- The paper introduces a regularized framework that reweights experiences by optimizing occupancy measures with KL divergence to reduce distribution shifts.
- It employs a modified SAC algorithm with a dedicated value network for precise TD error estimation and dynamic replay buffer reweighting.
- Experimental evaluations demonstrate that ROER outperforms conventional PER in both online and hybrid offline-to-online settings, improving learning stability.
Regularized Optimal Experience Replay: An Academic Analysis
This essay presents an in-depth analysis of the paper titled "ROER: Regularized Optimal Experience Replay" (2407.03995), which introduces a novel approach to Experience Replay in Reinforcement Learning (RL), focusing on optimal distribution adjustments through a regularized framework.
Overview and Objective
Experience replay is a cornerstone in the advancement of online RL, primarily due to its ability to enhance data utilization efficiency and stabilize learning processes. Prioritized Experience Replay (PER) is a prevalent method that reweights experiences based on Temporal Difference (TD) errors to accelerate RL training. However, PER faces challenges due to distribution shifts and lacks a comprehensive theoretical foundation. "ROER: Regularized Optimal Experience Replay" addresses these issues by proposing a novel framework that treats experience prioritization as an Occupancy Optimization problem, regulated through f-divergence, particularly using the Kullback-Leibler (KL) divergence.
Theoretical Foundations
The core innovation of ROER is its robust theoretical derivation connecting experience prioritization to occupancy measures between off-policy and optimal on-policy data distributions. This is achieved by introducing a regularized RL objective with an f-divergence regularizer. Through its dual formulation, the paper demonstrates that optimal reweighting can be derived by gradually shifting the replay buffer distribution towards the optimal on-policy distribution using TD-error-based occupancy ratios.
Occupancy vs. Distribution
The paper posits that the goal of effective experience prioritization is to mimic an optimal on-policy distribution by optimizing occupancy measures. By leveraging the KL divergence as a regularizer, it penalizes significant distribution discrepancies, thus maintaining proximity to the on-policy distribution, which reduces estimation errors and stabilizes TD errors.
Implementation Details
ROER is practically implemented using the Soft Actor-Critic (SAC) algorithm across various continuous control environments from MuJoCo and the DM Control benchmark suite. The practical implementation involves the integration of a separate value network for TD error estimation, guided by a modified Extreme Q-learning loss objective for accurate prioritization.
Algorithmic Pipeline
A detailed algorithmic pipeline for ROER includes initialization of neural networks, gradual updates of occupancy ratios using a convergence parameter λ, and periodic computation of TD errors for sample reweighting in the replay buffer. Importantly, hyperparameters such as loss temperature (β) and priority clipping thresholds are crucial for controlling the regularization strength and ensuring stability during the training process.
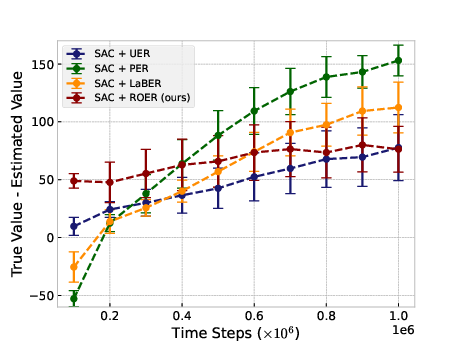
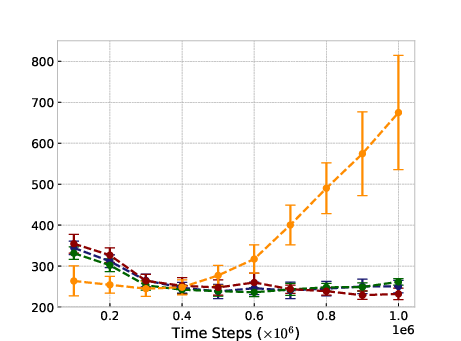
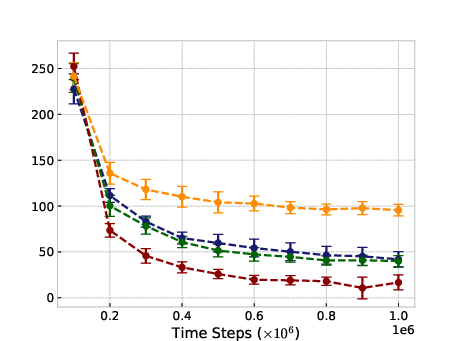
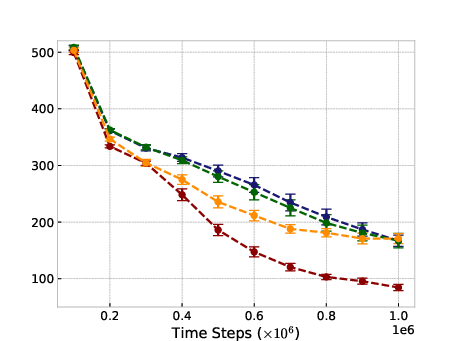
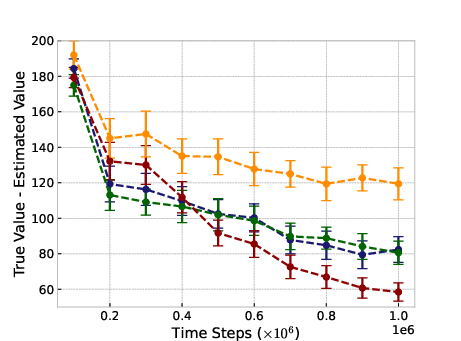
Figure 1: Ant-v2
Key Hyperparameters
The choice of regularizer strength β and the stabilization through clipping values for priorities play significant roles. Tuning these parameters is essential for optimal performance across diverse environments, indicating a close relationship between hyperparameter optimization and empirical success.
Experimental Evaluation
The empirical results showcase ROER's superior performance over conventional PER and other baselines in online settings and highlight its capacity to enhance learning in complex, sparse-reward environments through pretraining.
Online Settings
In typical online RL scenarios, ROER outperforms established methods in six out of eleven benchmark tasks, attributable to its refined value estimation and bias mitigation capabilities, as indicated by more accurate convergence to true value functions.
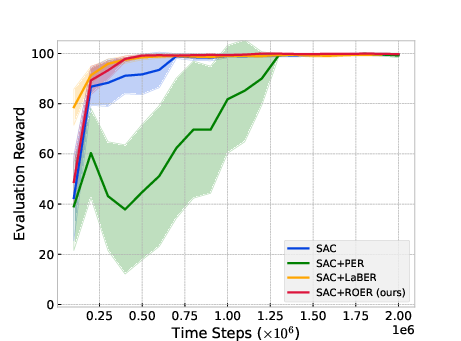
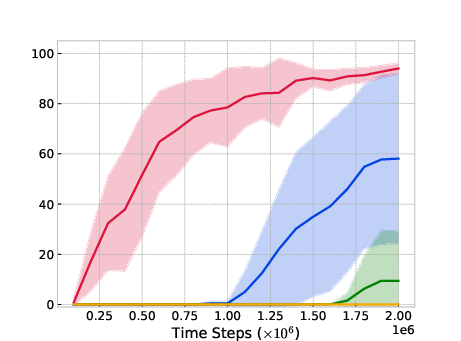
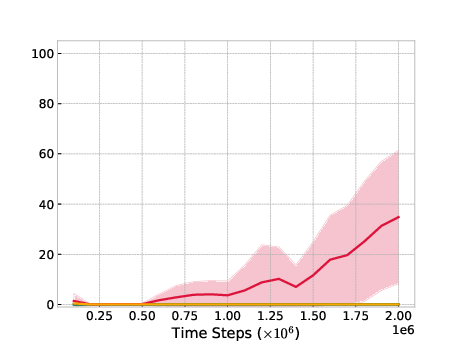
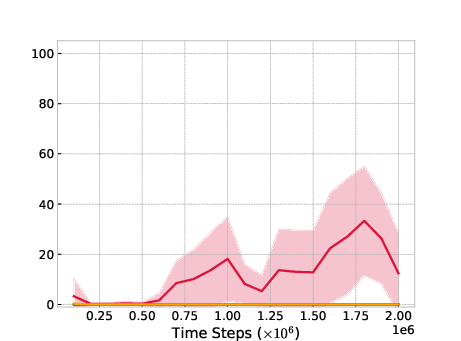
Figure 2: Umaze-V2
Transfer Learning Efficacy
A significant contribution of ROER lies in its adaptability to offline-to-online finetuning scenarios, as demonstrated in the Antmaze environment. When pretrained with offline data, ROER achieves marked improvements where other methods struggle, thus validating its potential in hybrid training paradigms.
Implications and Future Directions
ROER's integration of regularized divergences into experience replay marks a technical advancement in advancing policy optimization and enhancing training stability in RL. As a future direction, adaptive strategies for dynamically tuning loss temperatures could further automate and optimize the learning process. Extending ROER’s paradigm to broader offline RL contexts could also hold promise for robust, scalable RL methodologies.
Conclusion
Regularized Optimal Experience Replay introduces a formal, rigorous approach to rethinking experience prioritization in RL, buttressed by theoretical and empirical validation. It sets a foundation for future explorations into regularized RL frameworks that could substantially ameliorate the challenges associated with distribution shifts and sampling inefficiencies. The methodology elucidated herein is poised to have a pivotal impact on the development of scalable, efficient RL systems.