- The paper introduces MARNet, which integrates cross-modal diffusion reconstruction with embedding matching alignment to mitigate feature discrepancies.
- The methodology leverages contrastive learning and diffusion models to robustly fuse visual and textual features for enhanced performance.
- Experimental results on datasets like Vireo-Food172 and Ingredient-101 demonstrate significant improvements in classification accuracy over baseline models.
Unifying Visual and Semantic Feature Spaces with Diffusion Models for Enhanced Cross-Modal Alignment
Introduction
The paper presents a Multimodal Alignment and Reconstruction Network (MARNet), which addresses the challenges of aligning visual and semantic feature spaces in multimodal learning. The core innovation of this approach is the integration of a cross-modal diffusion reconstruction module that ameliorates feature distribution discrepancies across different modalities. This is particularly critical in applications like image classification, where variations in visual data due to lighting and perspective can hinder model performance. By combining visual and textual information, MARNet aims to enhance robustness against visual noise through a dual strategy: embedding matching alignment (EMA) and cross-modal diffusion reconstruction (CDR).
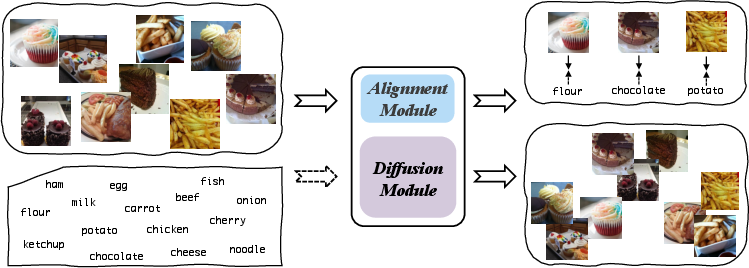
Figure 1: The proposed MARNet schematic diagram. The network mainly comprises alignment and diffusion modules, wherein the alignment module matches and aligns image and text information, and the diffusion module reconstructs the distribution of image information
.
Methodology
Overall Architecture
MARNet receives image-text pairs as input, which are processed through vision and text neural networks to produce initial representations xv and xs. The framework includes the EMA and CDR modules, which handle multimodal representations and output xEMA and xCDR, respectively. The final fused representation enhances model performance in classification tasks.
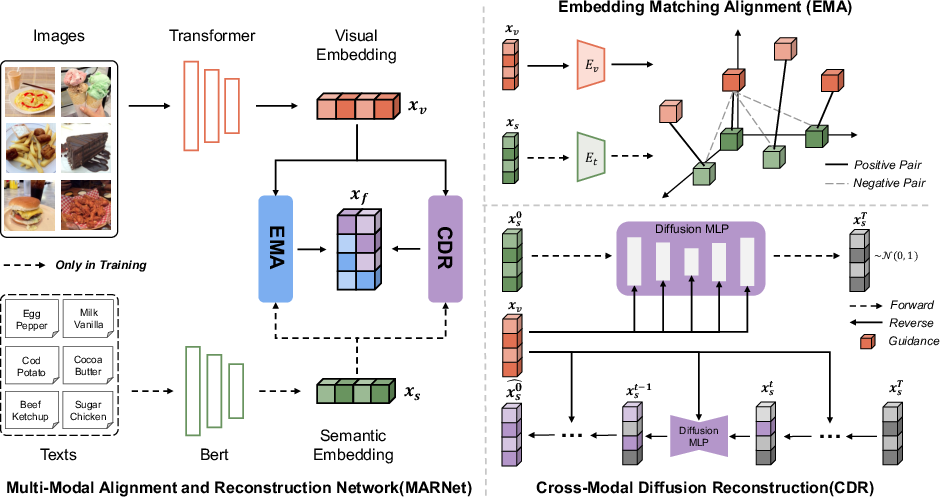
Figure 2: The framework diagram of MARNet. The input to MARNet is image-text data pairs, processed for vision and text to obtain xv and xs. Modules EMA and CDR handle multimodal representations, outputting xEMA and xCDR
.
Embedding Matching Alignment (EMA) Module
EMA leverages contrastive learning by implementing an improved instance-wise alignment approach based on InfoNCE. This module contrasts positive and negative sample pairs to enforce a similarity in the representation space, thereby aligning the visual and semantic features more effectively.
Cross-Modal Diffusion Reconstruction (CDR) Module
CDR utilizes a diffusion model guided by semantic representations to reconstruct visual representations, addressing discrepancies in feature distribution. Through this process, noise inherent in visual features is systematically reduced, leading to improved robustness in feature representation.
Fusion Strategy
Final feature representations from EMA and CDR modules are fused using various techniques such as concatenation and summation to enhance the interaction between modalities. This fused representation is then employed for image classification tasks.
The study evaluates MARNet on Vireo-Food172 and Ingredient-101 datasets, demonstrating significant improvements in classification accuracy over baseline models. Specifically, MARNet's inclusion of textual information and robust alignment strategies yields higher performance metrics compared to previous alignment frameworks.
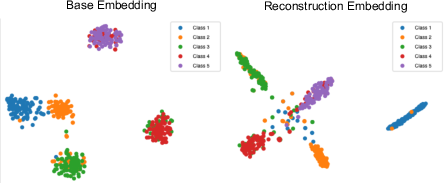
Figure 3: Visualization of the basic representation xv and reconstructed representation xCDR
.
Ablation Studies
Ablation experiments illustrate the individual contributions of the EMA and CDR modules. The EMA module notably enhances alignment through text-derived high-quality features, while the CDR module further solidifies the representation by addressing noise and improving feature robustness. The combination of both modules showcases the optimal performance of MARNet.
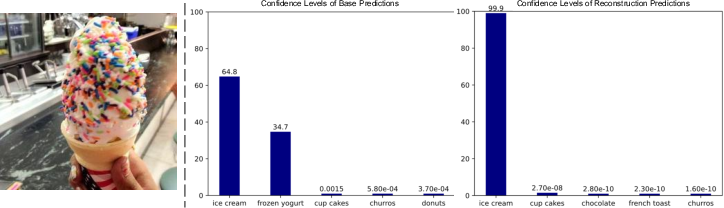
Figure 4: Prediction results of the basic module and CDR module. The minimal confidence values are represented in scientific notation, e.g., 6.4e-1 indicates 0.64
.
Conclusion
MARNet offers a novel approach to multimodal feature alignment by integrating cross-modal diffusion models with traditional alignment strategies. This work underscores its practical significance in improving image classification tasks under varied conditions. Future work could explore further optimizations in diffusion model noise reduction strategies to preserve original feature integrity more effectively.