- The paper presents LLM-ARC, a neuro-symbolic framework that improves logical reasoning by coupling an LLM actor with an automated reasoning critic.
- The system generates Answer Set Programming code and tests, using iterative self-correction to achieve a state-of-the-art 88.32% on the FOLIO benchmark.
- The study outlines potential enhancements in error handling and critic training, addressing challenges like existential quantification and multi-variable rule management.
LLM-ARC: Enhancing LLMs with an Automated Reasoning Critic
Introduction to LLM-ARC Framework
The LLM-ARC framework introduces a neuro-symbolic approach designed to enhance the logical reasoning capabilities of LLMs by combining them with an Automated Reasoning Critic (ARC). The framework conceptualizes an Actor-Critic model where the LLM (Actor) generates declarative logic programs using Answer Set Programming (ASP) and constructs tests for semantic correctness. The ARC, which functions as the Critic, evaluates the generated code, runs these tests, and provides feedback for iterative refinement. The system aims to achieve higher accuracy in complex logical reasoning tasks, as demonstrated by its state-of-the-art (SOTA) performance of 88.32% on the FOLIO benchmark for logical reasoning.
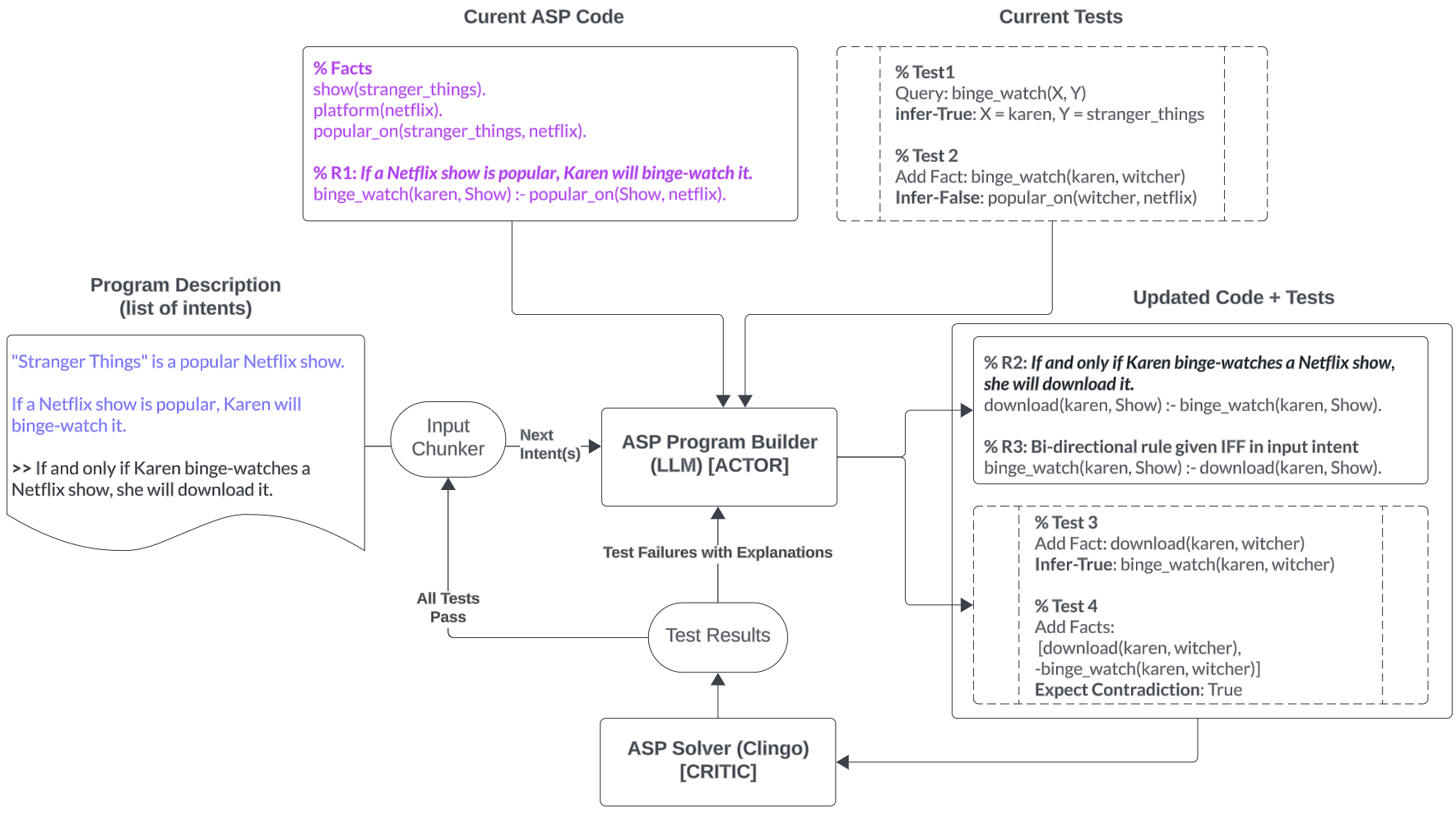
Figure 1: LLM-ARC Implementation based on Answer Set Programming (ASP).
System Design and Methodology
Actor: LLM as Logic Program Writer
The LLM serves as the Actor in the LLM-ARC framework, specifically tasked with generating ASP code along with associated tests. This actor leverages a few-shot learning paradigm using GPT4-Turbo in conjunction with a set of exemplar logical structures identified within the FOLIO dataset. A stratification approach is used to classify natural language statements based on their logical structure, enabling the LLM to provide contextually relevant examples during ASP code generation.
Critic: Automated Reasoning Engine
The Critic role in the LLM-ARC system is fulfilled by the Clingo ASP Solver, which not only checks for syntax errors but also evaluates the accuracy of the logic programs by verifying the generated tests. The Critic's feedback loop allows for a systematic refinement process where identified faults prompt ASP code adjustments. The Critic performs error analysis and facilitates error correction by providing detailed messages when discrepancies arise between the intended logical models and the realized outputs.
Self-Correction Loop
The self-correction mechanism is central to the LLM-ARC system, where the Actor modifies its code and tests based on the Critic's feedback, iterating until all errors are rectified or a maximum iteration limit is reached. This iterative process is substantiated by ongoing adjustments that enhance accuracy over multiple retries.
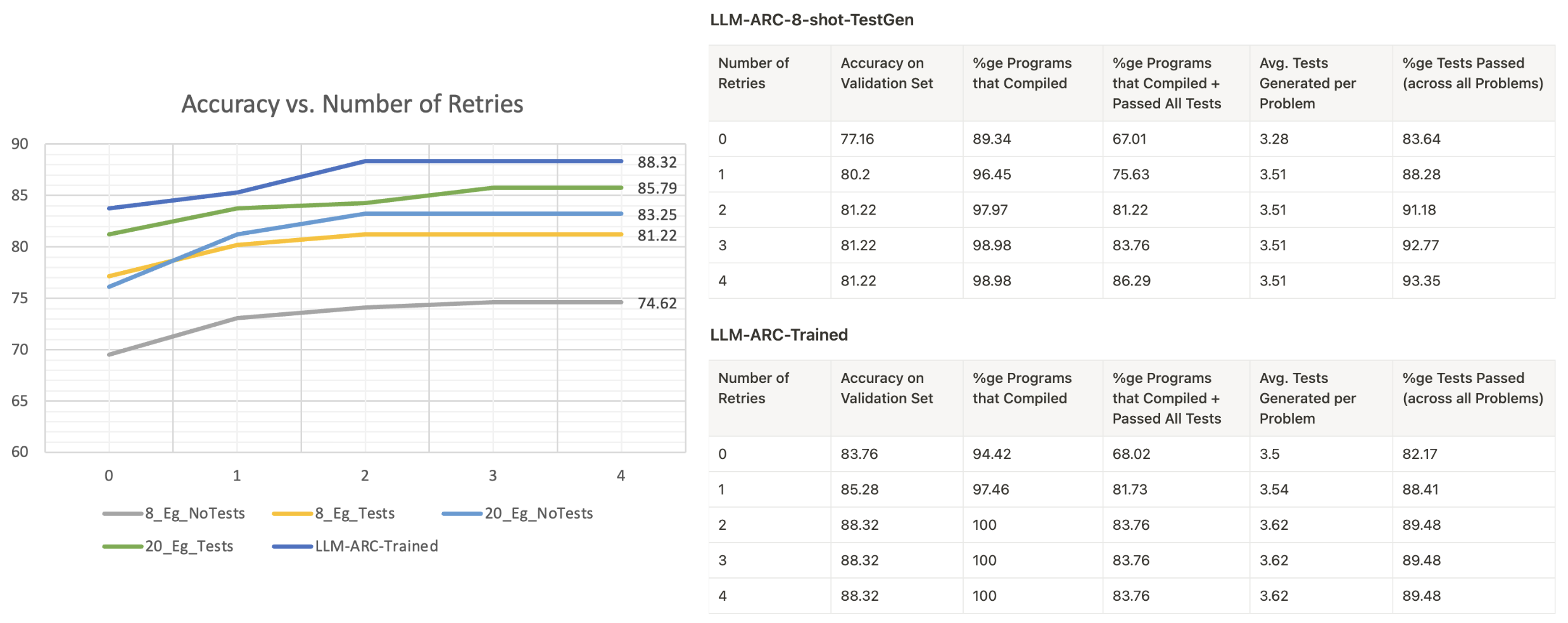
Figure 2: Impact of Iterative Self-Correction demonstrating improvements in system accuracy.
Experimental Evaluation on FOLIO
The LLM-ARC system was evaluated using the FOLIO benchmark, comprising logically complex natural language reasoning tasks. Experiments compared several LLM variants, including zero-shot and few-shot methodologies incorporating the Actor-Critic architecture. Notably, the LLM-ARC configurations that included test generation outperformed LLM-only models and previous SOTA, affirming the system's efficacy.
Comparative Analysis
The following table summarizes the performance metrics of various systems evaluated on the FOLIO dataset:
| System |
Accuracy |
| GPT3.5-ZS |
66.9% |
| GPT4-T-ZS |
67% |
| GPT4-T-CoT |
74.1% |
| GPT4-FT-NL |
80.7% |
| GPT4-FT-FOL |
78.17% |
| LLM-ARC-8-shot |
74.62% |
| LLM-ARC-8-shot-TestGen |
81.22% |
| LLM-ARC-20-shot |
83.25% |
| LLM-ARC-20-shot-TestGen |
85.79% |
| LLM-ARC-Trained |
88.32% |
Implementation Insights and Potential Enhancements
Error Analysis
The predominant errors within the LLM-ARC system were associated with existential quantification limitations in ASP, rules involving multiple variables, and entities used ambiguously as types and individuals. Addressing these limitations could involve enhancements in training guidance and leveraging alternative logic representations better suited for these challenges.
Future Directions
Potential enhancements to LLM-ARC include optimizing chunking strategies for handling larger data sets, improving Critic-generated explanations to aid Actor reasoning, and exploring the development of dedicated Critics trained through human feedback to evaluate reasoning engine outputs more thoroughly.
Conclusion
LLM-ARC exemplifies the integration of neuro-symbolic architectures to surmount the challenges inherent to LLM-based logical reasoning tasks. Its innovative Actor-Critic model leverages LLM capabilities for code generation while utilizing a robust reasoning engine to ensure semantic correctness. The empirical results on the FOLIO dataset substantiate the promise of this approach in advancing complex reasoning capabilities, offering clear implications for various natural language processing applications requiring reliable and interpretable logical inferences.