- The paper presents the Search4LLM paradigm that leverages search engine data for enhancing LLM pre-training, fine-tuning, and continuous updating.
- It details the LLM4Search approach, where LLMs are used to improve semantic indexing, query refinement, and generative synthesis of search results.
- The study highlights challenges such as scalable memory, explainability, and agentic orchestration, setting actionable directions for future research.
Synthesis of Search Engine Services and LLMs: A Comprehensive Perspective
Introduction and Technological Context
The intersection of search engine technologies and LLMs delineates a critical juncture in the evolution of information retrieval (IR) and NLP. The paper "When Search Engine Services meet LLMs: Visions and Challenges" (2407.00128) presents a systematic exploration of the mutual benefits, challenges, and research directions arising from the integration of LLMs with search engine infrastructures.
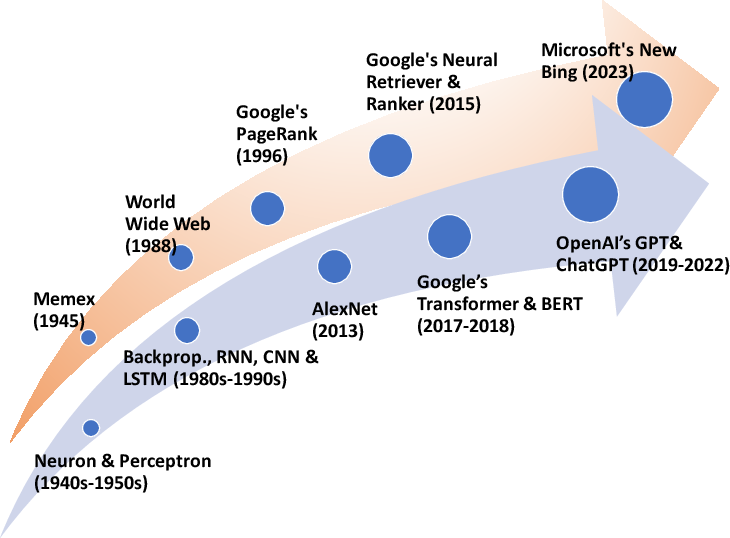
Figure 1: Technological co-evolution of AI and search engine models, marking milestones in IR and large-scale NLP since the 1940s.
The co-evolution of foundational milestones in IR (from Memex to PageRank) and AI (from artificial neurons to transformers and BERT/GPT) has fostered a fertile landscape for hybrid architectures that combine the strengths of LLMs (semantic understanding, generation) and search engines (structured retrieval, freshness, and ranking).
Architectural Baselines of Search Engines and LLM Life-Cycle
Traditional search engines are built on layered architectures: content collection via crawlers, storage through inverted indexes, sophisticated retrieval and ranking algorithms (including Learning-to-Rank, LTR), and endpoint evaluation with metrics like NDCG and MRR.
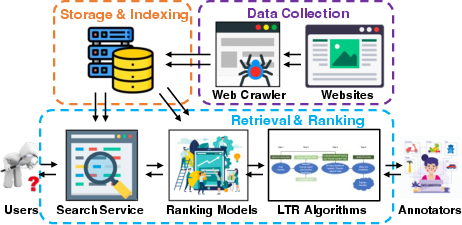
Figure 2: Core architecture of a production search engine, highlighting modules for crawling, indexing, ranking, and evaluation.
The LLM model life-cycle consists of foundation pre-training, task-oriented fine-tuning (SFT), alignment with human feedback (e.g., RLHF), and downstream deployment in application settings, including agents.
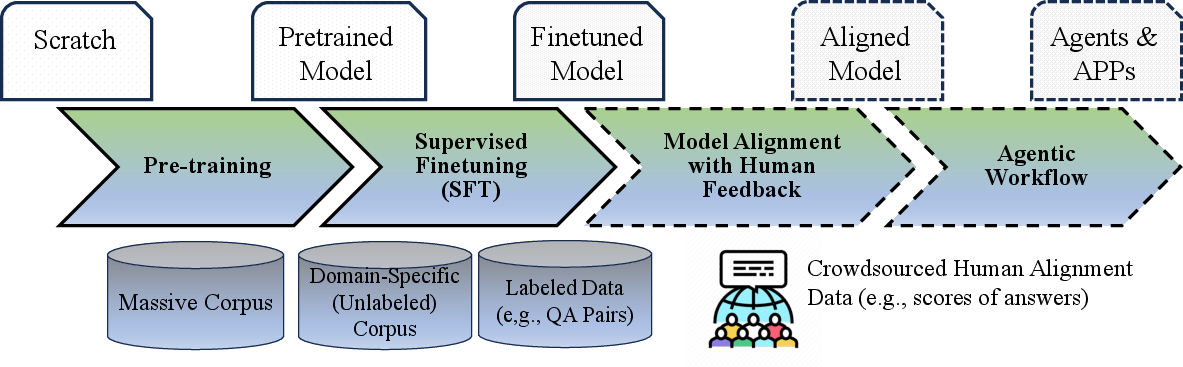
Figure 3: LLM pipeline spanning pre-training, SFT, RLHF-based alignment, and agentic integration for complex application workflows.
Search4LLM: Leveraging Search Engine Services in LLM Development
The Search4LLM paradigm exploits search engine capabilities at all stages of the LLM pipeline:
- Pre-training Data Acquisition: Search engines provide massive, dynamic, and topically diverse corpora, enabling domain-balanced and up-to-date pre-training regimes.
- Quality and Domain Control: Indexing and ranking modules allow data curation by domain and quality signals, mitigating bias and enhancing language/dialect representativity.
- Continuous Model Refreshing: Search engine freshness mechanisms (frequent crawling/indexing) can power the continuous updating of LLMs, reducing data staleness.
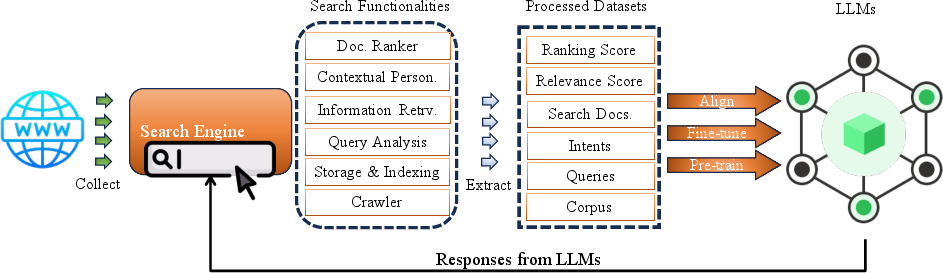
Figure 4: Search4LLM workflow, integrating search engine data collection, indexing, and user behavior feedback into LLM model pre-training and fine-tuning.
Supervised fine-tuning (SFT) is enriched by extracting high-quality QA pairs from real search logs, capturing authentic queries and preferred results.

Figure 5: Transformation of search logs into SFT training instances using top-ranked results for candidate answers, closing the domain gap between pre-training and user intent.
For alignment, LTR, value screening, and content quality filters native to search engines offer granular supervision signals, directly influencing model preference structures and output distribution.
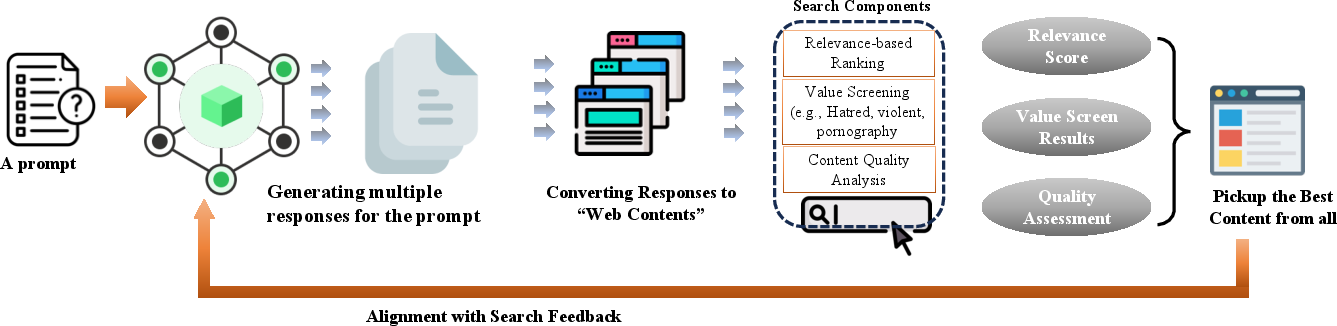
Figure 6: Model alignment using search engine-derived relevance signals, spam filters, and user engagement metrics as RLHF or SFT supervision.
Retrieval-Augmented Generation (RAG) can be used for real-time knowledge injection, extending LLM factuality and timeliness.
LLM4Search: Augmenting Search Engines with LLMs
The LLM4Search paradigm leverages LLMs to upgrade core search engine functionalities:
- Semantic Indexing and Extraction: LLMs perform deeper semantic labeling, contextual term extraction, and summarization for more granular and efficient indexing.
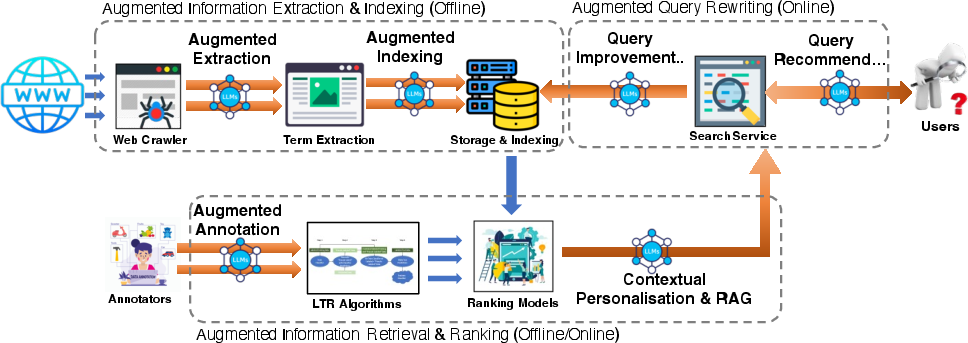
Figure 7: LLM4Search overview, illustrating augmentation points for indexing, query improvement, and result ranking via LLM prompt interfaces and offline/online workflows.

Figure 8: Term extraction and snippet summarization via LLM-instruction-based prompting, improving downstream page indexing and snippet selection.
- Retrieval and Ranking Supervision: LLMs generate dense annotations for pointwise, pairwise, and listwise LTR objectives; they can simulate expert annotation at scale.



Figure 9: Example outputs for LTR annotation tasks (pointwise, pairwise, and listwise) generated by LLM prompting.
- Generative RAG for Results Synthesis: LLMs synthesize coherent, referenced responses from retrieved documents, moving search from “ten blue links” to fully synthesized answers.

Figure 10: Deployment of RAG to aggregate and synthesize search results, producing extended, reference-aware responses for conversational search.
- Automated Evaluation Pipelines: LLM agents mimic user search behaviors for A/B testing, online ranking evaluation, and satisfaction estimation, expediting development cycles.

Figure 11: LLM-automated evaluation of search result quality, relevance, and ranking via prompt-driven agent simulation.
Challenges and Open Technical Directions
The integration of LLMs and search engines introduces complex challenges:
- Memory Decomposition: Efficient scalable memory architectures for CRUD operations in LLMs require deep research on consistency and context-aware retrieval. There is a strong need for “exact recovery” mechanisms within LLM memory to bridge the hallucination gap.
- Explainability: Black-box reasoning in LLM-driven retrieval and ranking poses obstacles for system trustworthiness and regulatory acceptance. Advances are demanded in XAI for LLM-in-search settings, connecting influence estimators, visual attribution, and user-faithful explanation dashboards.
- Agentic Orchestration: The deployment of LLM-powered agents for composite reasoning, tool utilization (e.g., web search), and iterative planning implicates research in long/short-term memory architectures, adaptive planning algorithms, and robust, error-minimizing real-time action selection.
Broader Implications and Future Trends
This convergence carries major practical and theoretical implications:
- Vertical Integration: Domain-specialized LLMs, continuously refreshed and aligned via search infrastructure, may yield state-of-the-art performance for vertical search applications (e.g., medical, legal, academic).
- Recommendation and Personalization: User context modeling informed jointly by LLM in-context learning and longitudinal search/browsing histories could deliver highly personalized, context-aware retrieval and recommendation pipelines.
- Ethical and Legal Considerations: The increasing reliance on automatically aggregated data and “black-box” models foregrounds the need for robust bias detection, fairness evaluation, privacy guarantees, and explainability standards.
Conclusion
The integration of search engine architectures and LLMs articulates a comprehensive reimagining of both search and language modeling. By leveraging search engine data pipelines, ranking modules, and evaluation infrastructure in LLM life-cycles (Search4LLM), and by empowering core search workflows with LLM semantic reasoning and generative synthesis (LLM4Search), this symbiotic paradigm lays a systematic, actionable roadmap for next-generation, user-centric digital information systems. The work charts concrete research directions in scalable memory, model transparency, agent-based orchestration, and robust evaluation, setting the stage for innovations that may drive the practical frontier of AI-powered information access.