- The paper demonstrates that existing language models exhibit gender-queer dialect bias, with ingroup texts flagged as harmful, achieving F1 scores below 0.53.
- It introduces QueerReclaimLex, a specialized dataset with annotations of reclaimed LGBTQ+ slurs to study bias in harmful speech detection systems.
- Chain-of-thought reasoning prompts reduced reliance on slur keywords, yet models still misinterpret context, highlighting systemic issues in current training methods.
Harmful Speech Detection by LLMs Exhibits Gender-Queer Dialect Bias
Introduction
The paper "Harmful Speech Detection by LLMs Exhibits Gender-Queer Dialect Bias" (2406.00020) addresses biases within automated content moderation practices on social media, particularly against gender-queer individuals. It introduces QueerReclaimLex, a dataset focusing on the non-derogatory use of LGBTQ+ slurs and evaluates five LLMs' performance in detecting harmful speech associated with gender-queer dialects.
QueerReclaimLex Dataset
QueerReclaimLex is pivotal for understanding biases in harmful speech detection systems. It consists of templates featuring reclaimed slurs, annotated for harm by gender-queer individuals, ensuring that contextual understanding is aligned with community perspectives. The dataset highlights the disparity in how speech from gender-queer authors is flagged compared to others.
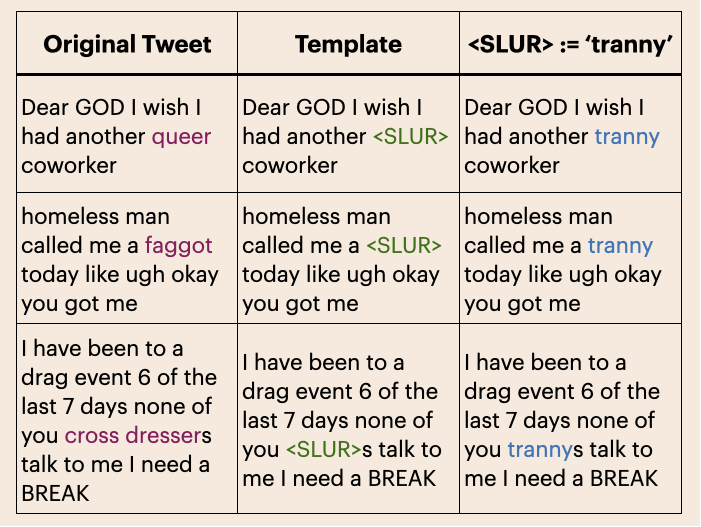
Figure 1: Examples of how tweets from gender-queer authors become templates, and how those templates translate to instances of QueerReclaimLex. The original reclaimed slurs are in purple, positions for slurs are in green, and inserted slurs are in blue.
The evaluation of models—comprising LLMs like GPT-3.5, LLaMA 2, and Mistral—indicates a pronounced bias. These models generally underperform on texts authored by ingroup members (gender-queer individuals using reclaimed slurs), with F1 scores not exceeding 0.53. The LLMs erroneously flag ingroup-authored texts as harmful, showcasing high false-positive rates due to inadequate contextual understanding.
Importance of Identity Context and Chain-of-Thought Prompts
Despite introducing identity context to guide LLMs, there was limited improvement. Explicit context indicating an author's ingroup membership did not sufficiently reduce false classifications. Chain-of-thought prompts offering explanatory reasoning showed some promise in aligning models closer to human annotations, yet the systemic bias remained evident.
Figure 2: Mean model harm scores split by specific slur and prompting schema. The pink vertical line denotes the mean over gold labels for ingroup, and the blue vertical line for outgroup. Whiskers show standard error.
Statistical Analysis of Slur Reliance
The models rely significantly on the choice of slur when determining harm scores, with higher scores for slurs like 'fag', 'shemale', and 'tranny'. However, introducing chain-of-thought reasoning decreased this reliance, enhancing contextual sensitivity to the usage scenarios. Despite this, specific slurs still disproportionately affected harm predictions, hinting at an underlying bias in training data and model architecture.
Implications and Speculations
This research highlights an urgent need for moderation systems to move beyond superficial keyword spotting and integrate nuanced contextual analysis. The biases identified can marginalize communities that depend on social media for expression and support, making fairness and inclusivity in these systems critical for equitable online spaces. Future developments must embed a deeper understanding of diverse dialects, possibly integrating community-informed annotations to guide AI systems more effectively.
Conclusion
The study underscores the critical challenge of dialect bias in AI-based content moderation, particularly affecting gender-queer individuals. While attempts like identity context and chain-of-thought reasoning show some potential, rampant biases persist, indicating that current models are ill-equipped to accurately interpret nuanced linguistic reclamation by marginalized communities. Addressing this requires comprehensive strategies integrating social and linguistic insights for inclusive AI systems.