OpenScan: A Benchmark for Generalized Open-Vocabulary 3D Scene Understanding
Abstract: Open-vocabulary 3D scene understanding (OV-3D) aims to localize and classify novel objects beyond the closed set of object classes. However, existing approaches and benchmarks primarily focus on the open vocabulary problem within the context of object classes, which is insufficient in providing a holistic evaluation to what extent a model understands the 3D scene. In this paper, we introduce a more challenging task called Generalized Open-Vocabulary 3D Scene Understanding (GOV-3D) to explore the open vocabulary problem beyond object classes. It encompasses an open and diverse set of generalized knowledge, expressed as linguistic queries of fine-grained and object-specific attributes. To this end, we contribute a new benchmark named \textit{OpenScan}, which consists of 3D object attributes across eight representative linguistic aspects, including affordance, property, and material. We further evaluate state-of-the-art OV-3D methods on our OpenScan benchmark and discover that these methods struggle to comprehend the abstract vocabularies of the GOV-3D task, a challenge that cannot be addressed simply by scaling up object classes during training. We highlight the limitations of existing methodologies and explore promising directions to overcome the identified shortcomings.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Imagine a robot looking around a room made of 3D dots (a “point cloud”), like in a video game world. Many AI systems can find “a chair” or “a table” if you give them those exact words. But real people also talk about things in other ways, like “something you sit on” or “a bottle made of plastic.” This paper introduces a new way to test AI so it can understand both object names and richer descriptions about objects.
The authors build a new test set, called OpenScan, and a harder task, called Generalized Open‑Vocabulary 3D Scene Understanding (GOV‑3D). This task asks AI to find 3D objects not just by their names, but also by attributes like what they’re used for, what they’re made of, or how they’re described in everyday language.
The main goals and questions
The paper asks:
- Can today’s AI models find objects in 3D scenes when we describe them using everyday attributes instead of just names?
- How well do these models handle different kinds of attributes (like “made of wood,” “used for sleeping,” or “also called a bedside table”)?
- What helps these models do better: training on more object names, or writing clearer queries that include relationships (like “this thing is made of wood”)?
How they approached it (with easy explanations)
To test AI fairly, they needed a benchmark (a big, well-labeled dataset + rules for evaluation). They built OpenScan on top of an existing 3D dataset (ScanNet200), which already had 3D scans of indoor scenes and object labels (e.g., bed, fridge).
What they added:
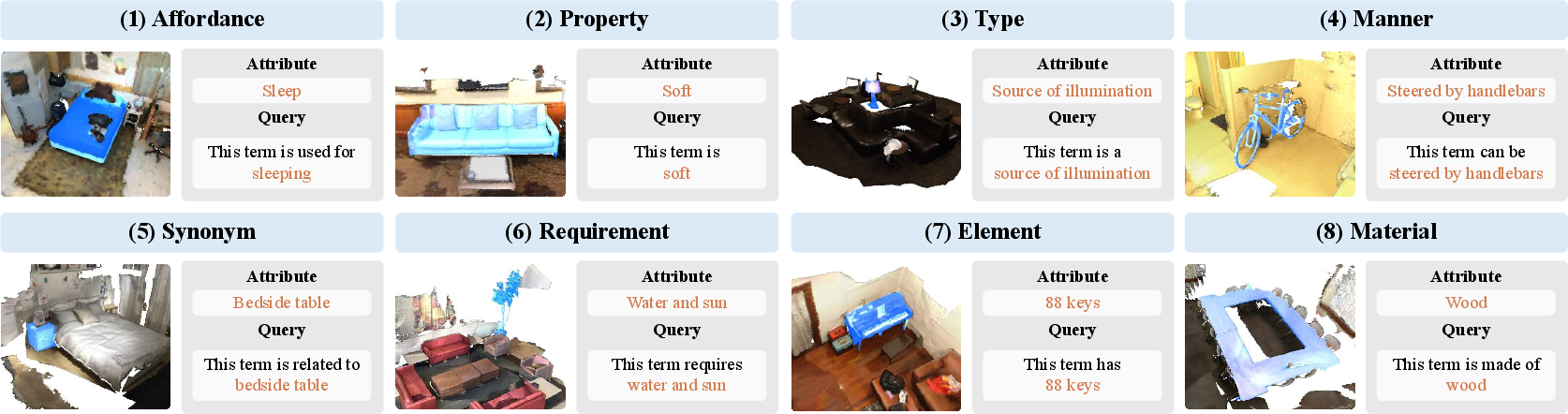
- Extra attribute labels for objects across eight language-based aspects. You can think of these as different ways we talk about objects:
- Affordance (what it’s used for): “sit” (for chair)
- Property (what it’s like): “soft” (for pillow)
- Type (what group it belongs to): “communication device” (for telephone)
- Manner (how it’s used/worn): “worn on the head” (for hat)
- Synonym (another word for it): “bedside table” (for nightstand)
- Requirement (what it needs): “balance to ride” (for bicycle)
- Element (its parts): “two wheels” (for bicycle)
- Material (what it’s made of): “plastic” (for bottle)
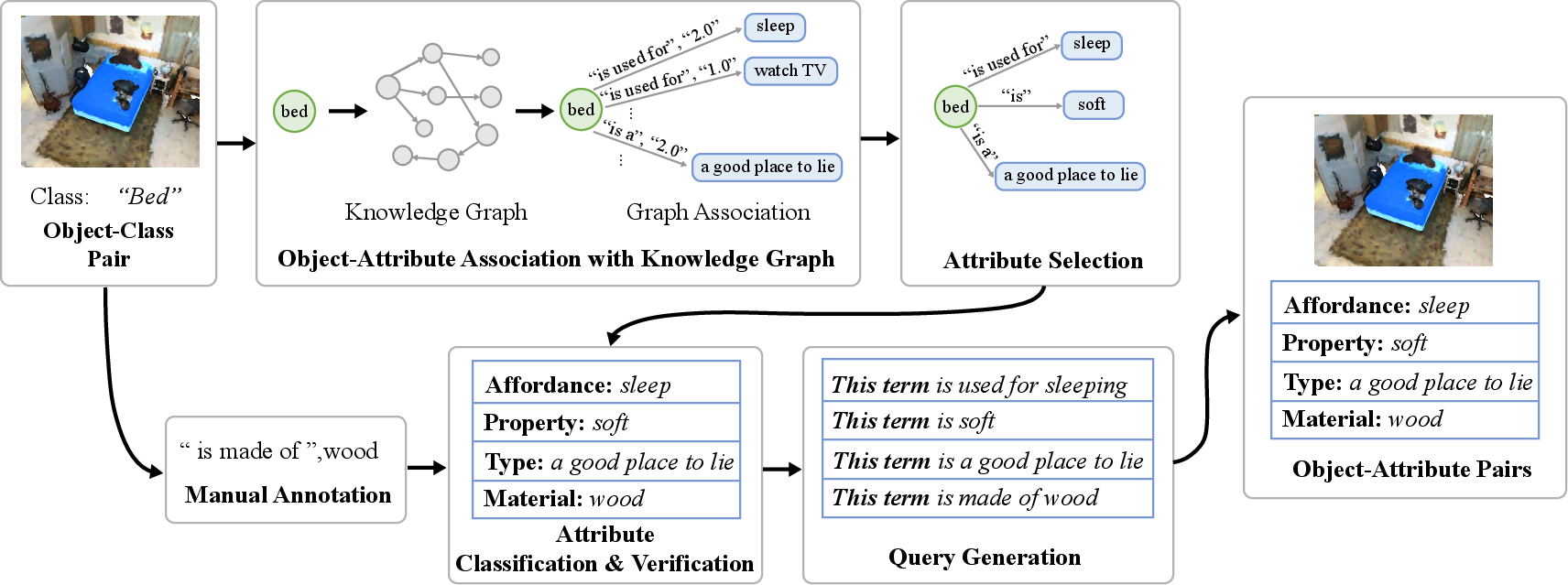
How they got these attributes:
- They used a knowledge graph (ConceptNet), which is like a giant dictionary of facts that connects words and ideas (e.g., “bed — is used for — sleep”).
- They also had people add visual-only attributes when needed (like material), because some things you can only tell by looking.
- They cleaned and grouped these attributes into the eight aspects above, made sure they were consistent, and removed duplicates.
How they asked questions to the AI:
- Instead of giving away the object name, they wrote queries like “this thing is used for sleeping,” or “this thing is made of wood.” That way, the AI has to match the attribute to the right 3D object.
How they tested models:
- They took several state-of-the-art 3D models that already work with text (often powered by image-text models like CLIP).
- They evaluated them in a “zero-shot” way (no extra training on OpenScan), asking them to find objects by attributes across many scenes.
- They compared performance on classic “object name” tests vs. the new “attribute” tests.
What they found and why it matters
Main findings:
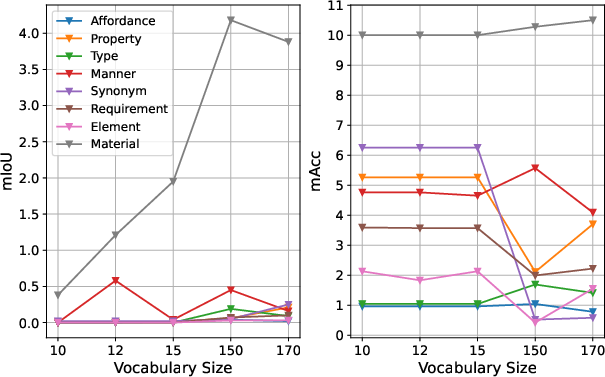
- Today’s best models are good at finding objects when you use their names (“chair,” “fridge”), but their performance drops a lot when you use attributes instead (“something you sit on,” “keeps food cold”).
- Models do a bit better on:
- Synonyms (because they’re very close to object names).
- Material (e.g., “wood,” “plastic”), likely because visual patterns like texture and color are easier to pick up from images.
- Models struggle more with:
- Affordance (what it’s used for) and
- Property (characteristics like “soft”), which are more abstract and need commonsense understanding.
- Simply training on more object names doesn’t fix this. Adding more categories (like going from 150 to 200 object labels) doesn’t significantly improve attribute understanding.
- Writing clearer queries helps. Using a template like “this thing is made of wood” works better than just “wood,” because it gives helpful context.
Why this matters:
- In real-life settings—like home robots, AR devices, or self-driving systems—people won’t always use exact object names. They’ll describe what things do or what they’re like. For AI to be truly helpful, it needs to understand those natural descriptions.
- The big gap in performance shows that current models are missing important commonsense knowledge and deeper language understanding about objects.
What this means for the future
- OpenScan gives the community a large, carefully built benchmark to push AI from recognizing object names to understanding richer, everyday descriptions.
- The results suggest new research directions:
- Teach models more attribute and commonsense knowledge (not just more object names).
- Improve the way language is connected to 3D vision, especially for abstract attributes.
- Use better query designs and training methods that focus on relationships (e.g., “is used for,” “is made of”) rather than just labels.
In short, this work raises the bar: it encourages building AI that not only knows “what a thing is called” but also “what it does,” “what it’s like,” and “what it’s made of”—much closer to how people think and talk.
Collections
Sign up for free to add this paper to one or more collections.