- The paper presents a comprehensive overview of conversational search, detailing a modular design that integrates query reformulation, clarification, retrieval, and response generation.
- The paper leverages large language models to improve query reformulation and response generation, while addressing challenges such as context noise and hallucination.
- The paper evaluates multi-turn interactions using novel evaluation protocols and domain-specific applications, offering actionable insights for next-generation search systems.
A Comprehensive Survey of Conversational Search
Introduction and Motivation
Conversational search represents a paradigm shift in information retrieval (IR), moving from isolated, keyword-based queries to multi-turn, context-aware dialogues. The surveyed paper provides a systematic and technically rigorous overview of the field, emphasizing the integration of LLMs and the evolution of system architectures, evaluation protocols, and domain-specific applications. The authors delineate the limitations of traditional search engines in handling context-dependent queries and highlight the necessity for systems that can interpret anaphora, ellipsis, and evolving user intent across multiple conversational turns.
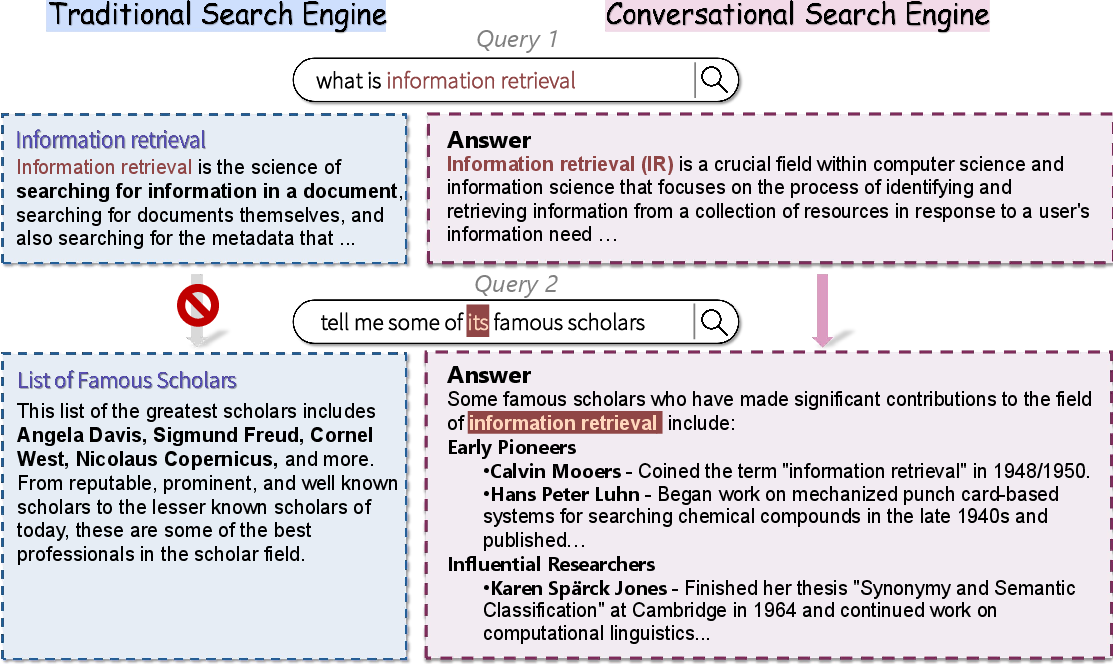
Figure 1: Comparison between a traditional search engine and a new conversational search engine on an original and its follow-up query, illustrating the inability of traditional systems to resolve context-dependent references.
System Architecture and Core Components
The paper formalizes the architecture of conversational search systems as comprising four principal modules: query reformulation, search clarification, conversational retrieval, and response generation. This modularization is both historically grounded and forward-looking, accommodating the increasing integration of LLMs that blur the boundaries between these components.
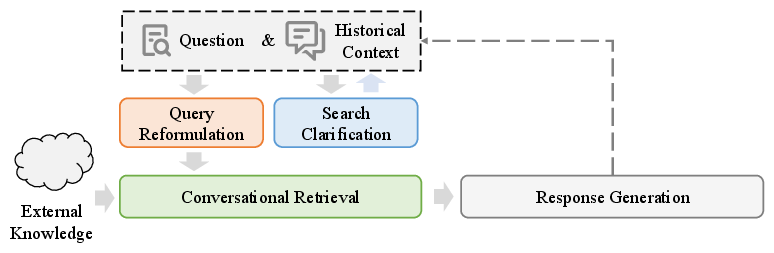
Figure 2: A typical workflow for a conversational search system, highlighting the four key components and their interactions.
Query reformulation is essential for resolving context-dependent phenomena such as anaphora and ellipsis, which are pervasive in conversational settings. The survey categorizes reformulation techniques into query expansion, query rewriting, and hybrid approaches. Query expansion leverages term classification and heuristic methods to append relevant context, while query rewriting transforms context-dependent queries into stand-alone forms, often using sequence-to-sequence models or reinforcement learning with retrieval-based rewards. Hybrid methods, particularly those leveraging LLMs, combine rewriting with generative expansion, yielding more robust reformulations.

Figure 3: An example illustrating the semantic phenomena of Anaphora and Ellipsis in conversational search, underscoring the necessity of query reformulation.
The authors note that while LLMs have improved the quality of reformulation, challenges remain in optimizing reformulation for downstream retrieval effectiveness, especially in long conversations where error accumulation and context noise are significant.
Search Clarification
Search clarification addresses the ambiguity and under-specification of user queries by enabling the system to proactively ask clarifying questions. The survey provides a taxonomy of clarification scenarios, including document retrieval, web search, question answering, and domain-specific settings. Methods for clarification range from candidate selection using retrieval and ranking models to generative approaches that synthesize clarifying questions conditioned on conversational context.
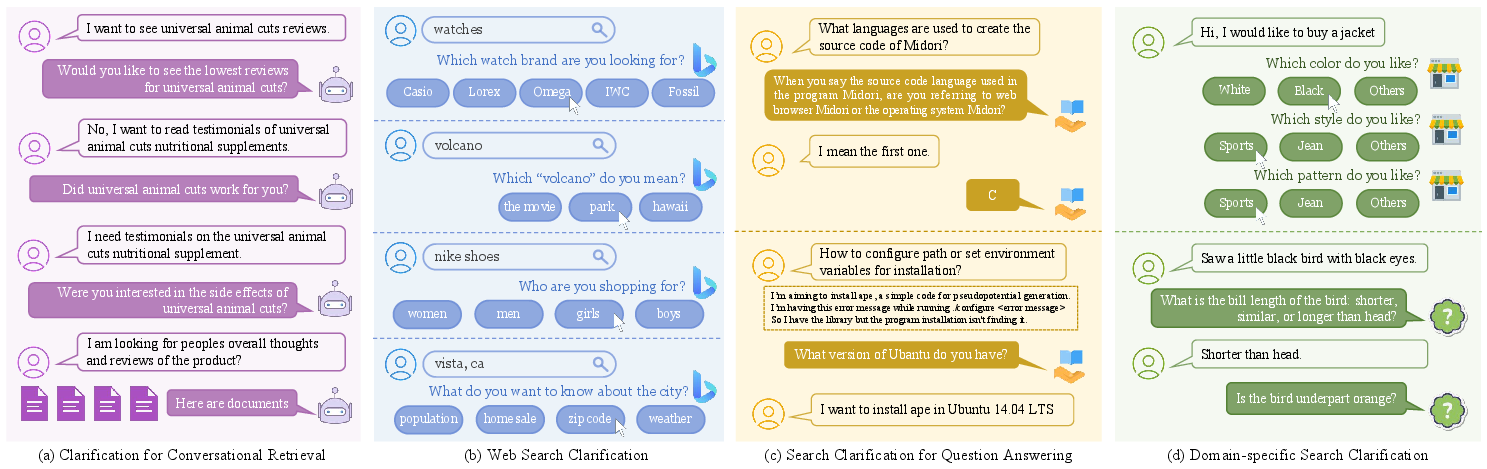
Figure 4: Different scenarios and examples of search clarification, demonstrating the breadth of application domains and interaction patterns.
The integration of LLMs has enabled zero-shot and few-shot clarification generation, but the paper highlights open questions regarding the optimal timing, granularity, and user modeling for clarification, particularly in mixed-initiative and domain-specific contexts.
Conversational Retrieval
Conversational retrieval extends traditional ad-hoc retrieval by incorporating multi-turn context modeling, context denoising, and data augmentation. The survey distinguishes between implicit and explicit context denoising: implicit methods use attention mechanisms and contrastive learning to downweight irrelevant history, while explicit methods select or filter context based on pseudo-labels or learned selectors.
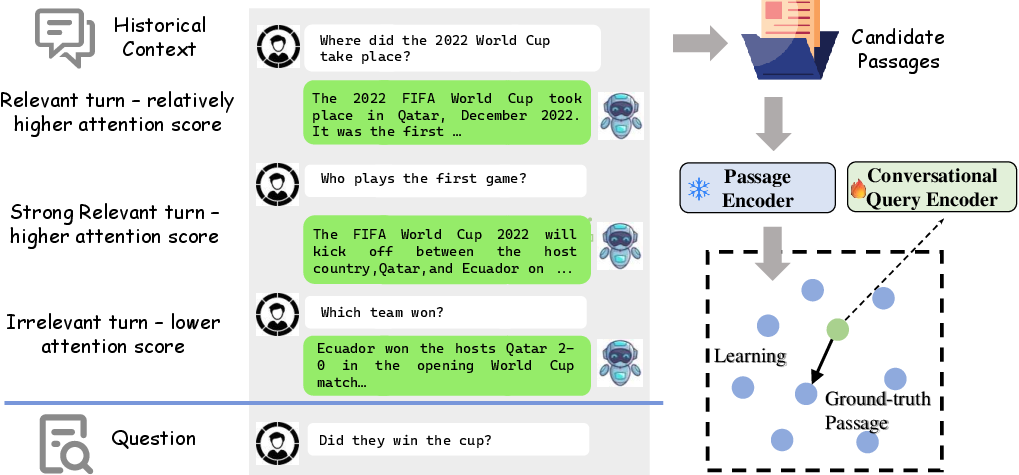
Figure 5: An example of end-to-end learning for conversational dense retrieval with implicit de-noising, showing varying degrees of historical turn relevance.
The authors emphasize the importance of data augmentation (e.g., synthetic session generation, contrastive sample mining) and interpretability (e.g., lexicalization of dense representations) for robust and explainable retrieval. The re-ranking stage is also discussed as critical for aligning retrieved content with the requirements of downstream response generation.
Response Generation
Response generation in conversational search is increasingly realized through retrieval-augmented generation (RAG) paradigms, where LLMs synthesize responses grounded in retrieved evidence. The survey discusses the challenges of integrating historical search results, modeling context dependencies, and attributing knowledge sources (citation labeling) in multi-turn settings.
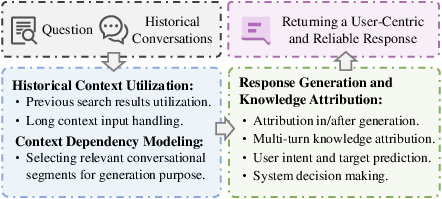
Figure 6: Overview of the conversational response generation system, highlighting the need for historical context utilization, context dependency modeling, and knowledge attribution.
The authors note that while LLMs have advanced the state of response generation, issues of hallucination, knowledge inconsistency, and long-context processing persist, particularly in high-stakes domains.
Domain-Specific and User-Centric Applications
Conversational search systems have been adapted to specialized domains such as medical, financial, legal, and multi-modal information retrieval. Each domain imposes unique requirements for knowledge representation, reasoning, and user interaction.
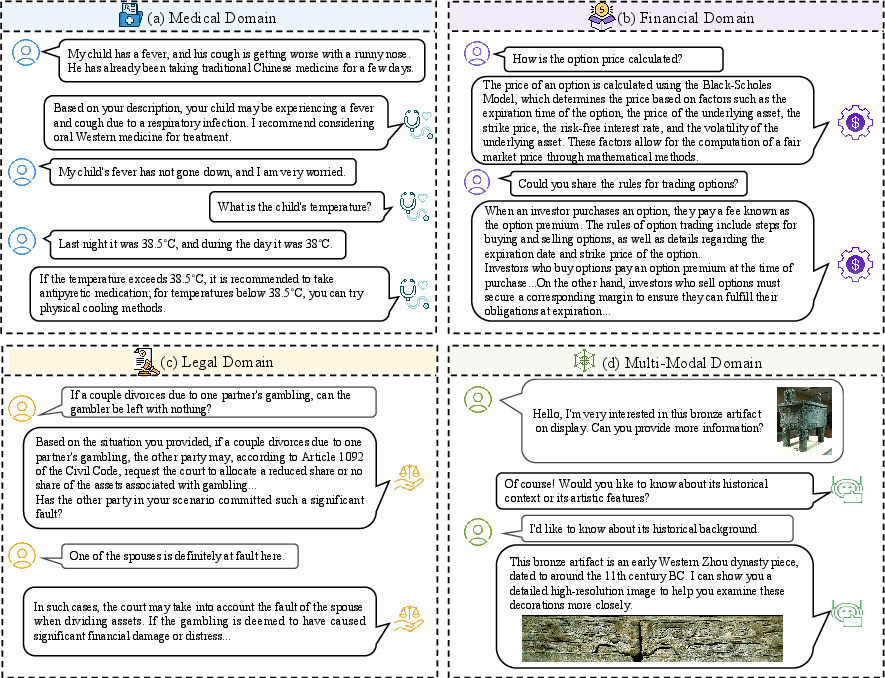
Figure 7: Typical examples of conversational search systems across medical, financial, legal, and multi-modal domains, each requiring specialized information processing.
The survey details the challenges of domain adaptation, including terminology alignment, data scarcity, and the need for faithfulness and reliability in generated responses. User-centric considerations, such as personalization, ethical bias mitigation, and privacy, are also addressed, with the authors advocating for evaluation protocols that reflect real-world user satisfaction and task completion.
Evaluation Protocols and Benchmarks
The paper provides a comprehensive review of evaluation methodologies, distinguishing between retrieval-based, generation-based, and user-based metrics. The authors critique the reliance on turn-level metrics and gold-standard answers, advocating for conversational-level, user-centric, and mixed-initiative evaluation frameworks. The limitations of current benchmarks in capturing the complexity of multi-turn, proactive, and personalized interactions are highlighted, and the need for high-fidelity user simulation and practical evaluation is emphasized.
Implications and Future Directions
The survey identifies several open research questions and directions:
- Intelligent Decision Making: Developing systems capable of dynamically selecting between clarification, retrieval, generation, and tool invocation based on dialogue state and user intent.
- Faithful and Abundant Resources: Advancing knowledge attribution and multi-modal integration to mitigate hallucination and improve response diversity.
- Proactive and Personalized Conversation: Enabling systems to proactively guide users and personalize responses based on user profiles and evolving goals.
- Practical Evaluation: Designing user simulations and benchmarks that reflect real-world conversational dynamics, error recovery, and long-term satisfaction.
- Informative Returns: Expanding the forms of system output beyond answers to include clarifications, recommendations, and multi-step plans.
- New Paradigms: Rethinking the architecture and objectives of conversational search in light of LLM capabilities, with an emphasis on end-to-end, user-aligned systems.
Conclusion
This survey provides a technically rigorous and comprehensive synthesis of conversational search, spanning foundational modules, LLM integration, domain adaptation, and evaluation. The field is characterized by rapid methodological evolution, driven by advances in LLMs and the increasing complexity of user requirements. The authors' analysis underscores the need for continued research in context modeling, proactive interaction, faithfulness, and user-centric evaluation, with significant implications for both academic research and the deployment of next-generation search systems.