- The paper introduces ReaPER, which adjusts Q-value reliability in prioritized experience replay to improve learning stability in reinforcement learning.
- The authors integrate a reliability score based on downstream TDEs to refine transition prioritization beyond traditional PER methods.
- Empirical results demonstrate faster convergence and superior policy performance in various RL environments compared to standard PER.
Reliability-Adjusted Prioritized Experience Replay
The paper "Reliability-Adjusted Prioritized Experience Replay" presents an innovative approach to address target Q-value reliability issues in reinforcement learning (RL). By introducing Reliability-Adjusted Prioritized Experience Replay (ReaPER), the authors aim to improve learning efficiency and stability beyond the traditional Prioritized Experience Replay (PER).
Introduction
In reinforcement learning, experience replay is a critical component that augments data efficiency by storing agent-environment interactions. These interactions are later replayed to stabilize learning. The PER method samples transitions based on their temporal difference error (TDE), a proxy indicating potential learning impact. However, TDE can be unreliable due to approximation biases in predicted Q-values. ReaPER adjusts the sampling strategy by considering the reliability of these predictions, thus refining transition prioritization to enhance learning dynamics.
Theoretical Foundations
ReaPER introduces a reliability score for each transition, calculated as a function of downstream TDEs within an episode. The score effectively measures the likelihood that a target Q-value accurately reflects the true value function. The reliability-adjusted TDE, denoted Ψt=Rt⋅δt+, optimizes transition selection by balancing informative transitions against the reliability of their updates. This mitigates potential misdirection in policy learning due to unreliable updates.
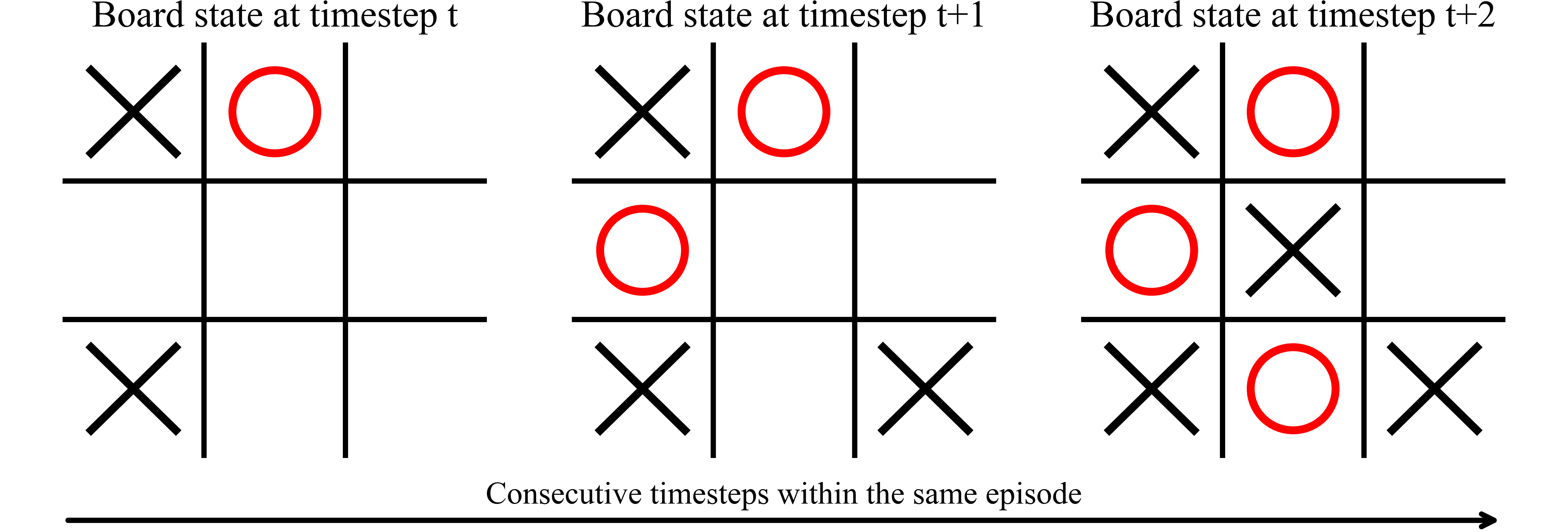
Figure 1: Subsequent states from a Tic Tac Toe game illustrating state evaluation dependencies and reliability in assessing transition values.
The authors rigorously prove that accounting for reliability enhances convergence. Under their assumptions, the sampling strategy of ReaPER reduces the expected error in value estimates more effectively than standard PER, particularly in environments with high output variability and approximation error.
Methodology
ReaPER's methodology integrates the reliability score into transition sampling. This process consists of:
- Reliability Score Calculation: An inverse relationship with downstream TDEs quantifies target reliability.
- Sampling Criterion: The reliability-adjusted TDE serves as the sampling weight, prioritizing transitions with substantial learning potential and reliable targets.
- Importance Sampling: To correct bias introduced by non-uniform sampling, ReaPER employs importance sampling weighted updates, maintaining the integrity of the learning objective.
Implementation
ReaPER can be applied within any off-policy RL framework, such as Q-learning or DQN. The sampling mechanism requires modification of the standard PER buffer, including:
- Tracking cumulative TDE sums for trajectories,
- Regularly updating the reliability scores based on new observations,
- Implementing adaptive priority adjustment through hyperparameters that scale TDE and reliability impacts.
Empirical Results
Experiments across various RL environments, from simple tasks like CartPole to complex scenarios in the Atari benchmark, demonstrate ReaPER's superior performance. Notably, ReaPER achieves faster convergence and higher policy stability, consistently outperforming traditional PER in both efficiency and peak policy performance.
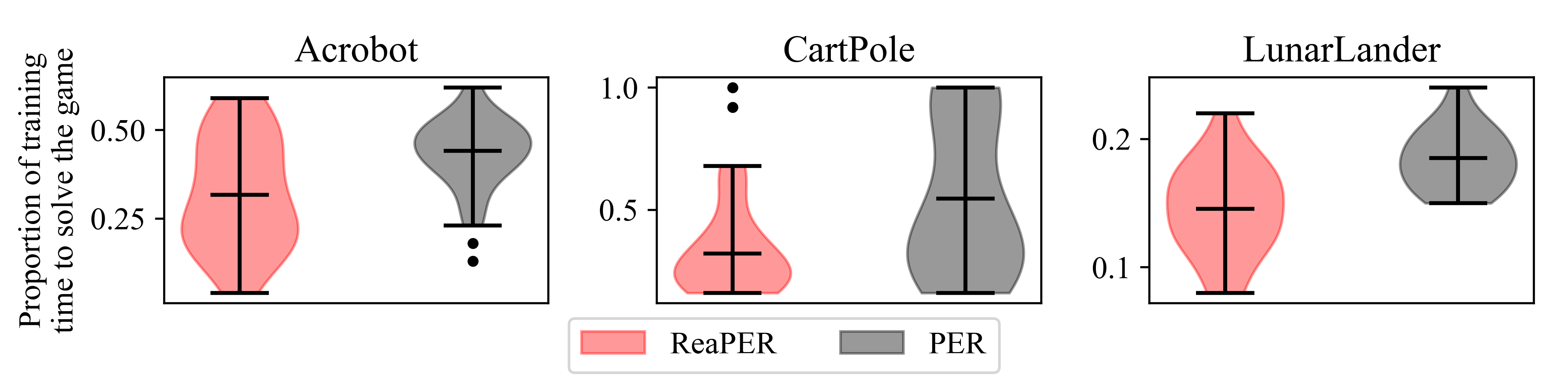
Figure 2: Evaluation scores per game from the Atari-10 benchmark, showing ReaPER's overall performance improvement over traditional PER.
Practical Implications
The ReaPER framework is particularly advantageous in environments where Q-value estimates are highly variable or when approximation errors are prevalent. As deep RL tasks increasingly involve complex, high-dimensional state spaces, ReaPER provides a robust mechanism to manage the inherent uncertainty in function approximation.
Conclusion
The research presented introduces a significant augmentation to experience replay techniques, with ReaPER effectively addressing the limitations posed by unreliable target estimations. By systematically incorporating reliability into the prioritization mechanism, ReaPER enhances both learning speed and stability, advocating for broader adoption in advanced deep RL applications. Future work may explore extending the reliability concept to actor-critic frameworks and integration with advanced neural architectures for further gains in RL efficiency.