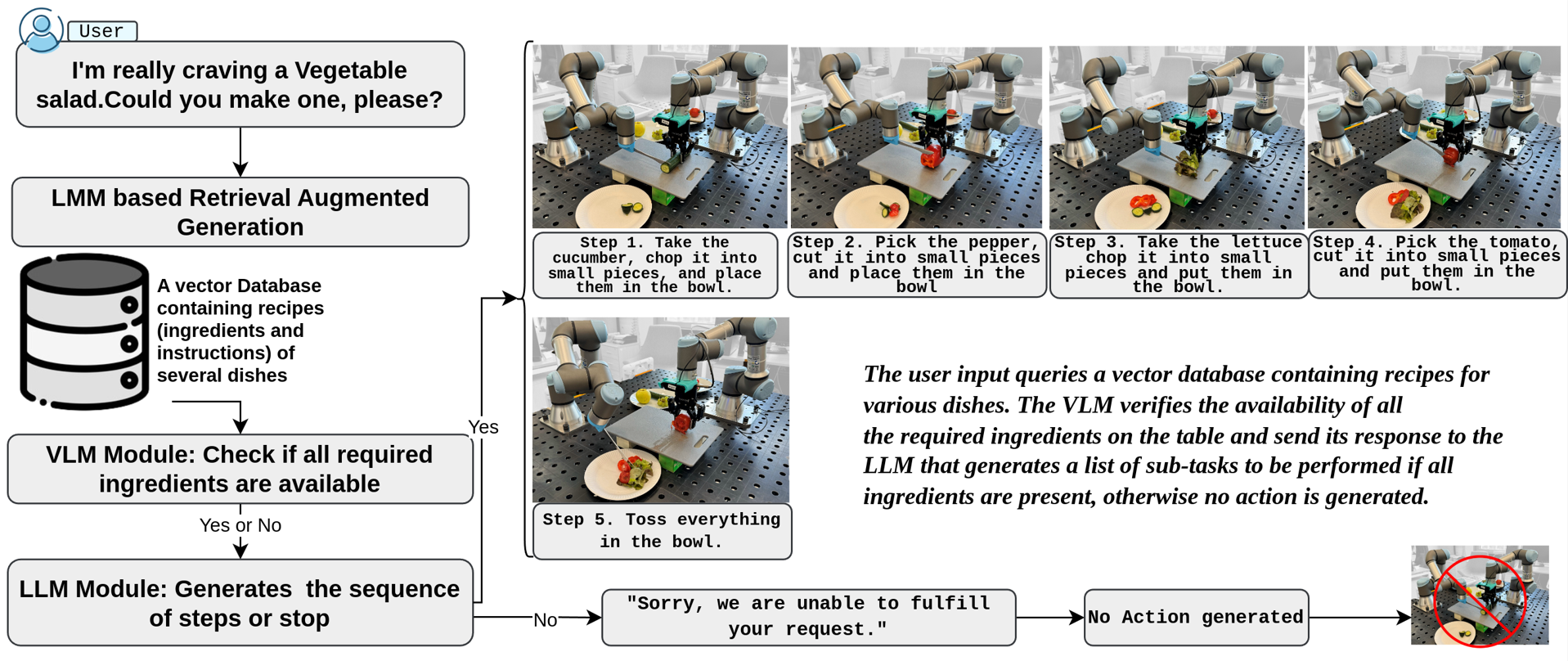
Abstract: This research introduces the Bi-VLA (Vision-Language-Action) model, a novel system designed for bimanual robotic dexterous manipulation that seamlessly integrates vision for scene understanding, language comprehension for translating human instructions into executable code, and physical action generation. We evaluated the system's functionality through a series of household tasks, including the preparation of a desired salad upon human request. Bi-VLA demonstrates the ability to interpret complex human instructions, perceive and understand the visual context of ingredients, and execute precise bimanual actions to prepare the requested salad. We assessed the system's performance in terms of accuracy, efficiency, and adaptability to different salad recipes and human preferences through a series of experiments. Our results show a 100% success rate in generating the correct executable code by the Language Module, a 96.06% success rate in detecting specific ingredients by the Vision Module, and an overall success rate of 83.4% in correctly executing user-requested tasks.
- C. Y. Kim, C. P. Lee, and B. Mutlu, “Understanding large-language model (llm)-powered human-robot interaction,” in Proceedings of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, pp. 371–380, 2024.
- C. D. Vo, D. A. Dang, and P. H. Le, “Development of multi-robotic arm system for sorting system using computer vision,” Journal of Robotics and Control (JRC), vol. 3, no. 5, pp. 690–698, 2022.
- A. Edsinger and C. C. Kemp, “Two arms are better than one: A behavior based control system for assistive bimanual manipulation,” in Recent Progress in Robotics: Viable Robotic Service to Human: An Edition of the Selected Papers from the 13th International Conference on Advanced Robotics, pp. 345–355, Springer, 2007.
- D. Rakita, B. Mutlu, M. Gleicher, and L. M. Hiatt, “Shared control–based bimanual robot manipulation,” Science Robotics, vol. 4, no. 30, p. eaaw0955, 2019.
- C. Bersch, B. Pitzer, and S. Kammel, “Bimanual robotic cloth manipulation for laundry folding,” in 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 1413–1419, IEEE, 2011.
- S. S. Mirrazavi Salehian, N. B. Figueroa Fernandez, and A. Billard, “Dynamical system-based motion planning for multi-arm systems: Reaching for moving objects,” in IJCAI’17: Proceedings of the 26th International Joint Conference on Artificial Intelligence, pp. 4914–4918, 2017.
- Y. Chen, T. Wu, S. Wang, X. Feng, J. Jiang, Z. Lu, S. McAleer, H. Dong, S.-C. Zhu, and Y. Yang, “Towards human-level bimanual dexterous manipulation with reinforcement learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 5150–5163, 2022.
- G. Franzese, L. de Souza Rosa, T. Verburg, L. Peternel, and J. Kober, “Interactive imitation learning of bimanual movement primitives,” IEEE/ASME Transactions on Mechatronics, 2023.
- M. Shridhar, L. Manuelli, and D. Fox, “Cliport: What and where pathways for robotic manipulation,” in Conference on robot learning, pp. 894–906, PMLR, 2022.
- I. Singh, V. Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg, “Progprompt: Generating situated robot task plans using large language models,” in 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 11523–11530, IEEE, 2023.
- J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 9493–9500, IEEE, 2023.
- A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu, et al., “Rt-1: Robotics transformer for real-world control at scale,” arXiv preprint arXiv:2212.06817, 2022.
- A. Stone, T. Xiao, Y. Lu, K. Gopalakrishnan, K.-H. Lee, Q. Vuong, P. Wohlhart, S. Kirmani, B. Zitkovich, F. Xia, et al., “Open-world object manipulation using pre-trained vision-language models,” arXiv preprint arXiv:2303.00905, 2023.
- S. Huang, Z. Jiang, H. Dong, Y. Qiao, P. Gao, and H. Li, “Instruct2act: Mapping multi-modality instructions to robotic actions with large language model,” arXiv preprint arXiv:2305.11176, 2023.
- W. Yu, N. Gileadi, C. Fu, S. Kirmani, K.-H. Lee, M. G. Arenas, H.-T. L. Chiang, T. Erez, L. Hasenclever, J. Humplik, et al., “Language to rewards for robotic skill synthesis,” arXiv preprint arXiv:2306.08647, 2023.
- A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y. Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y. Lu, H. Michalewski, I. Mordatch, K. Pertsch, K. Rao, K. Reymann, M. Ryoo, G. Salazar, P. Sanketi, P. Sermanet, J. Singh, A. Singh, R. Soricut, H. Tran, V. Vanhoucke, Q. Vuong, A. Wahid, S. Welker, P. Wohlhart, J. Wu, F. Xia, T. Xiao, P. Xu, S. Xu, T. Yu, and B. Zitkovich, “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” in arXiv preprint arXiv:2307.15818, 2023.
- F. Krebs and T. Asfour, “A bimanual manipulation taxonomy,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 11031–11038, 2022.
- F. Xie, A. Chowdhury, M. De Paolis Kaluza, L. Zhao, L. Wong, and R. Yu, “Deep imitation learning for bimanual robotic manipulation,” Advances in neural information processing systems, vol. 33, pp. 2327–2337, 2020.
- S. Stepputtis, M. Bandari, S. Schaal, and H. B. Amor, “A system for imitation learning of contact-rich bimanual manipulation policies,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 11810–11817, IEEE, 2022.
- J. Grannen, Y. Wu, B. Vu, and D. Sadigh, “Stabilize to act: Learning to coordinate for bimanual manipulation,” in Conference on Robot Learning, pp. 563–576, PMLR, 2023.
- B. Thach, B. Y. Cho, T. Hermans, and A. Kuntz, “Deformernet: Learning bimanual manipulation of 3d deformable objects,” arXiv preprint arXiv:2305.04449, 2023.
- Z. Fu, T. Z. Zhao, and C. Finn, “Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation,” arXiv preprint arXiv:2401.02117, 2024.
- Y. Lin, A. Church, M. Yang, H. Li, J. Lloyd, D. Zhang, and N. F. Lepora, “Bi-touch: Bimanual tactile manipulation with sim-to-real deep reinforcement learning,” IEEE Robotics and Automation Letters, 2023.
- B. Zhu, E. Frick, T. Wu, H. Zhu, and J. Jiao, “Starling-7b: Improving llm helpfulness & harmlessness with rlaif,” November 2023.
- G. B. et al., “Introducing chatgpt,” 2022.
- J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,” arXiv preprint arXiv:2308.12966, 2023.
- J. P. De Villiers, F. W. Leuschner, and R. Geldenhuys, “Centi-pixel accurate real-time inverse distortion correction,” in Optomechatronic Technologies 2008, vol. 7266, pp. 320–327, SPIE, 2008.
- A. E. Conrady, “Decentred lens-systems,” Monthly notices of the royal astronomical society, vol. 79, no. 5, pp. 384–390, 1919.
- P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. tau Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive nlp tasks,” 2021.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.