Predictive PER: Balancing Priority and Diversity towards Stable Deep Reinforcement Learning
Abstract: Prioritized experience replay (PER) samples important transitions, rather than uniformly, to improve the performance of a deep reinforcement learning agent. We claim that such prioritization has to be balanced with sample diversity for making the DQN stabilized and preventing forgetting. Our proposed improvement over PER, called Predictive PER (PPER), takes three countermeasures (TDInit, TDClip, TDPred) to (i) eliminate priority outliers and explosions and (ii) improve the sample diversity and distributions, weighted by priorities, both leading to stabilizing the DQN. The most notable among the three is the introduction of the second DNN called TDPred to generalize the in-distribution priorities. Ablation study and full experiments with Atari games show that each countermeasure by its own way and PPER contribute to successfully enhancing stability and thus performance over PER.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (quick overview)
This paper is about teaching computers to learn from their past experiences more safely and effectively. It improves a popular trick in deep reinforcement learning called Prioritized Experience Replay (PER), which lets a game-playing AI study its most “important” memories more often. The authors show that if you focus too much on only a few “important” moments, the AI can become unstable and forget what it learned. They introduce Predictive PER (PPER), a new way to balance “priority” (important memories) with “diversity” (varied memories), making learning steadier and performance better.
The main questions the paper asks
- How can we keep the benefit of PER (faster learning) without letting it become unstable?
- Why do “priority outliers” (extremely high or low importance scores) and sudden “priority explosions” make an AI forget?
- Can we predict how important a memory will be and use that to keep priorities smooth and balanced?
- Does this actually help in practice across many games?
How the researchers approached the problem (in simple terms)
First, some quick translations:
- Reinforcement learning: An AI learns by trying actions and getting points (rewards), like learning to play an Atari game.
- Replay buffer: A big notebook of past memories (state, action, reward, next state) the AI can study from.
- PER (Prioritized Experience Replay): Instead of picking memories at random, the AI studies “more surprising” memories more often.
- TD error (temporal-difference error): How surprised the AI is by an outcome. It’s the difference between what it expected and what actually happened. Big TD error = “this memory teaches me a lot right now.”
The problem: If some memories get huge priority by accident (outliers) or priorities suddenly spike (explosions), the AI keeps re-reading the same few memories and ignores the rest. That lowers variety (diversity) and can make it forget earlier skills.
To fix this, the authors add three simple but clever steps to PER:
- TDInit: Start new memories with a priority based on what they actually show (their TD error), not the biggest priority seen so far. Think of it like grading each new homework by what it’s worth, not inflating its score because of a past record.
- TDClip: Gently cap (clip) priorities within a reasonable range that automatically adjusts as learning goes on. This is like a volume limiter that keeps the sound from blasting or going too quiet.
- TDPred: Add a small helper network that predicts how surprising a memory will be. This prediction smooths out random spikes and keeps priorities “bell‑shaped” (mostly near normal), so no single memory dominates. To keep it efficient, this helper shares layers with the main game-playing network.
Together, these three steps form Predictive PER (PPER). The idea is to keep both:
- Priority: study what matters.
- Diversity: don’t ignore the rest.
What they did and what they found
What they did:
- Tested on 58 Atari 2600 games using standard deep Q-learning setups (like Double DQN and dueling networks).
- Compared the original PER, each new step alone (TDInit, TDClip, TDPred), combinations, and the full PPER.
- Trained for 50 million steps per game, using the same settings for fairness.
- Measured “forgetting” (how much a score drops after it peaked), training performance (average and best scores over time), and final test scores.
Key results:
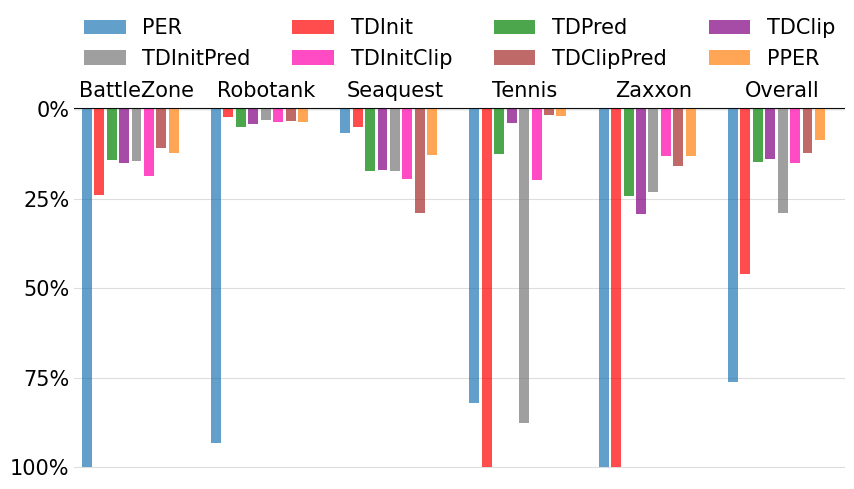
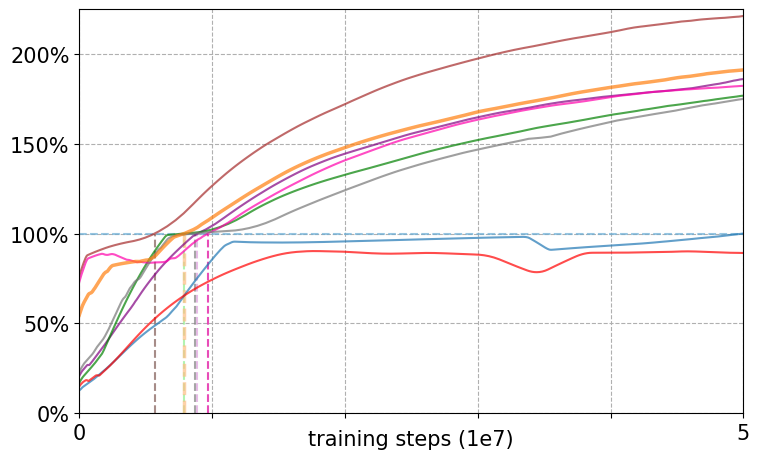
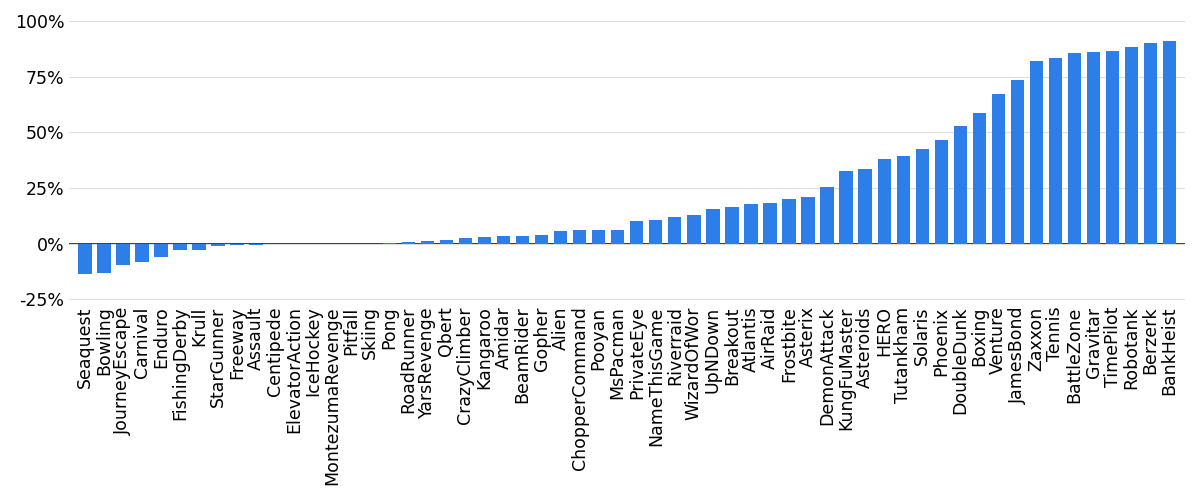
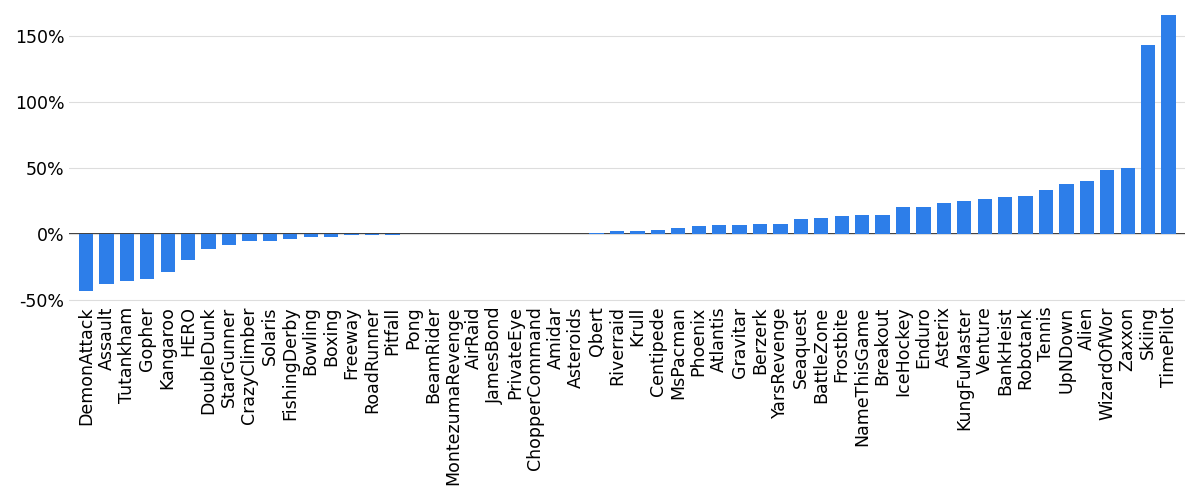
- Stability: PPER reduced forgetting in 42 out of 58 games. In plain language, the learning curves were smoother and less likely to crash after doing well.
- Performance while training: Average scores over time improved notably with PPER compared to PER. Even if the absolute best score reached was similar, PPER held strong performance for longer.
- Final test scores: In 34 out of 53 games, PPER’s best learned policy scored higher than PER’s when evaluated.
- Why it works: Priorities under PPER looked “bell‑shaped” and steady (fewer extreme values), which kept the learning balanced. The helper network (TDPred) reduced random spikes in “surprise,” and TDClip kept priorities in a reasonable range.
- Efficiency: The helper network added modest overhead (about 10.9% extra compute in one setup; less with a smaller helper), and still helped even when made smaller.
Why this matters:
- Balancing priority and diversity stops the AI from over-focusing on a small set of memories, which prevents sudden forgetting.
- Smoother, more stable training is crucial if you want reliable performance, not just occasional high scores.
What this could mean going forward
- Better stability for many AI systems: Any method that learns from a replay buffer (not just DQN) could benefit from this balance between priority and diversity.
- Practical improvements with little cost: The predictive helper is small and can share parts with the main network, making it a practical add-on.
- Safer learning in the real world: In robots, self-driving, or other changing environments, avoiding “explosions” and “outliers” in what the AI studies could reduce dangerous performance drops.
- A general lesson: Don’t chase only the “most exciting” lessons. A steady mix of important and varied experiences helps learning stick.
Knowledge Gaps
The paper leaves the following gaps, limitations, and open questions that future work could address:
- Lack of theoretical guarantees: no formal analysis of convergence, stability, or bias–variance behavior when priorities are clipped and/or predicted (effect of
TDClipandTDPredon off-policy learning, importance sampling corrections, and convergence of DQN under the modified sampling distribution). - Sampling bias from predicted priorities:
TDPred-based priorities can misorder true TD-errors; the resulting sampling bias and its impact on learning efficiency and fixed-point bias are not quantified or bounded. - Normality assumption in
TDClip: thresholds are chosen as if TD-errors were Gaussian; heavy-tailed, skewed, or multimodal TD-error distributions are not tested, and robust alternatives (e.g., quantile-based clipping, median/MAD) are not explored. - Missing diversity metrics: diversity is discussed qualitatively (distribution plots) but not measured; no quantitative metrics (e.g., entropy of
Dist, effective sample size, coverage of replay memory, fraction of unique samples) or correlation analyses with stability/forgetting are provided. - Exploration impact is untested:
TDInitremoves max-priority initialization for novel transitions, andTDClipcan cap high-TD outliers; downstream effects on exploring rare/novel states (e.g., under sparse rewards) are not analyzed or measured. - Self-referential training of
TDPred:TDPredis trained on samples drawn from the priority distribution it helps define; risks of feedback loops, mode collapse, or bias amplification are not analyzed; alternatives (e.g., uniform or mixed sampling forTDPredlabels) are not tested. - Calibration and accuracy of
TDPred: no diagnostics (calibration curves, error distributions, per-quantile accuracy) are reported to verify that predicted priorities reliably track true , especially for rare/high-error transitions. - Architectural/optimization choices for
TDPred: only a shared-convolution + FC head is tried; no comparison to alternative designs (e.g., auxiliary head on the DQN, separate target network forTDPred, different loss functions, regularizers, or training schedules/warm-up). - Hyperparameter sensitivity is underexplored: no systematic study of
α,β(PER exponents),λ(forgetting factor),ρ_min/max(clip multipliers), batch size, orM(head width) across tasks; guidelines for tuning and robustness to settings are missing. - Statistical rigor and reproducibility: number of seeds is unclear; training curves appear single-run without confidence intervals; no statistical tests on stability/performance metrics; code/seed release is not described.
- Limited benchmarks and baselines: results are restricted to Atari with DQN (double + dueling); no comparison against rank-based PER, Rainbow (full stack), or modern off-policy methods; uniform ER baseline and stronger data-augmentation baselines are not reported side-by-side.
- Generality beyond Atari: no experiments on continuous control (e.g., MuJoCo/DMControl), stochastic or partially observed domains, or long-horizon/sparse-reward tasks (e.g., Montezuma’s Revenge) where priority clipping could be harmful.
- Long-horizon behavior: training is capped at 50M frames; it is unknown whether PPER’s stability holds (or degrades) at longer budgets and whether forgetting reappears.
- Interaction with other algorithmic components: effects with n-step returns, distributional RL, noisy nets, auxiliary losses, or actor-critic methods (e.g., DDPG/TD3/SAC) are not studied.
- Importance sampling details: the choice/schedule of
βand its interaction with clipped/predicted priorities are not analyzed; whether IS still adequately compensates sampling bias underTDPred+TDClipis unverified. - Throughput and resource overhead: reported overheads are percent-of-DQN compute for select
M; there is no wall-clock, TPU/GPU utilization, memory footprint, or distributed-training scalability analysis. - Failure modes for small
M: authors note that Gaussian-like behavior can break for smallMin some games; conditions under which this happens and its impact on learning are not characterized. - Early training behavior:
TDPredis used to set initial priorities from the start; there is no warm-up phase or safeguards when the predictor is untrained, risking under-prioritizing informative novel transitions early on. - Aging/recency effects: the method addresses priority explosions/outliers but does not analyze how age of samples interacts with PPER (e.g., recency bias, forgetting of older experiences).
- Evaluation metrics: the “normalized_max_forget” measure is bespoke; sensitivity to noise, episode variability, and horizon choice is not explored; complementary metrics (e.g., area under learning curve, stability indices) could validate conclusions.
- Per-task heterogeneity: aggregated results obscure task-specific trade-offs (e.g., cases where stronger prioritization beats diversity); a taxonomy of when PPER helps vs. hurts is missing.
- Safety of clipping high-priority tails: upper clipping may suppress rare but crucial experiences; the paper lacks analyses of recall/retention for such events and strategies to avoid harmful truncation (e.g., capped-but-recency-boosted sampling).
- Alternative diversity mechanisms: no comparison to other diversity-promoting replay schemes (e.g., stratified/clustered sampling, novelty/coverage replay, reservoir stratification) to contextualize PPER’s benefits.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now by adapting the paper’s techniques (TDInit, TDClip, TDPred) to existing deep RL pipelines that already use experience replay or PER.
- Industry — Software/ML Engineering
- Application: Drop-in “Predictive PER” replay buffer for existing DQN-like off-policy RL training pipelines to reduce instability and catastrophic forgetting.
- Sector: Software tooling for ML, MLOps.
- Tools/Workflows: Integrate a PPER module into PyTorch/TensorFlow-based RL stacks or RLlib/Stable Baselines3 via:
- TDInit to replace max-priority initialization with TD-error–based initial priorities.
- TDClip with adaptive clipping bounds driven by an online TD-error mean estimator (with a forgetting factor λ), preventing outliers and priority explosions.
- TDPred network that reuses the agent’s convolutional trunk and adds a small FC head (e.g., M=128–512) to predict TD errors for smoother, Gaussian-like priority distributions.
- Monitor stability using a normalized_max_forget KPI and variance of priority distributions.
- Assumptions/Dependencies: Off-policy algorithms with replay buffers; access to TD-errors; minor extra compute for a small predictor head (≈6–11% of DQN cost reported); discrete actions easiest; continuous-control needs adaptation.
- Industry — Robotics (simulation-to-real training)
- Application: Stabilize warehouse/household robot skill learning by preventing priority explosions when robots encounter novel states during exploration.
- Sector: Robotics.
- Tools/Workflows: Use PPER during sim pretraining and online fine-tuning; share conv features between robot perception DQN and TDPred; employ TDClip to retain diverse samples from rare but critical states.
- Assumptions/Dependencies: Off-policy RL setup; reliable perception backbone shared with TDPred; safety wrappers for online learning.
- Industry — Recommender Systems and Ad Ranking
- Application: Reduce training oscillations in RL-based recommenders that use PER to optimize long-horizon engagement or revenue.
- Sector: Internet platforms, media, advertising.
- Tools/Workflows: Replace PER with PPER to avoid over-sampling recent spikes (e.g., trend shifts) and maintain diversity across user segments; log TD-error distribution dashboards and normalized_max_forget.
- Assumptions/Dependencies: Logged bandit/RL data, off-policy training; evaluation via counterfactual estimators; careful IS weighting.
- Industry — Finance and Trading
- Application: Stabilize off-policy RL agents trained on historical market data by smoothing priority distributions during regime changes.
- Sector: Finance.
- Tools/Workflows: TDPred-driven priorities reduce sensitivity to heavy-tailed TD-error spikes; TDClip preserves sampling of rare-market episodes for risk coverage.
- Assumptions/Dependencies: Strict risk controls; domain-specific validation; potential non-Gaussian TD-error distributions; compliance requirements.
- Industry — Energy and Operations (Grid/Building/Industrial Control)
- Application: Maintain stable training for RL-based controllers where operating regimes shift (e.g., seasonal demand).
- Sector: Energy, industrial operations.
- Tools/Workflows: Adaptive TDClip to prevent mode-specific priority explosions; ensure replay diversity to avoid forgetting rare failure modes; stability KPI tracking.
- Assumptions/Dependencies: High-fidelity simulators; safe exploration constraints; off-policy training cycles.
- Public Infrastructure — Traffic Signal Control and Mobility
- Application: Improve stability in RL traffic controllers trained with PER in SUMO or similar simulators, avoiding catastrophic forgetting under pattern changes.
- Sector: Transportation.
- Tools/Workflows: PPER-based replay, TDClip tuned to the current TD-error mean; scenario-level logging of priority variance and sample diversity.
- Assumptions/Dependencies: Simulator-driven data; staged deployment; monitoring under distribution shift.
- Academia — Benchmarking, Teaching, and Experimental Methodology
- Application: Use normalized_max_forget as a standard stability metric; adopt PPER in Atari and other benchmarks to study sample diversity vs. prioritization trade-offs.
- Sector: Research and education.
- Tools/Workflows: Open-source PPER baselines; ablation tracking of TDInit/TDClip/TDPred; reproducibility packs with priority distribution plots.
- Assumptions/Dependencies: Availability of standard RL environments; consistent hyperparameter protocols.
- Daily Life — Game AI Training and Hobbyist RL
- Application: More stable training for hobby projects in retro games or custom environments by swapping PER for PPER.
- Sector: Consumer/education.
- Tools/Workflows: Lightweight TDPred head (M=64–128) sharing conv layers; default TDClip parameters (ρmin≈0.12, ρmax≈3.7, λ≈0.9985); simple dashboards for forgetting and variance.
- Assumptions/Dependencies: Basic RL tooling; small compute budget; discrete action spaces preferred.
Long-Term Applications
Below are use cases that likely require further research, scaling, adaptation to different RL paradigms, safety assurance, or regulatory alignment.
- Safety-Critical Autonomy (Autonomous Driving, Healthcare Decision Support)
- Application: Use PPER as a stability regularizer in off-policy RL pipelines for safety-critical tasks where forgetting is unacceptable.
- Sector: Automotive, healthcare.
- Tools/Workflows: Combine PPER with offline RL, policy constraints, formal verification, and robust IS; enhanced logging of priority shifts to detect risk.
- Assumptions/Dependencies: Extensive validation beyond Atari; certification/regulation compliance; interpretability requirements for clinical settings; continuous-action adaptation.
- Lifelong and Continual RL
- Application: Memory-aware replay strategies that retain coverage over past regimes and tasks, using PPER to balance prioritization and diversity over time.
- Sector: Cross-sector autonomy and personalization.
- Tools/Workflows: Curriculum learning with adaptive TDClip; TDPred variants that condition on task/regime identifiers; priority governance across task boundaries.
- Assumptions/Dependencies: Scalable replay storage; mechanisms for task detection and non-stationarity handling.
- Distributed RL and Multi-Agent Systems
- Application: Extend PPER to distributed actors (e.g., Ape-X, IMPALA) and multi-agent settings with shared or per-agent priority predictors.
- Sector: Large-scale platforms, robotics swarms, network optimization.
- Tools/Workflows: Sharded replay buffers with synchronized TDClip thresholds; federated TDPred heads; cross-actor priority calibration.
- Assumptions/Dependencies: Communication overhead; consistency under delayed gradients; engineering for throughput.
- Edge/On-Device RL
- Application: Deploy compact PPER variants where the TDPred head is quantized or pruned, enabling smoother online learning on resource-constrained devices.
- Sector: IoT, mobile, wearables.
- Tools/Workflows: Model compression for TDPred; sharing feature extractors; adaptive TDClip with lightweight estimators; battery-aware scheduling.
- Assumptions/Dependencies: Limited compute and memory; need for low-latency priority updates; robust online safety.
- Education Technology — Adaptive Tutoring Systems
- Application: Stable personalization agents that avoid overfitting to recent student behavior and forgetting rare but important learning states.
- Sector: Education.
- Tools/Workflows: PPER-informed replay for logged student interactions; fairness-aware TDClip to prevent oversampling of specific cohorts; interpretable priority dashboards.
- Assumptions/Dependencies: Privacy constraints; fairness and bias audits; offline-to-online transfer.
- Healthcare Operations — Scheduling/Triage/Resource Allocation
- Application: RL-based operational decisions stabilized with PPER to preserve historical patterns and avoid sudden policy shifts caused by outlier events.
- Sector: Healthcare operations.
- Tools/Workflows: TDClip tuned for rare-event retention; robust IS; prospective trials in simulators; risk management dashboards for priority distributions.
- Assumptions/Dependencies: Strong governance; ethical and regulatory review; reliable offline datasets.
- Continuous Control (SAC, TD3, DDPG)
- Application: Adapt PPER concepts (predictive priorities, adaptive clipping) to actor-critic methods with continuous actions and different replay/IS mechanics.
- Sector: Robotics, industrial control, aerospace.
- Tools/Workflows: Predictive value/residual networks analogous to TDPred; clipped advantage/priorities; integration with entropy-regularized objectives.
- Assumptions/Dependencies: Redesign of priority definition (e.g., TD-error of critics); careful interaction with off-policy corrections.
- Human-in-the-Loop RL and Demonstration-Augmented Training
- Application: Predictive prioritization for demonstration data (DQfD/DDPGfD) that prevents overemphasis on noisy or atypical demos while preserving valuable examples.
- Sector: Robotics, enterprise systems.
- Tools/Workflows: Joint TDPred heads for demos and agent data; per-source TDClip; source-aware sampling strategies that maintain diversity.
- Assumptions/Dependencies: Heterogeneous data quality; design of per-domain clipping and IS weights; user experience considerations.
- Policy and Governance — AI Reliability Standards
- Application: Encode “maintain sample diversity” and “monitor forgetting” as best-practice standards for RL systems; PPER as a reference implementation.
- Sector: Public policy, standards bodies.
- Tools/Workflows: Stability metrics (normalized_max_forget), priority variance tracking, published thresholds for clipping; conformance tests on open benchmarks.
- Assumptions/Dependencies: Community consensus on metrics; standardization processes; transparency requirements.
- Data-Centric RL Productization
- Application: Commercial tools that visualize TD-error distributions, detect priority explosions, and auto-tune clipping thresholds to stabilize training.
- Sector: ML tooling.
- Tools/Workflows: “Priority Monitor” dashboards; auto-configuration of ρmin/ρmax and λ; alerts on diversity collapse; integrations with RLlib/Stable Baselines3.
- Assumptions/Dependencies: Access to replay buffer stats; organizational buy-in for MLOps observability; cross-environment generalization.
Notes on feasibility
- PPER’s empirical support comes from Atari 2600 (DQN variants), showing reduced forgetting and higher average performance; translating to other domains likely but needs validation.
- TDPred’s Gaussian-like and variance-reduced output depends on architecture width and training regime; benefits may vary in continuous control or highly non-Gaussian environments.
- Compute overhead is modest when sharing conv layers; on resource-constrained deployments, further compression is needed.
- PPER assumes off-policy training with replay buffers and access to TD-errors; on-policy methods or environments without replay require rethinking the approach.
Glossary
- Ablation study: An experimental method that removes or isolates components of a system to assess their individual impact. "Ablation study and full experiments with Atari games show that each countermeasure by its own way and PPER contribute to successfully enhancing stability and thus performance over PER."
- Behavior policy: The policy used to select actions during training, typically dependent on the current value function and sometimes incorporating exploration strategies. "The behavior policy maps each state to a distribution on and typically depends on the DQN (e.g., -greedy)."
- Bootstrapped target: A target value computed using a target network to stabilize temporal-difference updates. "The bootstrapped target $\hat Q^*(r, s'; \theta, \theta^-) := r + \gamma \cdot Q_{\theta^-}(s', \textstyle \Argmax_{a' \in \mathscr{A} Q_\theta(s', a'))$ \citep{DDQN2016}, where is the target DQN that has the same structure as , with its weights "
- ConvNet: A convolutional neural network architecture used for learning representations from inputs like images or frames. "We empirically found that TDPred must be a ConvNet to learn ."
- Deep Q-learning (DQL): A reinforcement learning method that learns a Q-function using deep neural networks. "Such extensions of ER were experimentally validated on the Atari games in the framework of deep Q-learning (DQL); the PER showed the promising performance improvement over the uniform ER \citep{DuelingDQN2015,PER2015,Rainbow2018}."
- Deep Q-network (DQN): A deep neural network that approximates the Q-function in reinforcement learning. "\citet{Atari2013, Atari2015} successfully implemented this technique with deep Q-network (DQN) to un-correlate the experiences and improve both sample efficiency and stability of the training process."
- Double DQN: An algorithmic variant of DQN that reduces overestimation by decoupling action selection and evaluation. "We experimentally validate the stability and performance of the three countermeasures and PPER by comparing them with PER, all applied to Atari games with double DQN and dueling network structure."
- Dueling network structure: A neural network architecture that separates state-value and advantage estimation to improve learning efficiency. "We experimentally validate the stability and performance of the three countermeasures and PPER by comparing them with PER, all applied to Atari games with double DQN and dueling network structure."
- Epsilon-greedy: A stochastic action selection strategy that chooses random actions with probability epsilon to encourage exploration. "The behavior policy maps each state to a distribution on and typically depends on the DQN (e.g., -greedy)."
- Experience replay (ER): A technique that stores past transitions to sample them later for training, reducing correlation and improving data efficiency. "Experience replay (ER) stores sequential transition data, called experiences or transitions, into the memory and then sample them uniformly to (re-)use in the update rules \citep{ER1992}."
- Forgetting factor: A parameter used in adaptive estimation to discount older observations in non-stationary settings. "The forgetting factor , which we set in all of the experiments, compensates the non-stationary nature of the TD error distribution."
- Gaussian-like distribution: A distribution resembling a normal distribution, often used to describe smoothed model outputs or priority distributions. "Likewise, as in Figure~\ref{fig:ablation:various figs}(c) and Appendix~\ref{appendix:ablation study}, the priority~ of TDPred (under small variance), updated proportionally to , has a Gaussian-like distribution, eventually."
- Importance sampling (IS): A weighting technique used to correct sampling bias when training on non-uniformly sampled data. "and with importance sampling (IS), the DQN weights (lines~\ref{line:PERBatchUpdateStart}--\ref{line:PERUpdateTheta})."
- No-ops start test: An evaluation protocol for Atari that starts episodes with a random number of no-op actions to test robustness. "For and , we take the average score over 200 repetitions of the no-ops start test with the best-performing model \citep{Atari2015, DDQN2016}."
- Non-stationary nature: The characteristic of environments or data distributions that change over time, complicating learning stability. "This success technically relies on the advances in the deep learning plus a series of methods---slow target network update, experience replay, etc. (e.g., see \citealp{Atari2013, Atari2015})---to alleviate the detrimental effects of the non-stationary nature, temporal data correlation, and the inefficient use of data."
- PER (Prioritized experience replay): A variant of experience replay that samples transitions according to priority measures (e.g., TD error) rather than uniformly. "Prioritized experience replay (PER) samples important transitions, rather than uniformly, to improve the performance of a deep reinforcement learning agent."
- PPER (Predictive PER): An enhanced version of PER that balances prioritization with diversity using TDInit, TDClip, and TDPred. "Our proposed improvement over PER, called Predictive PER (PPER), takes three countermeasures (TDInit, TDClip, TDPred) to (i) eliminate priority outliers and explosions and (ii) improve the sample diversity and distributions, weighted by priorities, both leading to stabilizing the DQN."
- Power-law priority distributions: Heavy-tailed distributions in which many priorities are near zero and a few are extremely large. "This can reduce priority outliers as the distribution is symmetric and heavily centered at the mean, whereas the power-law priority distributions in PER and TDInit are heavily tailed, skewed towards and dense near zero."
- Prioritized sweeping: A planning or learning technique that prioritizes updates based on expected impact, closely related to PER’s use of TD errors. "The underlying idea of PER is known as prioritized sweeping, which prioritizes the samples in proportion to their absolute TD errors."
- Priority distribution: The distribution of priority values across stored experiences in the replay memory. "We also define priority distribution $\mathscr{P}_\mathscr{D}(p) := \smash{\sum_{i = 1}^N} \mathbb{1}(p = p_i) \slash N$, where is the indicator function."
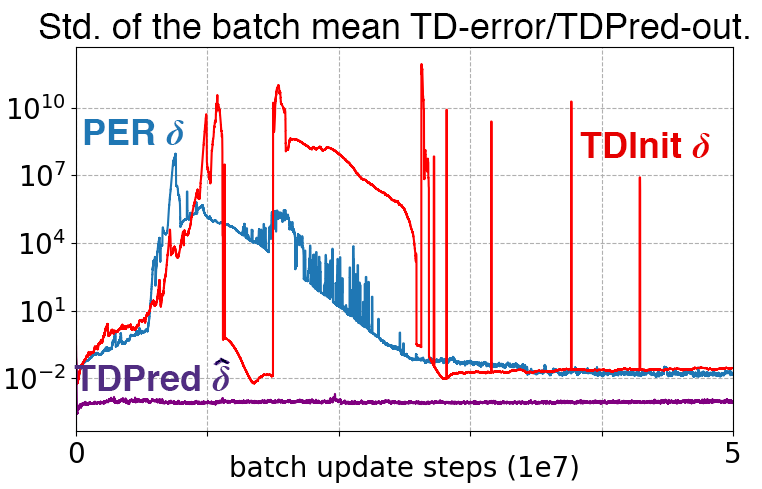
- Priority explosions: Abrupt, widespread increases in priorities that destabilize sampling and learning. "Priority explosions refer to abrupt increases of priorities over time: they generate a bulky amount of extremely large priorities in a period of time, making the current priorities relatively but extremely small, hence resulting in a massive amount of priority outliers, with unstable priority and experience distributions."
- Priority outliers: Experiences with extremely high or low priority that distort sampling diversity and stability. "Priority outliers are experiences with extremely large or small priorities: they make the experience distribution towards $1(p_i = p_N) \slash N'$."
- Proportional-based PER: A PER variant where priority is proportional to the absolute TD error. "In this paper, we improve PER \citep[proportional-based]{PER2015}."
- Rank-based prioritization: A PER variant where sampling priority is based on rank ordering of TD errors rather than their magnitude. "It is either proportional to its absolute TD-error (proportional-based) or inversely to the rank of the absolute TD-error in the memory (rank-based)."
- Replay memory: The storage buffer that holds past transitions for sampling during training. "It has a prioritized replay memory ."
- Stochastic gradient descent: An optimization method that updates parameters using noisy gradient estimates from sampled data. "The corresponding stochastic gradient descent update is:"
- Target DQN: A separate, slowly updated network used to compute stable targets for learning in DQN. "where is the target DQN that has the same structure as , with its weights "
- TD error (Temporal-difference error): The difference between predicted value and bootstrapped target, often used as a priority signal in PER. "Compute the TD error "
- TDClip: A method that statistically clips TD errors to bound priorities and reduce outliers. "The second is TDClip, which upper- and lower-clips priorities using stochastically adaptive thresholds."
- TDInit: A method that initializes priorities based on the current TD error instead of the historical maximum to avoid outliers. "The first one is TDInit: for new experiences, PER assigns the maximum priority ever computed; we instead assign priorities proportionally to their TD errors, as batch priority updates work in the original PER."
- TDPred: A predictive neural network that estimates TD errors to smooth and stabilize priority assignments. "Finally and most notably, we use a DNN called TDPred that is trained to estimate TD errors (hence, priorities)."
- Variance reduction: The process or effect of decreasing variability in model outputs or priority estimates to improve stability. "The use of TDPred therefore results in variance reduction of its outputs 's (hence, the priorities 's) while keeping the bias reasonably small."
Collections
Sign up for free to add this paper to one or more collections.