- The paper introduces NECHO v2 that robustly predicts sequential diagnoses using curriculum data erasing guided knowledge distillation.
- It modifies the architecture to address uncertain multimodal incompleteness by dynamically handling modality dominance in electronic health records.
- Experimental results on MIMIC-III demonstrate improved top-k accuracy compared to traditional joint learning and KD methodologies.
Overcoming Uncertain Incompleteness for Robust Multimodal Sequential Diagnosis Prediction via Curriculum Data Erasing Guided Knowledge Distillation
Introduction
The paper "Overcoming Uncertain Incompleteness for Robust Multimodal Sequential Diagnosis Prediction via Curriculum Data Erasing Guided Knowledge Distillation" (2407.19540) introduces NECHO v2, an advanced framework crafted to address the complexities associated with multimodal sequential diagnosis prediction (SDP) in environments where data incompleteness due to uncertain missing visit sequences is prevalent. Traditionally, SDP relies on comprehensive multimodal datasets—comprising clinical notes, demographics, and medical codes—to predict future diagnoses. However, real-world clinical settings often suffer from missing data due to various factors such as privacy concerns and equipment anomalies, thereby presenting a significant barrier to accurate healthcare analytics. This research pioneers a solution by modifying the NECHO framework to dynamically handle the uncertain dominance of modality representation in the presence of incomplete data and leverages a systematic approach to knowledge distillation (KD) augmented with curriculum-driven data erasing.
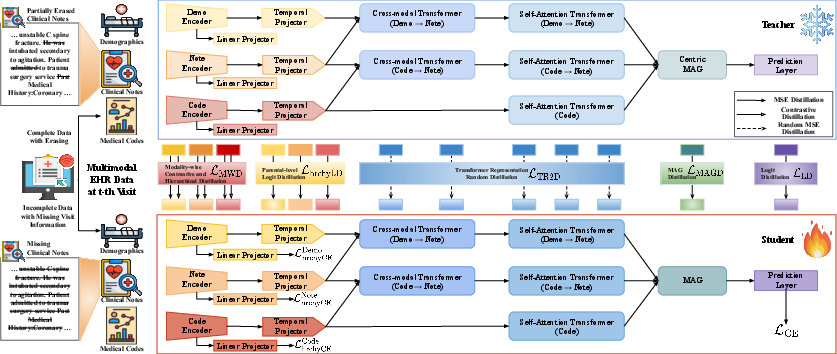
Figure 1: The Visualisation of Our Proposed Framework, NECHO v2.
Methodology
Problem Statement
The paper explores three critical components in diagnosing prediction problems for electronic health records (EHR) data: demographics, clinical notes, and diagnosis codes structured in hierarchical levels from detailed medical codes to broader disease-typing categories. Missing data in these components generate diverse missing patterns, which are systematically handled using NECHO v2 to predict the diagnostic codes appearing in the subsequent patient visits.
NECHO v2 Framework
Modification of NECHO: The original NECHO framework's limitation in handling incomplete data is rectified by altering its architecture. It replaces the cross-modal transformer dedicated to demos and codes with one focusing on demos and notes, thus reducing bias from medical codes. Furthermore, the integration of TinyBERT as a text encoder enhances the model's adaptability across various datasets beyond MIMIC-III.
Systematic Knowledge Distillation: The authors implement a KD pipeline in which NECHO serves as both teacher and student models. Through modality-wise contrastive and hierarchical distillation, transformer representation random distillation, and other techniques, semantic knowledge transfer is achieved effectively. This pipeline ameliorates representation discrepancies by adopting contrastive learning to accentuate both similarities and differences in modality-specific semantic distributions.
Data Augmentation via Random Erasing: NECHO v2 employs a unique data augmentation strategy simulating missing visit sequences through random single-point erasing. This approach minimizes data distribution gaps and enhances the KD process, fostering effective representation transfer despite incomplete data scenarios.
Experimental Results
The study evaluates NECHO v2 against other joint learning and KD methodologies using top-k accuracy metrics on MIMIC-III data. NECHO v2 exhibits superior performance, establishing itself as a robust solution across balanced and imbalanced missing data setups. Its performance gains stem from effectively addressing modality significance, systematic KD implementation, and employing single-point erasure to optimize the disparity in data distributions.
Ablation Studies
Ablation studies further validate the efficacy of individual components within NECHO v2. Modality-wise contrastive distillation occasionally outperforms without it, yet its consistent application typically boosts performance. Intermediate supervision through systematic KD, including $\mathcal{L}_{\text{TR2D}$ and $\mathcal{L}_{\text{MAGD}$, proves crucial, alongside the positive influence of data augmentation strategies.
Comparative Studies
Comparative analyses against varying teacher-student configurations and transformer distillation underscore NECHO v2's advantages in pairing methodologies and randomizing distillation to counteract overfitting and enhance teacher-student alignment.
Conclusion
NECHO v2 emerges as an effective framework for addressing uncertain missing sequences in multimodal SDP. By modifying NECHO to accommodate fluctuating modality dominance and systematically implementing KD complemented by data erasure strategies, the framework promises robust performance improvements in multimodal healthcare prediction tasks. The findings illustrate NECHO v2's potential applicability and pave the way for future advancements in AI-driven clinical diagnostics.