- The paper presents MVCL-DAF++, achieving significant performance gains on MMIR benchmarks by integrating prototype-aware contrastive alignment with dynamic attention fusion.
- It employs a Transformer-based mechanism for coarse-to-fine feature extraction that enhances semantic grounding and improves robustness against noise.
- Ablation studies highlight the complementary benefits of contrastive and prototype-based losses, with results reaching 76.18% accuracy on the MIntRec dataset.
Enhancing Multimodal Intent Recognition with MVCL-DAF++
Introduction
The paper presents MVCL-DAF++, an advanced framework aimed at improving Multimodal Intent Recognition (MMIR) through prototype-aware contrastive alignment and coarse-to-fine dynamic attention fusion. Addressing issues such as semantic grounding and robustness against noise, this framework enhances state-of-the-art performance on MMIR benchmarks like MIntRec and MIntRec2.0.
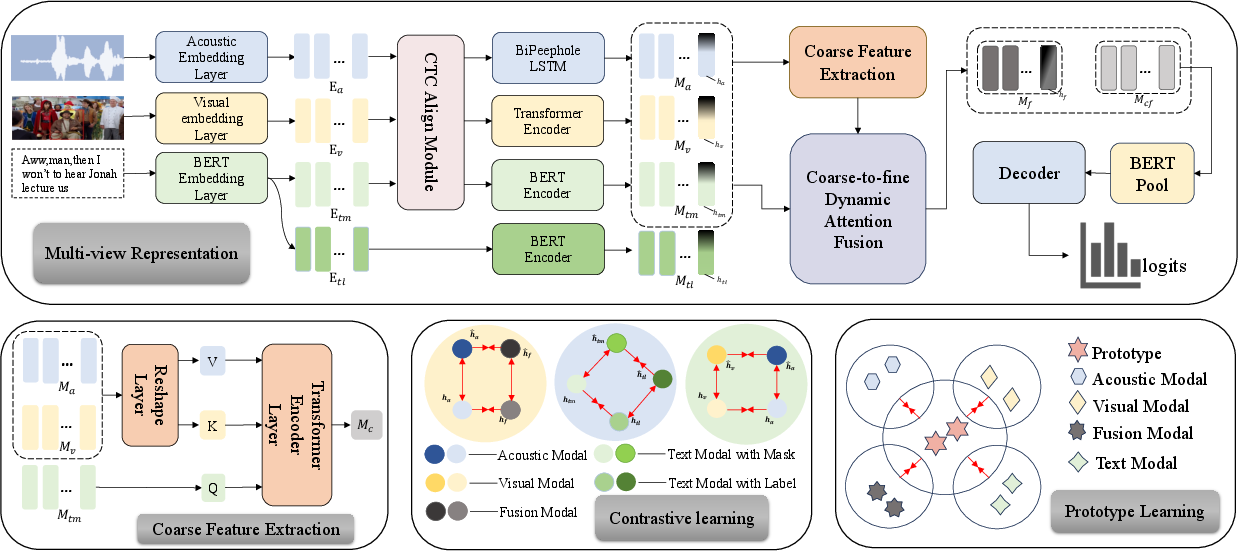
Figure 1: MVCL-DAF++ architecture with four modules: (1) Modality encoders with coarse-to-fine DAF, (2) Cross-modal coarse feature extraction, (3) Contrastive learning for representation regularization, and (4) Prototype-aware contrastive alignment.
Methodology
Model Overview
The MVCL-DAF++ framework incorporates four core components to process multimodal inputs: modality-specific encoders for initial feature extraction, a Transformer-based mechanism for coarse-to-fine fusion of features, a regularization step through contrastive learning, and a prototype-aware module for semantic grounding. This setup ensures optimal alignment and classification of input data across modalities.
Prototype-Aware Contrastive Alignment
This component introduces class-level prototypes, acting as semantic anchors within the embedding space. The framework computes these prototypes iteratively and enhances instance-to-prototype contrast, grounding learning on shared semantic structures. This approach improves the model's resistance to noise and enhances data imbalance handling.
Coarse-to-Fine Dynamic Attention Fusion
This mechanism leverages a coarse-to-fine strategy where modality-aware encodings are generated initially, followed by dynamic integration with detailed token-level features. This hierarchical method facilitates adaptive cross-modal interactions, enhancing the encoded semantic richness.
Results and Discussion
The proposed MVCL-DAF++ significantly outpaces existing baselines across key performance metrics—Accuracy, Weighted F1, Weighted Precision, and Recall—highlighting its robustness and effectiveness in diverse test conditions. For instance, on the MIntRec dataset, the model achieves a new benchmark with an accuracy of 76.18%.
Ablation Studies
An in-depth analysis reveals the critical role of prototype-aware and coarse-to-fine modules. Performance declines when either is omitted, illustrating their necessity. Moreover, integrating contrastive and prototype-based losses further enhances the model accuracy, underlining these methods' complementary nature.
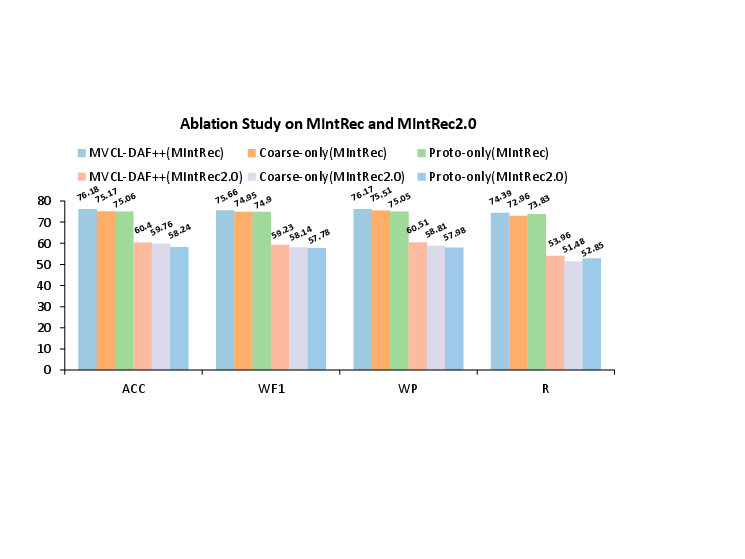
Figure 2: Ablation study on MIntRec and MIntRec2.0.
Model Analysis
Figures illustrating attention scores and embedding distributions elucidate the framework's internal processes. The dynamic attention mechanism flexibly adjusts to the data nuances, providing more weight to coarse features under noisy conditions. Additionally, t-SNE visualizations underscore the effectiveness of prototype-based alignment in clustering instances around their semantic prototypes, achieving high inter-class separability.
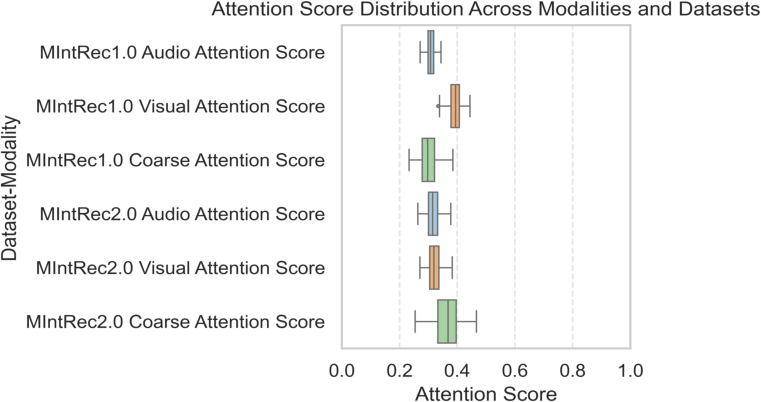
Figure 3: Distribution of attention scores across modalities and datasets.
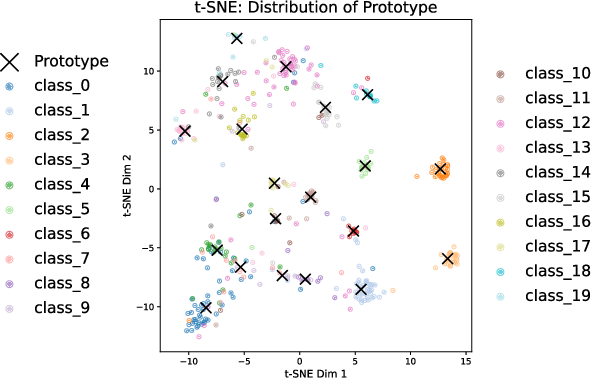
Figure 4: t-SNE visualization of learned embeddings (dots) and class prototypes (black crosses).
Conclusion
MVCL-DAF++ establishes itself as a compelling approach for MMIR, effectively integrating prototype-aware alignment with a novel attention fusion mechanism. Its superior performance metrics on established benchmarks demonstrate its potential for use in real-world applications. Future explorations could focus on adapting this architecture for few-shot learning or continual learning contexts, broadening its applicability.