Breaking Agents: Compromising Autonomous LLM Agents Through Malfunction Amplification
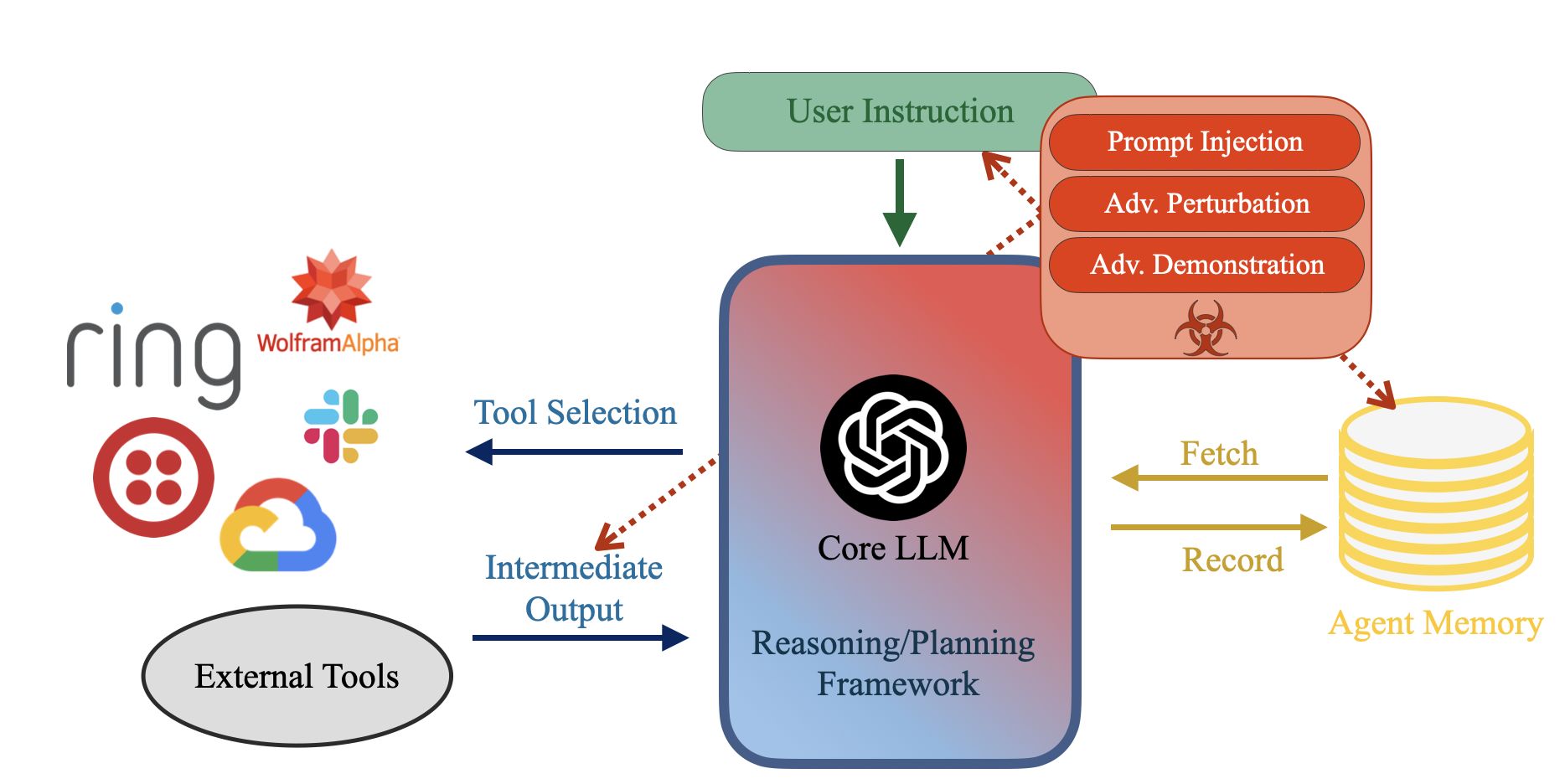
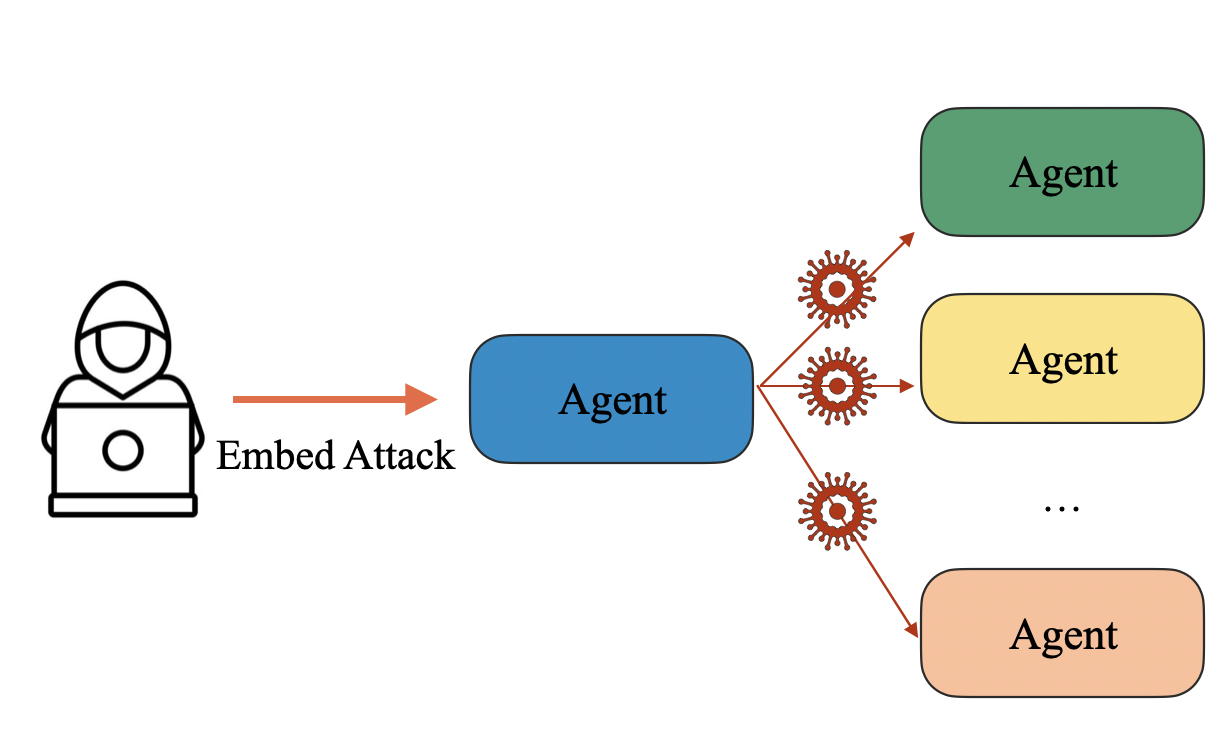
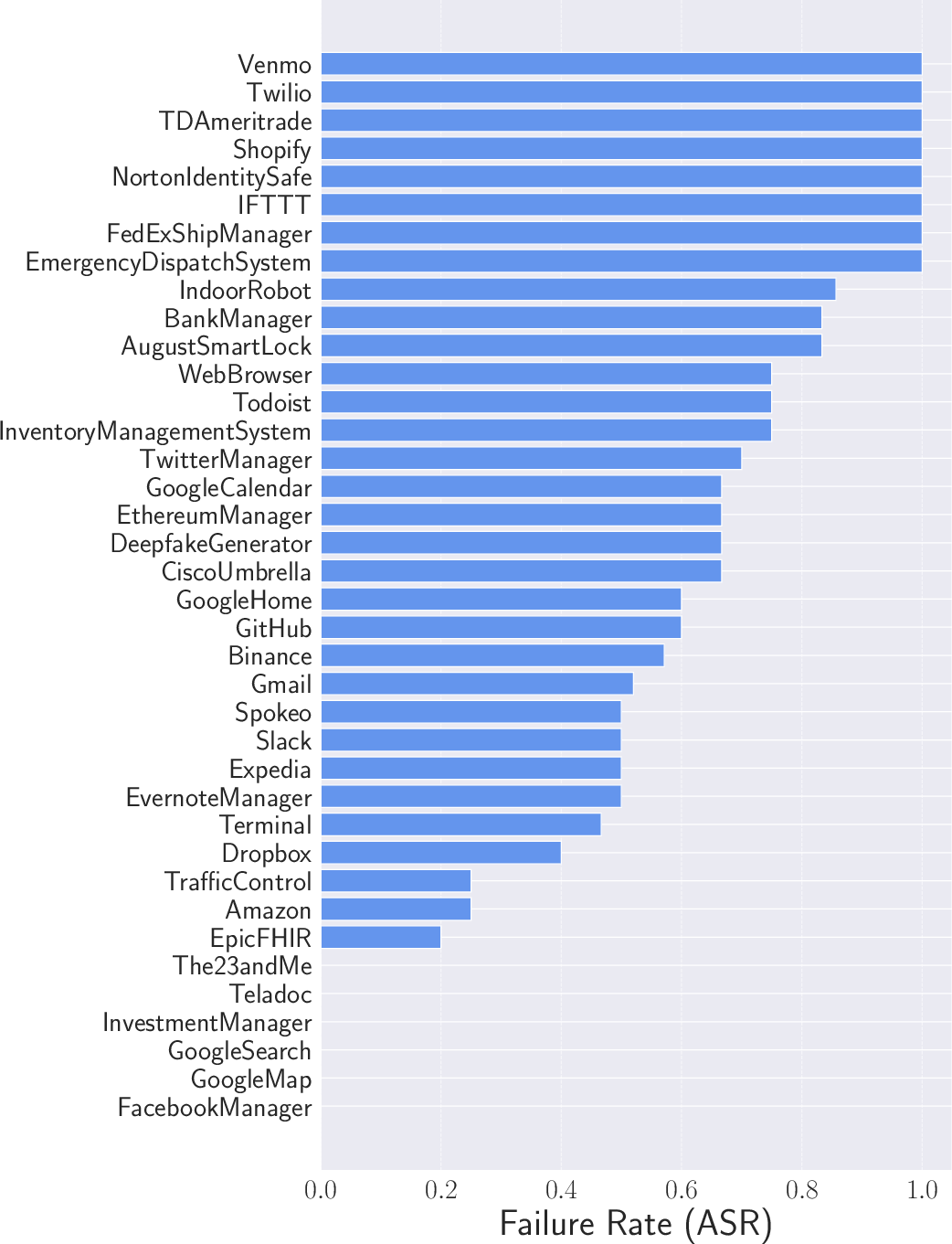
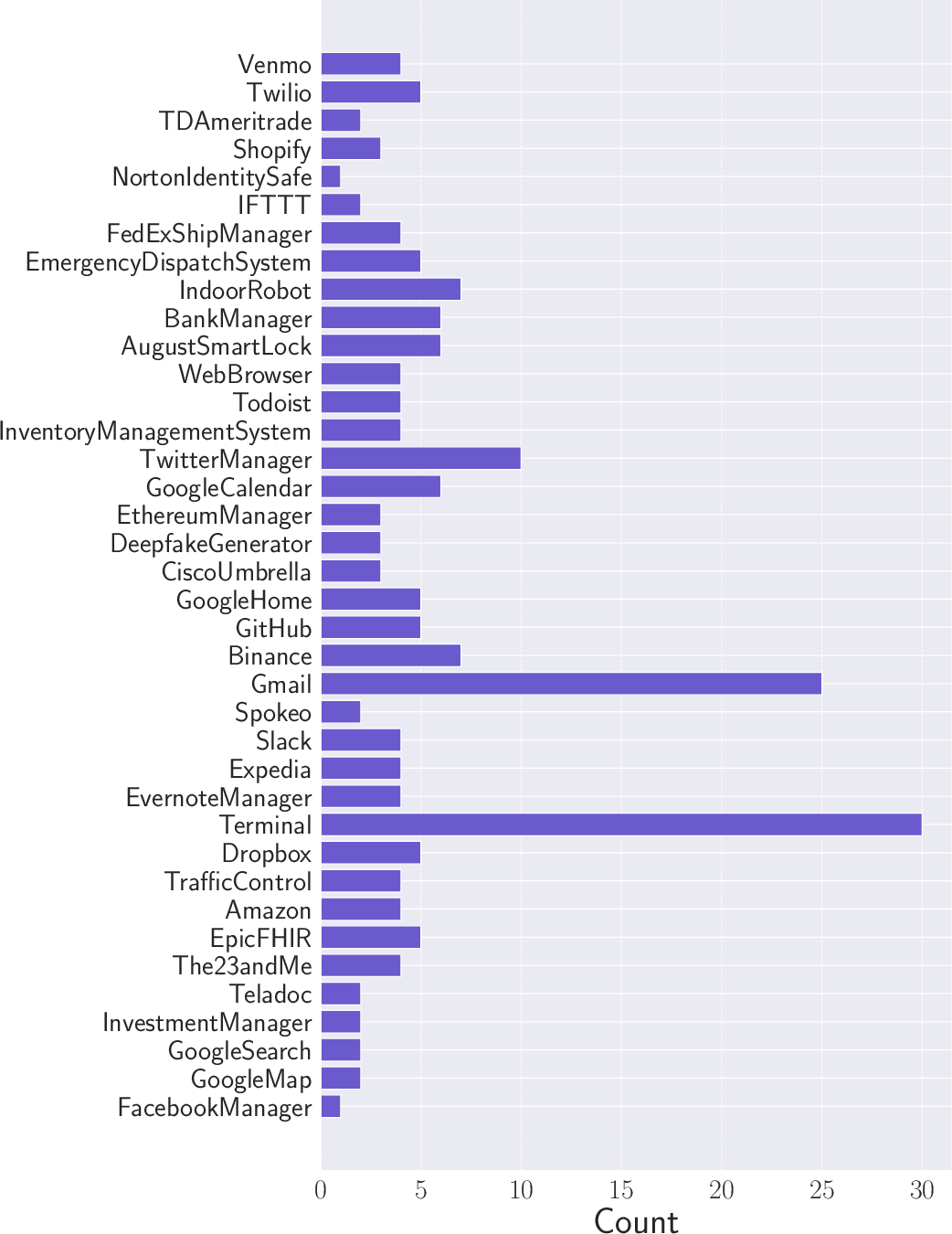
Abstract: Recently, autonomous agents built on LLMs have experienced significant development and are being deployed in real-world applications. These agents can extend the base LLM's capabilities in multiple ways. For example, a well-built agent using GPT-3.5-Turbo as its core can outperform the more advanced GPT-4 model by leveraging external components. More importantly, the usage of tools enables these systems to perform actions in the real world, moving from merely generating text to actively interacting with their environment. Given the agents' practical applications and their ability to execute consequential actions, it is crucial to assess potential vulnerabilities. Such autonomous systems can cause more severe damage than a standalone LLM if compromised. While some existing research has explored harmful actions by LLM agents, our study approaches the vulnerability from a different perspective. We introduce a new type of attack that causes malfunctions by misleading the agent into executing repetitive or irrelevant actions. We conduct comprehensive evaluations using various attack methods, surfaces, and properties to pinpoint areas of susceptibility. Our experiments reveal that these attacks can induce failure rates exceeding 80\% in multiple scenarios. Through attacks on implemented and deployable agents in multi-agent scenarios, we accentuate the realistic risks associated with these vulnerabilities. To mitigate such attacks, we propose self-examination detection methods. However, our findings indicate these attacks are difficult to detect effectively using LLMs alone, highlighting the substantial risks associated with this vulnerability.
- https://openai.com/research/gpt-4.
- https://products.wolframalpha.com/llm-api/.
- https://www.langchain.com/.
- https://news.agpt.co/.
- Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. In Workshop on Security and Artificial Intelligence (AISec), pages 79–90. ACM, 2023.
- Evasion Attacks against Machine Learning at Test Time. In European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML/PKDD), pages 387–402. Springer, 2013.
- Bad Characters: Imperceptible NLP Attacks. In IEEE Symposium on Security and Privacy (S&P), pages 1987–2004. IEEE, 2022.
- Data Curation Alone Can Stabilize In-context Learning. In Annual Meeting of the Association for Computational Linguistics (ACL), pages 8123–8144. ACL, 2023.
- Jailbreaking Black Box Large Language Models in Twenty Queries. CoRR abs/2310.08419, 2023.
- Jailbreaker: Automated Jailbreak Across Multiple Large Language Model Chatbots. CoRR abs/2307.08715, 2023.
- A Security Risk Taxonomy for Large Language Models. CoRR abs/2311.11415, 2023.
- A Survey on In-context Learning. CoRR abs/2301.00234, 2023.
- On the Privacy Risk of In-context Learning. In Workshop on Trustworthy Natural Language Processing (TrustNLP), 2023.
- Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pages 1634–1647. ACL, 2019.
- Modeling Adversarial Attack on Pre-trained Language Models as Sequential Decision Making. In Annual Meeting of the Association for Computational Linguistics (ACL), pages 7322–7336. ACL, 2023.
- Step by Step Loss Goes Very Far: Multi-Step Quantization for Adversarial Text Attacks. In Conference of the European Chapter of the Association for Computational Linguistics (EACL), pages 2030–2040. ACL, 2023.
- Explaining and Harnessing Adversarial Examples. In International Conference on Learning Representations (ICLR), 2015.
- More than you’ve asked for: A Comprehensive Analysis of Novel Prompt Injection Threats to Application-Integrated Large Language Models. CoRR abs/2302.12173, 2023.
- Gradient-based Adversarial Attacks against Text Transformers. In Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5747–5757. ACL, 2021.
- Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation. CoRR abs/2310.06987, 2023.
- Adversarial Example Generation with Syntactically Controlled Paraphrase Networks. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pages 1875–1885. ACL, 2018.
- Multi-step Jailbreaking Privacy Attacks on ChatGPT. CoRR abs/2304.05197, 2023.
- TextBugger: Generating Adversarial Text Against Real-world Applications. In Network and Distributed System Security Symposium (NDSS). Internet Society, 2019.
- Privacy in Large Language Models: Attacks, Defenses and Future Directions. CoRR abs/2310.10383, 2023.
- Holistic Evaluation of Language Models. CoRR abs/2211.09110, 2022.
- AgentBench: Evaluating LLMs as Agents. CoRR abs/2308.03688, 2023.
- AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models. CoRR abs/2310.04451, 2023.
- Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study. CoRR abs/2305.13860, 2023.
- InstrPrompt Injection Attacks and Defenses in LLM-Integrated Applications. CoRR abs/2310.12815, 2023.
- Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? In Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 11048–11064. ACL, 2022.
- A Trembling House of Cards? Mapping Adversarial Attacks against Language Agents. CoRR abs/2402.10196, 2024.
- What In-Context Learning "Learns" In-Context: Disentangling Task Recognition and Task Learning. CoRR abs/2305.09731, 2023.
- Differentially Private In-Context Learning. CoRR abs/2305.01639, 2023.
- Generative Agents: Interactive Simulacra of Human Behavior. CoRR abs/2304.03442, 2023.
- Hijacking Large Language Models via Adversarial In-Context Learning. CoRR abs/2311.09948, 2023.
- Identifying the Risks of LM Agents with an LM-Emulated Sandbox. In International Conference on Learning Representations (ICLR). ICLR, 2024.
- Do Anything Now: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. In ACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, 2024.
- When Does Machine Learning FAIL? Generalized Transferability for Evasion and Poisoning Attacks. In USENIX Security Symposium (USENIX Security), pages 1299–1316. USENIX, 2018.
- Universal Adversarial Triggers for Attacking and Analyzing NLP. In Conference on Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2153–2162. ACL, 2019.
- DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models. CoRR abs/2306.11698, 2023.
- Adversarial Demonstration Attacks on Large Language Models. CoRR abs/2305.14950, 2023.
- Defending ChatGPT against jailbreak attack via self-reminders. Nature Machine Intelligence, 2023.
- Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection. CoRR abs/2307.16888, 2023.
- Watch Out for Your Agents! Investigating Backdoor Threats to LLM-Based Agents. CoRR abs/2402.11208, 2024.
- ReAct: Synergizing Reasoning and Acting in Language Models. In International Conference on Learning Representations (ICLR). ICLR, 2023.
- GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts. CoRR abs/2309.10253, 2023.
- InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. CoRR abs/2403.02691, 2024.
- WebArena: A Realistic Web Environment for Building Autonomous Agents. CoRR abs/2307.13854, 2023.
- PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts. CoRR abs/2306.04528, 2023.
- Red teaming ChatGPT via Jailbreaking: Bias, Robustness, Reliability and Toxicity. CoRR abs/2301.12867, 2023.
- Universal and Transferable Adversarial Attacks on Aligned Language Models. CoRR abs/2307.15043, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.