- The paper introduces a latent diffusion framework that reduces complex facies geomodels into a low-dimensional latent space while preserving geological realism.
- It employs a two-stage training approach by integrating VAE encoding with DDIM-based, deterministic sampling for fast and stable data assimilation.
- Flow simulations and history matching validate the method, achieving 98% conditioning accuracy and near-perfect spatial statistics compared to reference models.
Latent Diffusion Models for Parameterization and Data Assimilation of Facies-Based Geomodels
Introduction and Motivation
The paper presents a comprehensive framework for geological parameterization and data assimilation using latent diffusion models (LDMs) for facies-based geomodels. The motivation stems from the need to efficiently represent complex geological structures, such as channelized systems, in a reduced-dimensional latent space while preserving geological realism. Traditional parameterization methods (e.g., PCA, K-PCA, O-PCA, and DCT) are limited in their ability to capture non-Gaussian, multi-facies features, especially under sparse conditioning. Deep generative models, particularly GANs and VAEs, have improved geological realism but suffer from training instability and output quality issues, respectively. Diffusion models, and specifically LDMs, offer a promising alternative by combining stable training, high-quality sample generation, and effective dimension reduction.
Diffusion Model Framework
The core of the approach is the use of denoising diffusion probabilistic models (DDPMs) and their deterministic variant, denoising diffusion implicit models (DDIMs), for generative modeling. The diffusion process consists of a forward noising process, which gradually corrupts a clean geomodel with Gaussian noise, and a learned reverse denoising process, which reconstructs a plausible geomodel from noise. The reverse process is parameterized by a neural network trained to predict the noise at each step, enabling sample generation from pure noise.
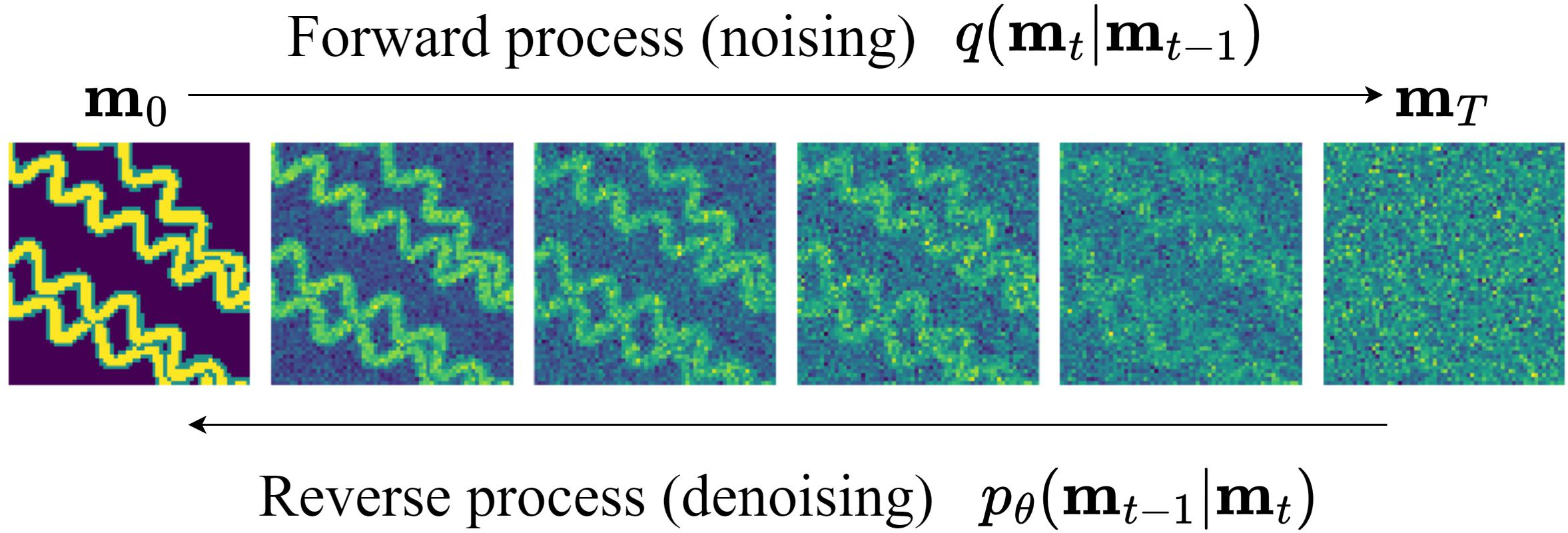
Figure 1: Illustration of the diffusion process for a 2D channelized geomodel.
The LDM extends this by operating in a lower-dimensional latent space, achieved via a variational autoencoder (VAE) encoder-decoder architecture. The encoder maps high-dimensional geomodels to a compact latent representation, and the decoder reconstructs geomodels from latent codes. The diffusion process is then applied in this latent space, significantly reducing the number of parameters required for data assimilation.
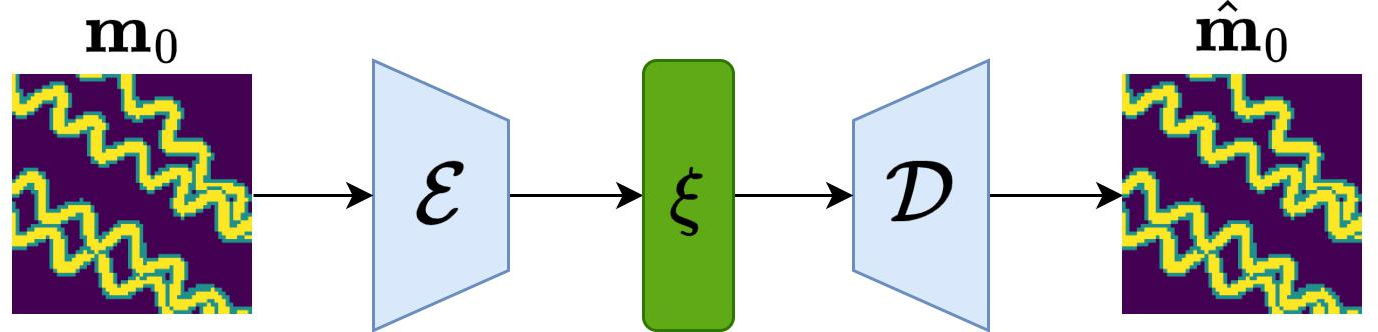
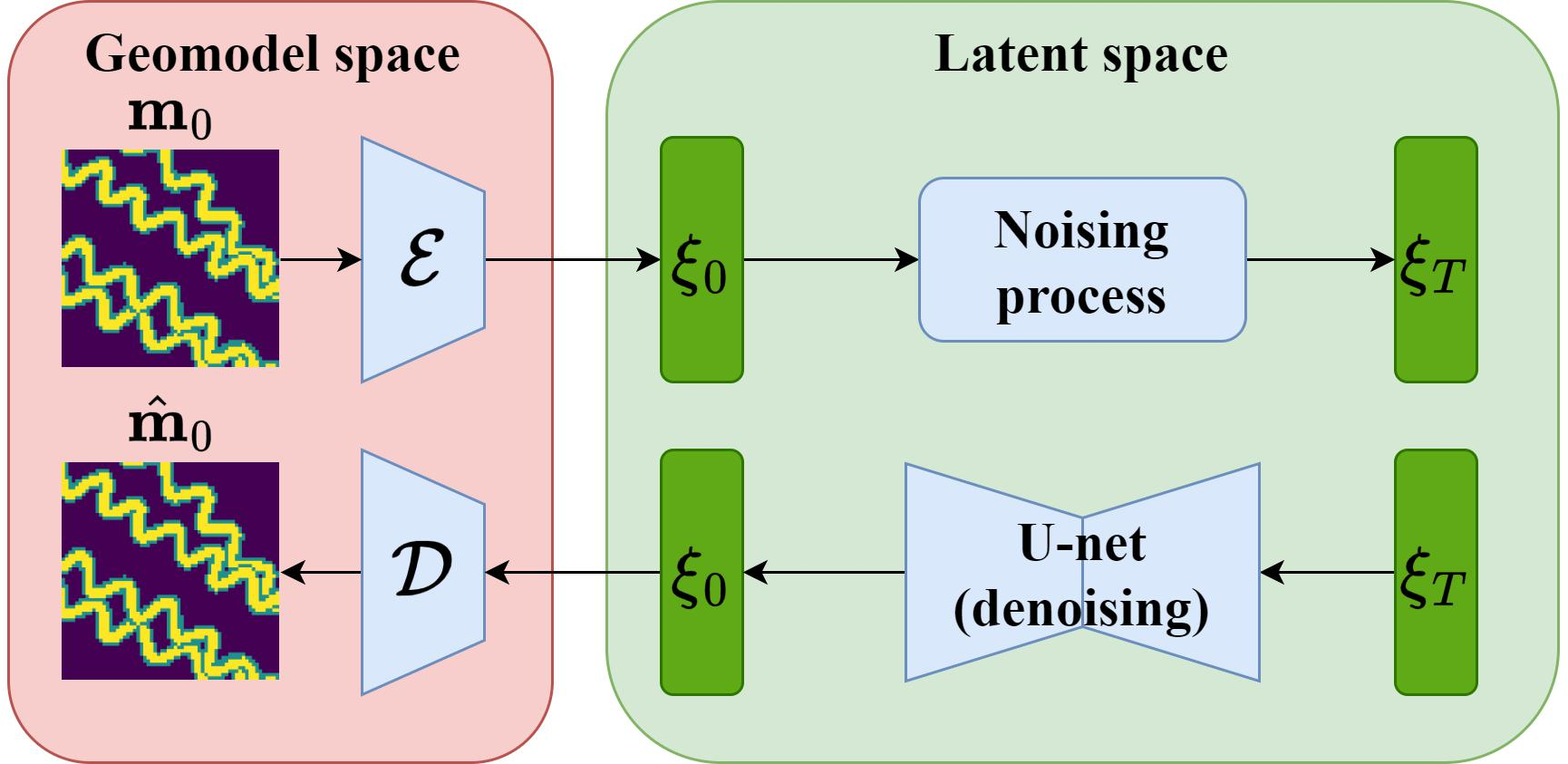
Figure 2: Encoder-decoder component of the LDM, showing the mapping from geomodel space to latent space and back.
Model Architecture and Training
The LDM architecture consists of two main components:
- Variational Autoencoder (VAE): The encoder comprises three downsampling convolutional layers interleaved with four residual blocks, achieving a downsampling ratio of f=8. The decoder mirrors this structure. Unlike standard VAEs with 1D latent vectors, the LDM uses a 2D latent space, preserving spatial structure.
- U-net Denoising Network: The U-net, with downsampling and upsampling residual blocks and an attention mechanism, performs the reverse diffusion process in latent space.
Training proceeds in two stages:
- VAE Training: The loss combines reconstruction error, Kullback-Leibler divergence (to enforce standard normality in latent space), and a hard-data loss to ensure conditioning at well locations.
- Diffusion Model Training: The U-net is trained to predict the noise in the latent space using the standard DDPM loss, with the forward process applied to latent codes.
The implementation leverages the diffusers and monai Python libraries, with training performed on 4000 Petrel-generated conditional realizations of 64×64 three-facies geomodels. Training is computationally efficient, requiring approximately 2 hours on a single Nvidia A100 GPU.
Geomodel Generation and Evaluation
The LDM is evaluated by generating ensembles of geomodels and comparing them to reference Petrel realizations using both visual inspection and quantitative metrics:
- Visual Consistency: LDM-generated models exhibit channel continuity, orientation, and facies ordering consistent with reference models. Conditioning at well locations is honored with 98% accuracy.
- Spatial Statistics: Two-point connectivity functions for each facies along multiple directions show near-perfect agreement between LDM and reference ensembles, indicating accurate reproduction of spatial structure.
- Latent Space Smoothness: Linear interpolation in latent space yields smooth transitions in generated geomodels, as quantified by high structural similarity index measure (SSIM) values between consecutive interpolated models. This property is critical for efficient and stable data assimilation.
Flow Simulation and History Matching
The practical utility of the LDM parameterization is demonstrated through two-phase (oil-water) flow simulations and ensemble-based history matching using the ensemble smoother with multiple data assimilation (ESMDA):
- Flow Response: Distributions of injection and production rates (P10, P50, P90) for LDM-generated models closely match those from reference models, confirming that the parameterization preserves flow-relevant geological features.
- History Matching (Case 1: Fixed Facies Properties): Assimilation of synthetic production data leads to significant uncertainty reduction in flow forecasts. Posterior geomodels, identified via k-means clustering, display geological features consistent with the true model and reduced variability compared to the prior.
- History Matching (Case 2: Uncertain Facies Properties): When facies porosity and permeability are treated as uncertain, the LDM-based workflow successfully updates both spatial and property parameters. Posterior distributions for most properties shift towards the true values, except for parameters to which the data are insensitive.
Implementation Considerations and Trade-offs
- Dimensionality Reduction: The use of a 2D latent space (as opposed to a 1D vector) enables preservation of spatial structure while achieving substantial parameter reduction (e.g., from 4096 to 64 variables for 64×64 models).
- Deterministic Sampling: DDIM-based inference allows for fast, deterministic generation, which is advantageous for data assimilation workflows requiring predictable model updates.
- Conditioning and Hard Data: The inclusion of a hard-data loss in VAE training ensures that generated models honor conditioning data, a critical requirement in practical reservoir modeling.
- Computational Efficiency: The approach is scalable to larger datasets and higher resolutions, though extension to 3D models will require further architectural and computational optimizations.
Implications and Future Directions
The LDM-based parameterization framework offers a robust and efficient solution for representing and updating complex geological models in data assimilation workflows. The demonstrated ability to preserve geological realism, honor conditioning, and enable uncertainty quantification in flow forecasts positions LDMs as a strong alternative to GANs, VAEs, and PCA-based methods for subsurface modeling.
Potential future developments include:
- Extension to 3D geomodels and larger domains.
- Integration with alternative data assimilation algorithms (e.g., MCMC, RML).
- Unified treatment of multiple geological scenarios (e.g., varying channel architectures).
- Application to real field data and more complex conditioning scenarios.
Conclusion
This work establishes latent diffusion models as a powerful tool for geological parameterization and data assimilation in facies-based geomodels. The combination of VAE-based dimension reduction, U-net denoising, and deterministic DDIM sampling enables efficient, stable, and geologically realistic model generation and updating. The approach achieves strong agreement with reference models in both spatial and flow statistics, and supports effective uncertainty reduction in history matching. The framework is well-positioned for further extension to more complex and realistic reservoir modeling scenarios.