- The paper introduces a dual-branch architecture that integrates channel-wise cross-modal fusion and prototype refinement to address subtle inter-class differences in micro-gesture recognition.
- It employs a PoseConv3D backbone and a novel cross-attention module that fuses RGB and skeletal features, achieving a 6.13% accuracy gain over previous benchmarks.
- The prototypical refinement module smartly calibrates ambiguous samples, reducing intra-class variation and paving the way for more robust micro-gesture classification.
Prototype-Based Multi-Modal Learning for Micro-Gesture Classification
Introduction
Micro-gestures serve as critical, involuntary cues for understanding human emotional states. Compared to classical gesture or action recognition, micro-gesture classification is highly challenging due to minimal inter-class differences, large intra-class variations, and the prevalence of ambiguous samples. The paper "Prototype Learning for Micro-gesture Classification" (2408.03097) proposes a multi-modal approach leveraging RGB and skeletal modalities, integrating a cross-attention fusion module and a prototypical refinement module. This architecture, evaluated on the iMiGUE dataset, achieves significant accuracy gains, demonstrating the effectiveness of both modality fusion and prototype-driven regularization for micro-gesture recognition.
Methodology
The model adopts a PoseConv3D backbone, with separate RGB and Pose input branches. The key technical contributions include a cross-modal fusion module operating on feature channels and a prototypical refinement module structured for enhanced category-level discrimination.
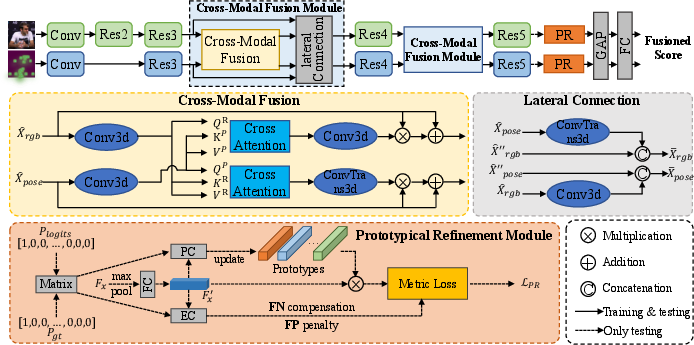
Figure 1: The dual-branch micro-gesture classification pipeline integrates cross-attention fusion of RGB and Pose features with prototypical refinement for ambiguous sample calibration.
Cross-Modal Fusion Module
Robust multimodal fusion is crucial given the subtlety of discriminative cues in micro-gestures. The proposed cross-modal fusion module performs information exchange between RGB and skeleton feature channels via cross-attention at the channel dimension, rather than the more conventional spatial dimension. Concretely, after aligning RGB and Pose features through independent 3D convolutions and spatial pooling, channel-wise cross-attention is computed. This enables the model to focus on informative, mutually-correlated patterns between modalities, while discarding channel-level redundancy and noise. This architectural choice markedly reduces computational overhead and enhances representation efficiency, a critical consideration in high-dimensional, frame-sequence settings.
Prototypical Refinement Module
To address ambiguous samples and minimize intra-class dispersion, a prototypical refinement module is utilized. Prototype vectors for each class are initialized and iteratively refined via EMA using confidently classified (true positive) samples during training. Ambiguous (FN, FP) and confident samples (TP) are mined within each mini-batch. The module computes class prototypes, clusters ambiguous samples, and introduces auxiliary loss terms incentivizing confident samples to approach FN cluster centers while repelling from FP cluster centers. This is operationalized through a loss that combines cross-entropy with prototypical refinement regularization, directly targeting the most problematic regions of inter-class overlap in the representation space.
Experimental Evaluation
The proposed method is evaluated on the iMiGUE dataset, consisting of 32 micro-gesture and 1 non-micro-gesture class, under a cross-subject protocol. The HFUT-VUT team’s solution achieves a Top-1 accuracy of 70.254% on the test set, outperforming the MiGA'23 1st place result by 6.13 percentage points. The model ensemble, utilizing both backbone branches and results from previous state-of-the-art methods, further improved accuracy, establishing a new performance benchmark in the MiGA challenge track.
The ablation shows substantial gains from each component: The cross-modal fusion module enhances the baseline by exploiting complementary modality-specific cues, while the prototypical refinement module is critical for correcting ambiguous sample misclassifications.
Practical and Theoretical Implications
This architecture demonstrates that channel-wise multimodal attention is effective for fine-grained gesture modeling, and that prototype-guided regularization efficiently mitigates the typical ambiguities in micro-gesture datasets. The results also suggest that optimal fusion of static (RGB) and geometric (skeleton) cues is essential when class boundaries are poorly defined in the raw signal domains. The modular approach is applicable to other domains facing similar intra/inter-class imbalance issues, such as subtle action detection in larger social psychology video corpora, clinical movement analysis, or affective computing.
The results highlight the limitations of single-modality processing and conventional attention paradigms for subtle human movement interpretation, and suggest that future recognition pipelines should include online calibration via sample mining and prototype modeling at both feature and decision levels.
Future Directions
Promising directions include leveraging large-scale weakly/unsupervised pre-training to mitigate annotation scarcity, as indicated in the paper. The application of video motion magnification could further amplify micro-gesture cues, enhancing recognition robustness. Cross-dataset and domain adaptation, scalable to large unlabelled corpora, remains a challenge for extended real-world utility. Moreover, integrating more expressive representations of skeletal topology (e.g., higher-order graphs, temporal transformers) could further boost the learning of transient, subtle patterns integral to micro-gesture discrimination.
Conclusion
The paper presents a technically sophisticated, empirically validated architecture for micro-gesture classification, combining cross-channel multimodal attention with prototype-driven loss modeling. The approach achieves state-of-the-art accuracy on iMiGUE and substantiates the necessity of both modality fusion and ambiguity correction in fine-grained human movement recognition tasks. These findings advance micro-gesture analysis methodology and provide a clear foundation for subsequent research in subtle action understanding and emotion analysis (2408.03097).