- The paper introduces MultiHateClip, a multilingual dataset addressing hate speech detection on YouTube and Bilibili by integrating text, audio, and visual modalities.
- The methodology involves annotating 2,000 video clips for hatefulness, offensiveness, and normalcy, with detailed cultural context focusing on gender discrimination.
- Benchmarking reveals that multimodal models, notably GPT-4V, outperform unimodal approaches, underscoring the need for culturally tailored analysis.
MultiHateClip: A Multilingual Benchmark Dataset for Hateful Video Detection on YouTube and Bilibili
Introduction
The study introduces MultiHateClip, a comprehensive multilingual benchmark dataset aimed at enhancing hateful video detection on platforms such as YouTube and Bilibili. Given the growing influence of social media in disseminating hate speech, this dataset addresses the limitations of existing research focused mostly on text-based hate speech and the Western context. MultiHateClip underscores the necessity of exploring multimodal video content, integrating comprehensive annotations and leveraging both English and Chinese cultural contexts to tackle hate speech effectively.
The dataset constitutes 2,000 short video clips, annotated for hatefulness, offensiveness, and normalcy, along with detailed contextual information including targeted victims and contributing modalities. Through this compilation, the study offers a novel perspective in cross-cultural hate speech analysis, specifically focusing on gender-related discrimination in contrasting cultural settings.
Contemporary hate speech detection has primarily revolved around text-based analysis, though efforts such as meme detection have recently gained traction in multimodal contexts. Video-based hate speech detection remains notably underexplored, restricted by the limited availability of datasets. Previous works like Das et al.'s English dataset highlight the domain’s nascent stage, emphasizing simple binary classification without detailed contextual analysis.
The MultiHateClip dataset advances this field by offering detailed segment annotations, identifying target victims, and specifying contributing modalities. This approach not only enriches understanding but also addresses the relatively unexplored area of multimodal detection in non-Western languages.
MultiHateClip Dataset
Data Collection and Annotation
The dataset was compiled from YouTube and Bilibili, targeting gender-based hate lexicons and sourcing video clips of up to 60 seconds in length. Utilizing these hate lexicons allowed for the filtering of videos potentially featuring offensive or hateful content.
For annotation, the process involved categorizing each video as hateful, offensive, or normal, identifying segments containing negative content, and pinpointing the target victim group (e.g., Woman, Man, LGBTQ+). Furthermore, annotators were asked to specify whether the hatefulness derived from textual, audio, or visual components.
Data Statistics and Analysis
The dataset reflects stringent moderation policies on the platforms, with a considerable portion categorized as normal despite intended searches for hate-associated content. The victim group analysis signifies a pronounced focus on gender discrimination, especially targeting women. Different modalities conveyed hate speech's multifaceted nature, particularly in Chinese videos where multimodal contributions were significant.

Figure 1: Amplitude of English YouTube videos. Y-axis: Amplitude Indicator, X-axis: Time(sec.).

Figure 2: Zero Crossing Rate of English YouTube videos. Y-axis: Zero Crossing Indicator, X-axis: Time(sec.).
The text analysis using tf-idf scores revealed prevalent hate lexicons in offensive videos, whereas implicit hatefulness was harder to detect through sole textual analysis. Audio and vision analysis highlighted congruent patterns, with offensive videos generally exhibiting higher sound intensities and a distinct visual profile.
Benchmarking Models
Problem Definition and Models
The dataset posed a challenge in distinguishing between hateful, offensive, and normal categories across modalities. Models evaluated include text-based (mBERT, GPT-4, Qwen), audio-based (MFCC, Wav2Vec), vision-based (ViViT, ViT), and multimodal models (VLM, GPT-4V, Qwen-VL).
The multimodal model combining text, audio, and vision features demonstrated enhanced efficacy compared to unimodal approaches, emphasizing the importance of modality integration for comprehensive hate speech detection.
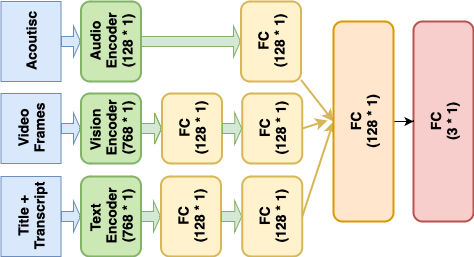
Figure 3: Framework of the multi-modal model. FC: Fully Connected Layer.
Experimentation and Results
The experiments underscored the effectiveness of GPT-4V and the multimodal models for English data, while V1 and M1 excelled in the Chinese dataset. The results highlighted the need for tailored training on non-Western data to overcome cultural bias. Error analysis revealed the benefits of multimodal approaches, as they could recognize instances of implicit hatefulness to a greater extent.
GPT-4V's expansive training data enabled superior content understanding, a strength not paralleled by other models, which struggled with nuanced and implicit hate speech detection.
Conclusion
MultiHateClip advances the field by addressing the previously unmet needs of multimodal hateful video detection in non-Western languages. This dataset and accompanying benchmarks advocate for integrated multimodal approaches, pushing for adaptations in model training to better handle cultural nuances. As such, MultiHateClip stands as a foundational resource poised to guide future research in detecting and understanding hate speech across diverse, multilingual contexts.