OpenVoxel: Training-Free Grouping and Captioning Voxels for Open-Vocabulary 3D Scene Understanding
Abstract: We propose OpenVoxel, a training-free algorithm for grouping and captioning sparse voxels for the open-vocabulary 3D scene understanding tasks. Given the sparse voxel rasterization (SVR) model obtained from multi-view images of a 3D scene, our OpenVoxel is able to produce meaningful groups that describe different objects in the scene. Also, by leveraging powerful Vision LLMs (VLMs) and Multi-modal LLMs (MLLMs), our OpenVoxel successfully build an informative scene map by captioning each group, enabling further 3D scene understanding tasks such as open-vocabulary segmentation (OVS) or referring expression segmentation (RES). Unlike previous methods, our method is training-free and does not introduce embeddings from a CLIP/BERT text encoder. Instead, we directly proceed with text-to-text search using MLLMs. Through extensive experiments, our method demonstrates superior performance compared to recent studies, particularly in complex referring expression segmentation (RES) tasks. The code will be open.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in plain words)
This paper introduces OpenVoxel, a fast, training-free way to understand 3D scenes. Imagine you take lots of photos of a room and build a 3D model from them. OpenVoxel can then find the different objects in that 3D model (like a chair, a cup, or a toy) and write short, clear descriptions for each one. After that, if you ask a question like “the small green apple on the table,” it can quickly point to the right object in the 3D scene.
What the researchers wanted to achieve
They focused on two common tasks:
- Open-vocabulary segmentation (OVS): find objects in 3D using any word someone might use (not just a fixed list like “chair,” “table”).
- Referring expression segmentation (RES): find an object using a full sentence, like “the shiny metal cup next to the water bottle.”
Their goals were:
- Group tiny 3D elements (voxels—think 3D pixels or Lego bricks) into object-level chunks without doing extra training.
- Give each object a simple, consistent caption (e.g., “apple, green, round, on table”) so it’s easy to search later.
- Answer a user’s text query by matching it directly to those captions, instead of using complicated learned “embeddings.”
How OpenVoxel works (with simple analogies)
Think of a 3D scene as a big box made of lots of tiny cubes (voxels). OpenVoxel runs in three steps:
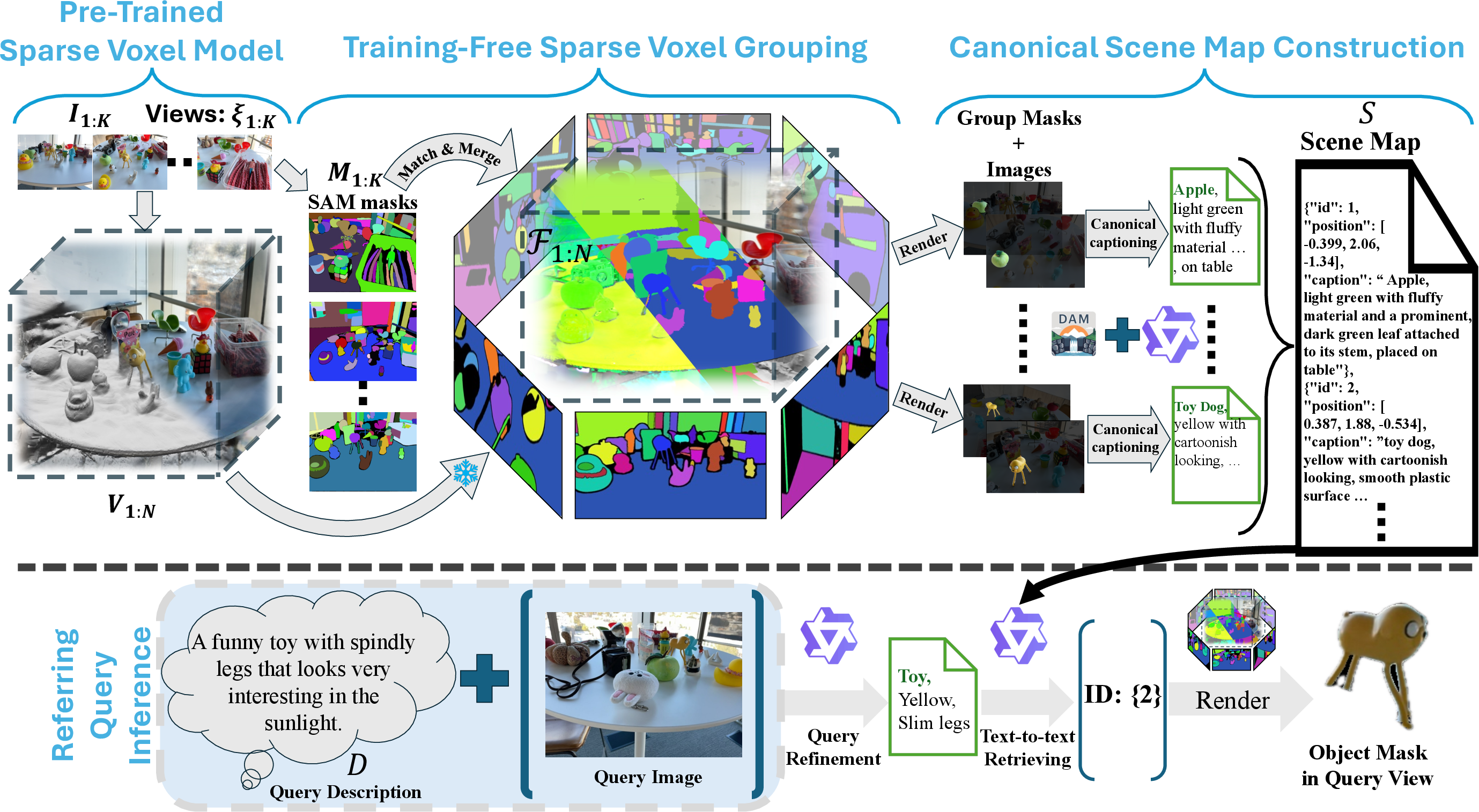
1) Grouping voxels into objects (no training needed)
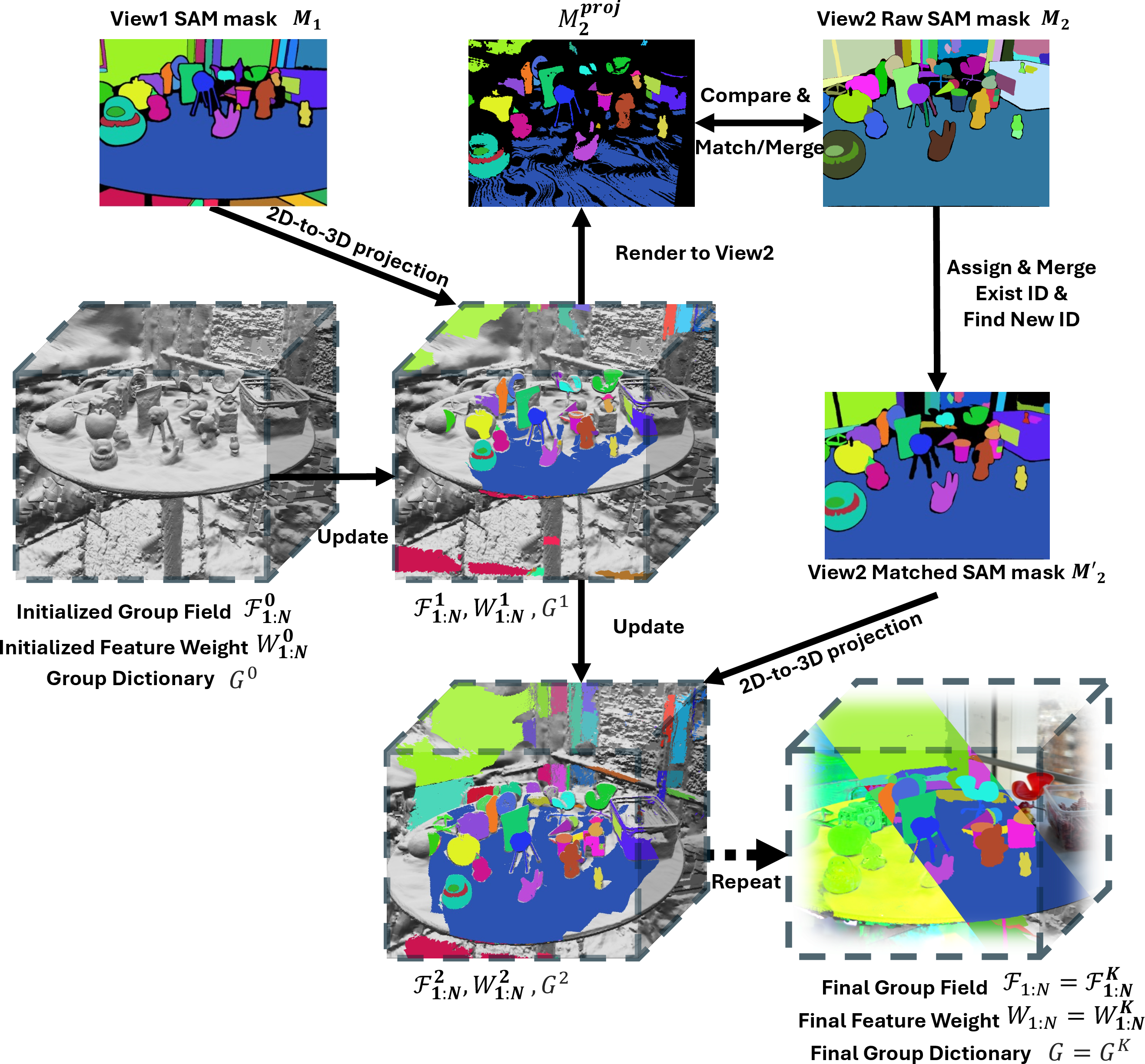
- The system starts with a 3D model built from many photos (called Sparse Voxel Rasterization, or SVR—basically a fast 3D scene made of those tiny cubes).
- For each photo, a strong 2D tool (SAM2) finds object-shaped areas (like a mask around a cup).
- OpenVoxel “lifts” those 2D masks into the 3D world: if many pixels point to the same region in 3D, it groups those voxels together as one object.
- It repeats this across views, matching and merging masks so the same object is grouped consistently from different angles.
- Analogy: You look at a toy from different sides and keep marking the same toy. By combining all your markings, you end up with a clean 3D group for that toy.
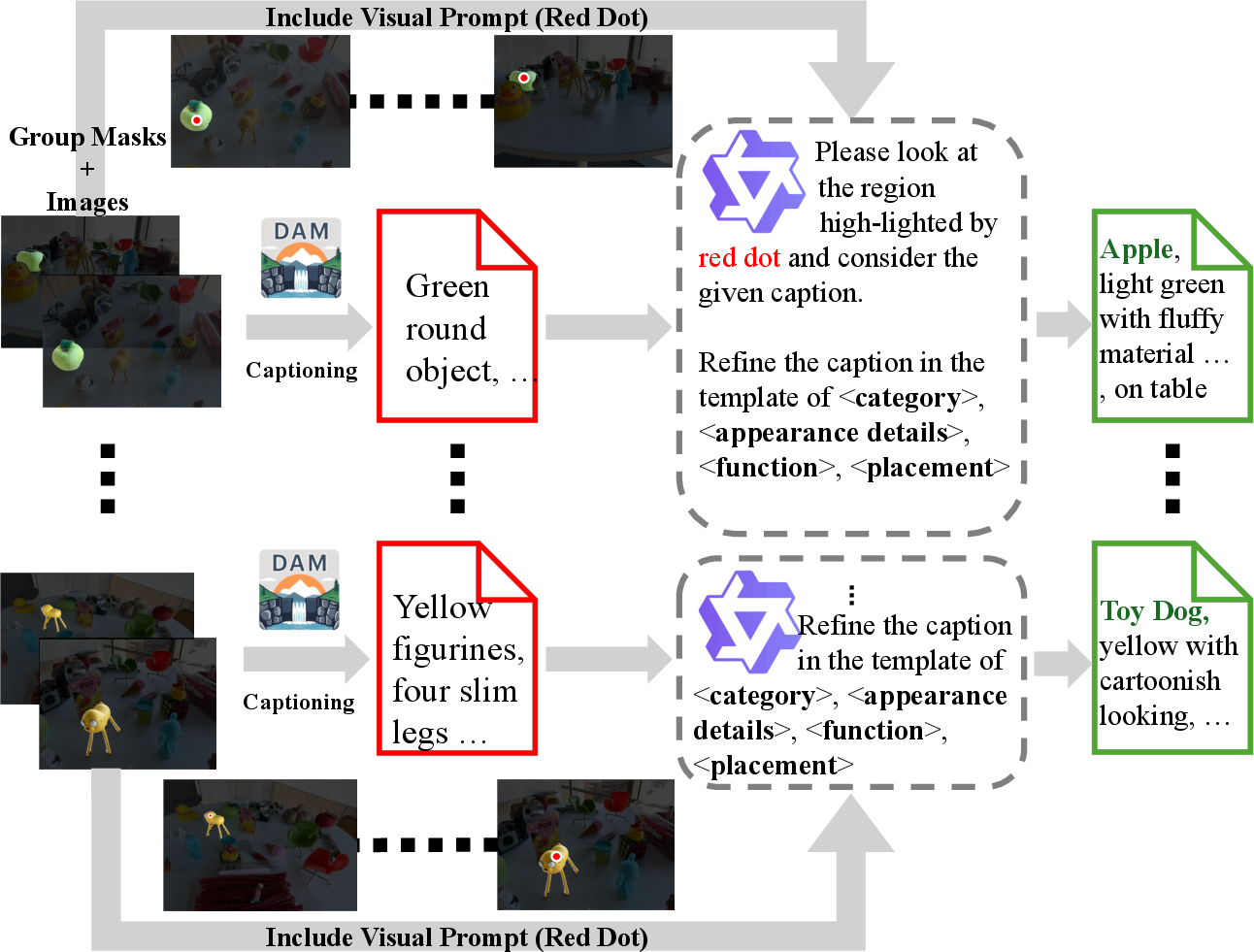
2) Captioning each object and making a scene map
- For every object group, OpenVoxel shows the masked object to a vision-LLM (like a smart captioner) to describe it (e.g., “a small green apple”).
- Then a multimodal LLM (MLLM) rewrites that description into a fixed, simple format. Example template:
- <category noun>, <appearance details>, <function or part-of>, <placement/relation>
- For instance: “apple, green, shiny surface, on table”
- The system stores each object’s ID, 3D position, and caption in a “scene map,” like a tidy catalog for the whole scene.
- Analogy: You’re making a museum map: each exhibit gets a dot on the map and a clear label.
3) Answering natural-language queries
- When someone asks “the cup with a logo near the bottle,” OpenVoxel first rewrites the question into a short, consistent phrase (e.g., “cup, logo, near bottle”).
- It then compares the refined query directly to the stored captions and picks the best match.
- Finally, it renders the mask of that object in the requested view.
- Analogy: A librarian matches your question to book labels instead of guessing from memory—fast and reliable.
What they found and why it’s important
Here are the main takeaways from their experiments:
- Strong accuracy on complex queries: On a tough benchmark for sentence-based 3D object finding (RES), OpenVoxel outperformed previous methods by a notable margin. It handled long, descriptive questions better because it compares text-to-text (your question to a clean caption), instead of relying on trained, fixed-language spaces.
- Competitive on simpler tasks: On open-vocabulary tasks (short word queries like “chair”), it performed as well as or better than other systems.
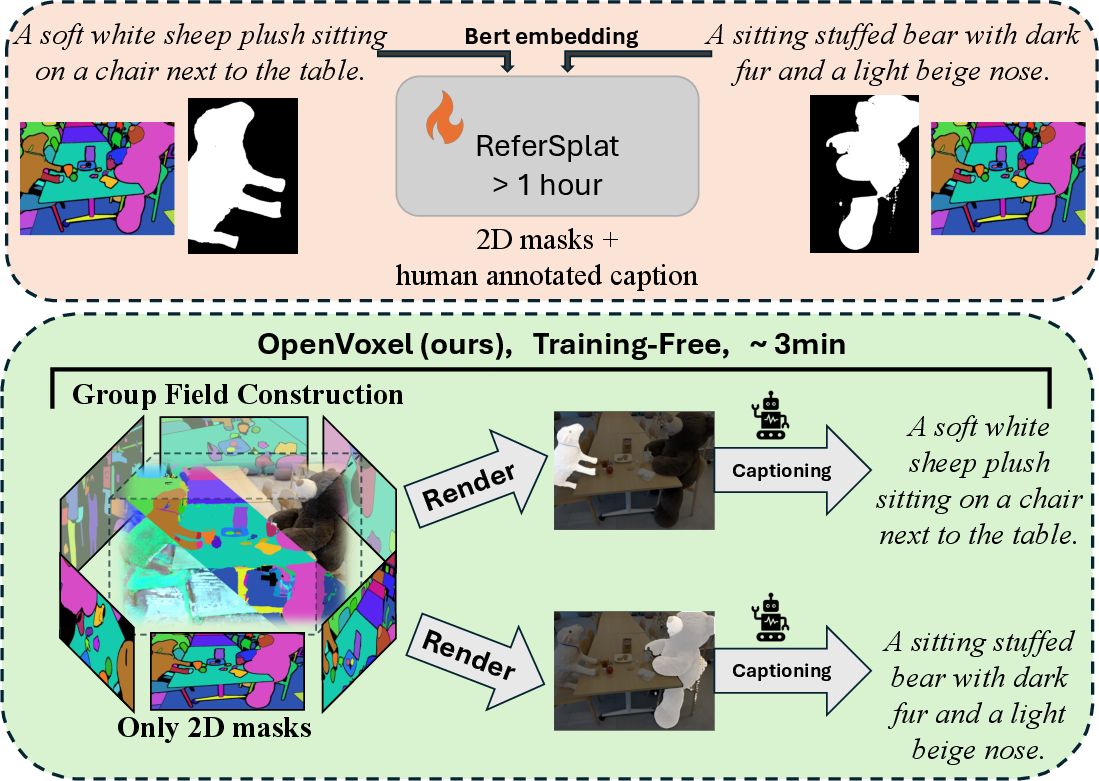
- Much faster and training-free: It builds the scene map in minutes (around 3 minutes on their hardware), whereas some prior methods need tens of minutes to over an hour per scene to train extra language features.
- Less manual effort: It doesn’t need extra training data like “image + sentence + object mask” pairs, which are expensive and time-consuming to create.
Why this matters:
- It makes 3D understanding more practical: faster setup, no special training per scene, and it handles flexible, human-like descriptions well.
- It’s transparent: because it uses readable captions, you can see exactly why an object was chosen.
What this could lead to (future impact)
OpenVoxel’s approach—grouping 3D data into objects, captioning them clearly, and matching queries by text—can help:
- Augmented reality and robotics: a robot or AR app can find “the red mug on the counter” without needing retraining.
- 3D editing and games: creators can select and edit objects by saying, “the tall plant near the window.”
- Education and virtual tours: users can ask natural questions like “the statue with a gold pattern” and get precise answers.
Overall, OpenVoxel shows a simple but powerful idea: turn 3D scenes into labeled, human-readable maps, then use smart language tools to connect people’s words to the right 3D objects—quickly and without extra training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open problems that remain unresolved and could guide follow-up research:
- Scene diversity and generalization
- Validated primarily on LeRF subsets (small, indoor, static iPhone-Polycam scenes); no evidence of robustness to large-scale indoor environments, outdoor scenes, complex clutter, low light, or sensor/domain shifts.
- No evaluation on dynamic scenes or moving objects; the method assumes static geometry and consistent instance identity across time.
- 3D representation dependence and portability
- All results are on SVR; it is unclear how well the grouping and scene-map pipeline transfers to other 3D primitives (3DGS, NeRF, point clouds) without re-engineering renderer-specific updates or weights.
- Sensitivity to SVR reconstruction quality (pose errors, depth inaccuracies, sparse coverage) is not quantified.
- Dependence on 2D segmentation (SAM2) and error propagation
- No robustness analysis to SAM2 failures (over-/under-segmentation, occlusions, thin/transparent/specular objects, heavy clutter).
- Heuristic mask matching/merging (IoU matching, 90% overlap rule, periodic re-prompting frequency of 1–5 steps) lacks systematic hyperparameter study or failure-case analysis.
- No ablation on alternative 2D segmentation sources or uncertainty-aware fusion; mis-segmentations across views may cause persistent group drift.
- Grouping correctness and 3D consistency
- The voting scheme uses nearest centroid assignment in a 3D feature space; potential failure on adjacent/stacked instances with close centers, part-whole ambiguity, and touching objects is not analyzed.
- Handling of articulated objects, deformable parts, or multi-part instances (when to merge vs. keep separate) is not formally specified or evaluated.
- Lack of explicit 3D consistency constraints beyond centroid voting; no global optimization or graph-based consistency to reconcile multi-view conflicts.
- Canonical scene map design
- Scene map stores only instance ID, center, and a canonical caption; there is no use of full 3D geometry/extent, uncertainty, or visibility priors, which limits reliable spatial reasoning and spatial disambiguation.
- Spatial relations are implicitly judged from centers; the reference frame for “left of,” “behind,” etc. is under-specified (camera vs. world frame), risking inconsistent interpretation.
- MLLM dependence and reproducibility
- Captioning and retrieval rely on specific models (DAM for caption proposals, Qwen3-VL-8B for canonicalization/retrieval); no evaluation across multiple VLM/MLLM backbones to quantify sensitivity to model choice.
- No study of prompt sensitivity, temperature/determinism settings, or inter-run variability; reproducibility of MLLM-driven decisions is not guaranteed.
- The system relies on English prompts; multilingual capability and cross-lingual retrieval are unexplored.
- Caption quality and hallucination control
- No direct evaluation of caption correctness (e.g., human ratings, factuality scores, OCR accuracy for printed text rules), leaving the impact of hallucinations and mislabeling unquantified.
- The canonical template may oversimplify or drop critical relational/functional cues; trade-offs between brevity and discriminativeness are not measured.
- Query handling and reasoning limits
- Complex relational/logic queries (e.g., “the only cup not on the table,” multi-hop relations, negation, counting, compositional conjunctions) are not evaluated.
- Multi-object queries and unions/sets (returning multiple IDs) are mentioned but not systematically tested or benchmarked.
- How the optional query image is incorporated into retrieval is under-specified; there is no ablation on text-only vs. text+image queries.
- Scalability and efficiency
- Passing the entire scene map to an MLLM at inference scales linearly with the number of instances; memory/token limits, latency, and cost for large scenes are not characterized.
- Grouping runtime is reported for ≤150 views; scaling behavior for longer trajectories, higher-resolution inputs, and thousands of instances remains unknown.
- Evaluation breadth and fairness
- Benchmarks focus on mIoU/BIoU; there is no diagnostic breakdown by object size, occlusion level, texture/reflectance properties, or part vs. whole segmentation.
- Some methods compared require training while OpenVoxel does not; the impact of differing supervision regimes on fairness of comparison is not discussed.
- The weakest category (e.g., kitchen in RES) is not analyzed to identify systematic failure modes.
- Robustness to sensor and photometric effects
- No experiments on severe lighting changes, motion blur, noise, HDR ranges, or device variability; robustness boundaries are unknown.
- Transparent/reflective materials and glass objects (where depth/segmentation are challenging) are not separately evaluated.
- Uncertainty estimation and confidence calibration
- No mechanism to estimate or propagate uncertainty from grouping, captioning, and retrieval; the system cannot defer or abstain on low-confidence cases.
- Lack of confidence-aware ranking or alternative hypotheses for ambiguous queries.
- Incremental updates and interactivity
- The pipeline does not support interactive correction, incremental scene-map updates, or online refinement when new views/queries arrive.
- No strategy for identity maintenance under scene edits or for updating captions/groups after user feedback.
- Hyperparameters and engineering heuristics
- Key design choices (e.g., number of frames per group for captioning set to 8, merging frequency, IoU thresholds) are not systematically tuned; their impact on accuracy vs. speed is not quantified.
- Privacy, licensing, and deployment constraints
- The paper assumes availability of DAM and Qwen3-VL-8B; licensing, on-device feasibility, and privacy constraints for real deployments are not addressed.
- There is no discussion of smaller/faster alternatives or distillation strategies for edge deployment.
- Releasing resources
- “The code will be open” is stated, but models, prompts, and exact inference settings (seeds, decoding parameters, prompt variants) are not yet released; this impedes replication and comparative assessment.
- Extending beyond captions for retrieval
- Retrieval is caption-only; no exploration of hybrid text–visual retrieval that conditions on image crops or visual exemplars to disambiguate near-identical captions.
- No consideration of integrating geometric cues (e.g., oriented bounding boxes, surfaces) or learned 3D descriptors to complement text-to-text matching.
- Failure modes and safety
- No systematic analysis of adversarial or misleading queries, out-of-scope requests, or safety guardrails for MLLM outputs (e.g., inappropriate or biased labels).
These issues suggest concrete research directions: robustness to 2D mask errors, scalable and uncertainty-aware scene maps, richer 3D spatial reasoning, broader benchmarks, multilingual and multi-backbone MLLM evaluations, interactive correction and incremental updates, and hybrid text+visual retrieval schemes.
Practical Applications
Immediate Applications
These applications can be deployed now using the paper’s training-free pipeline (SVR + SAM2 + DAM + MLLM), assuming static scenes reconstructed from multi-view images with known poses.
- Robotics: offline task setup for manipulation and inspection in labs and light industry Sector: robotics, manufacturing Use case: pre-scan a workstation and issue open-vocabulary commands like “pick the blue cup next to the kettle” using the scene map and text-to-text retrieval; export group IDs/masks to motion planners. Tools/workflows: ROS/OpenVoxel Bridge; canonical Scene Map to grasp planners; mask-to-pose conversion. Assumptions/dependencies: static environment; accurate camera-to-robot calibration; SAM2 segmentation quality; MLLM reliability for query canonicalization; GPU for grouping (≤3 min) and <1 s inference.
- AR/VR “scene search” for consumers Sector: software, mobile AR Use case: scan a room and ask “highlight scissors used for cutting paper” or “show the green mug on the table,” overlaying masks in AR. Tools/workflows: OpenVoxel Scene Map plug-in for Polycam/ARKit/ARCore; mobile client to query and render masks. Assumptions/dependencies: sufficient multi-view capture; static scenes; on-device or cloud MLLM; user privacy handling of 3D scans.
- 3D content creation and editing Sector: media/entertainment, software Use case: in Blender/Unity, select objects by natural language (“select the cracked window pane; inpaint it”) for editing, relighting, or removal. Tools/workflows: DCC plug-in for OpenVoxel Scene Map; mask export to 3D editors; canonical caption index per asset. Assumptions/dependencies: integration with existing 3D editors; SVR/3DGS asset compatibility; DAM/MLLM licenses.
- Retail/e-commerce visual merchandising Sector: retail Use case: scan showrooms, auto-caption and index products (“red ceramic mug, on shelf”) for queryable catalogs and planograms. Tools/workflows: Showroom Inventory Annotator; caption-driven SKU search; mask-based shelf analytics. Assumptions/dependencies: controlled lighting; static layouts; need for human QC to avoid mislabeling; privacy/compliance for store scans.
- Facility and office inventory Sector: enterprise operations Use case: create searchable semantic maps of equipment (“label printer, black, on desk”) for IT audits or maintenance. Tools/workflows: Scene Map indexer for facilities; open-vocab search portal to locate assets. Assumptions/dependencies: periodic rescans; access control for 3D data; caption accuracy for fine-grained models.
- Insurance claims triage (desk assessment) Sector: finance/insurance Use case: segment and caption damaged items from 3D scans; query “find water-damaged drywall” or “cracked tile.” Tools/workflows: Adjuster Assist; mask export for documentation; side-by-side captions and image evidence. Assumptions/dependencies: static post-event scans; human oversight to reduce false positives; regulated data retention.
- Accessibility assistants for home and school Sector: education, consumer health Use case: “find the spoon on the table,” “where is the trash bin?” with mask overlays on wearable or phone feeds from pre-scanned spaces. Tools/workflows: Accessibility AR Finder; canonical captions for concise guidance; speech-to-query interface. Assumptions/dependencies: pre-scan workflows; safety disclaimers; potential confusion in cluttered scenes.
- Rapid dataset annotation for academia Sector: academia Use case: auto-generate instance masks and canonical captions for 3D OVS/RES datasets to cut labeling time. Tools/workflows: Training-free Labeler; export to COCO/NERF/3DGS formats; quality-control scripts. Assumptions/dependencies: static scenes; post hoc human curation; transparency on MLLM prompt choices for reproducibility.
- Compliance snapshots in offices and labs Sector: policy/compliance, enterprise safety Use case: highlight “protective eyewear,” “chemical containers,” “trip hazards” in pre-scanned labs/offices for checklists. Tools/workflows: Compliance Snapshot Generator; caption-driven audit queries; report generation. Assumptions/dependencies: category coverage by VLM/MLLM; potential false negatives; need for sign-off by safety officers.
Long-Term Applications
These rely on further research and engineering (real-time, dynamic scenes, scaling, stronger spatial reasoning, and edge/on-device MLLMs), but are natural extensions of the paper’s methods and innovations.
- Real-time open-vocabulary perception for household and industrial robots Sector: robotics Use case: live RES/OVS during manipulation (“grab the clean spoon near the sink”) without offline scans. Tools/workflows: streaming SVR/3DGS + fast segmentation + incremental group field updates; on-device or low-latency MLLMs. Assumptions/dependencies: dynamic-scene handling, robust SLAM integration, temporal consistency, safety certification.
- Warehouse/factory “semantic digital twins” Sector: manufacturing, logistics Use case: continuously maintain a queryable twin (“box of screws, aisle 3, second shelf”) for inventory and audits. Tools/workflows: Warehouse Semantic Twin Builder; automated re-grouping as layouts change; caption-history and versioning. Assumptions/dependencies: scalability to large spaces; distributed capture; privacy/role-based access; persistent identity tracking.
- AEC/BIM semantic augmentation Sector: construction/architecture Use case: auto-populate BIM with “door handles, exit signs, fire extinguishers” and affordances; compliance check with code references. Tools/workflows: BIM Semantic Annotator; caption-to-BIM element mapping; georeferenced group centers. Assumptions/dependencies: alignment between scans and BIM coordinates; regulatory accuracy; expert validation.
- Hospital robotics and asset management Sector: healthcare Use case: “find sterile gauze” or “locate infusion pumps” across wards; assist robots and staff. Tools/workflows: Clinical Asset Finder; policy-aware caption filters; HL7/FHIR integration for device registries. Assumptions/dependencies: stringent privacy/security; FDA/CE pathways for robotic use; robust disambiguation in busy environments.
- Smart home assistants with semantic memory Sector: consumer IoT Use case: ongoing open-vocab index of belongings (“kids’ blue backpack by the door”) and guided retrieval. Tools/workflows: Semantic Home Index; periodic lightweight scans; voice queries mapped to canonical captions. Assumptions/dependencies: battery, privacy/local processing, continual updates handling clutter and occlusions.
- AR mobility assistance for visually impaired (live) Sector: health, accessibility Use case: wearable device answers “where is the exit?” or “avoid spilled liquid,” combining captions with spatial relations. Tools/workflows: low-latency AR assistant; relation-aware reasoning; auditory/haptic feedback channels. Assumptions/dependencies: robust dynamic detection; ethics and liability; edge inference; comprehensive hazard categories.
- Enterprise compliance monitoring and policy enforcement in 3D workflows Sector: policy/compliance Use case: company-wide scans verifying signage, PPE zones, and equipment placement; generate audit trails. Tools/workflows: Policy Engine over Scene Maps; canonical captions linked to compliance rules; dashboards for audits. Assumptions/dependencies: clear policy ontologies; continual retraining or prompt curation as rules evolve; governance of 3D data.
- Content moderation of user-generated 3D spaces Sector: software/platform governance Use case: detect prohibited items or sensitive content in shared AR/VR rooms using open-vocab queries. Tools/workflows: Moderation API for 3D; escalation and human review pipelines; explainable caption evidence. Assumptions/dependencies: false positive/negative management; transparency; on-device moderation for privacy.
- Energy and industrial asset audits Sector: energy, utilities Use case: semantic scans of substations/plant rooms to locate valves, gauges, and safety signage; open-vocab incident reports. Tools/workflows: Asset Audit Assistant; integration with CMMS; caption-to-part catalogs. Assumptions/dependencies: harsh environments; specialized vocabularies; cross-domain fine-tuning or domain prompts.
- Standardized “Scene Map” APIs and ecosystems Sector: software Use case: interoperable APIs for 3D grouping, captions, centers, and retrieval; plug-ins for SLAM, editors, and robots. Tools/workflows: OpenVoxel Scene Map API; schema for canonical captions; SDKs for Unity/ROS/Blender. Assumptions/dependencies: community adoption; standards bodies; versioning and provenance.
Cross-cutting assumptions and dependencies
These factors affect feasibility across many applications:
- Static vs dynamic scenes: the current pipeline assumes static scenes reconstructed via SVR; dynamic handling requires streaming updates and temporal consistency.
- Capture quality and camera poses: multi-view coverage and pose accuracy strongly influence grouping and captions.
- Foundation models: performance depends on SAM2 (segmentation), DAM (captioning), and MLLM (canonicalization and retrieval); domain-specific prompts or models may be necessary.
- Hardware: GPU acceleration (e.g., RTX-class) improves grouping time; on-device/in-the-loop use requires efficient models or edge accelerators.
- Privacy, security, and governance: storage and processing of 3D scans and captions must comply with sector-specific regulations (HIPAA, GDPR, corporate policies).
- Human-in-the-loop: high-stakes use cases (healthcare, compliance, insurance) should include expert review to mitigate errors and hallucinations.
- Robust spatial reasoning: complex relations (e.g., left/right under view changes) require consistent canonicalization and possibly enhanced geometric reasoning beyond group centers.
Glossary
- Affordance: A functional attribute describing what an object can be used for or how it can be interacted with. "function/affordance or part-of"
- Anisotropic Gaussians: Direction-dependent Gaussian representations used to model 3D scenes efficiently for rendering. "represent scenes using anisotropic Gaussians that can be rendered in real time"
- BERT: A transformer-based text encoder used to produce language embeddings; referenced as a baseline the method avoids. "does not introduce embeddings from a CLIP/BERT text encoder."
- Boundary IoU (BIoU): An evaluation metric measuring overlap quality specifically along object boundaries between predicted and ground-truth masks. "Note that BIoU indicates the boundary IoU of predicted mask and ground-truth mask."
- Canonical Captioning: Standardizing free-form object descriptions into a fixed, structured template for consistent retrieval. "Detail of the Canonical Captioning."
- Canonical Scene Map: A structured record of object groups in a scene, storing their 3D positions and standardized captions. "Canonical Scene Map Construction"
- Centroid (Instance Centroid): The 3D center point representing an object instance, used to cluster voxels belonging to the same object. "which denotes the instance centroid the voxels belonging to"
- CLIP: A vision-LLM producing aligned image-text embeddings; often used to distill semantic features into 3D representations. "distilling CLIP embeddings and multi-scale SAM~\cite{sam} masks from multi-view images"
- Codebooks: Discrete sets of learned prototype features used to improve the quality or stability of language features in 3D representations. "further enhance this pipeline by improving the quality of language features in Gaussian primitives through codebooks."
- Contrastive Learning: A training strategy that pulls semantically similar features together and pushes dissimilar ones apart to improve discrimination. "introducing contrastive learning between different objects in the scene"
- Deep Hough Voting: A technique where points vote for object centers in a learned space, inspiring centroid-based voxel grouping. "Drawing inspiration from deep hough voting~\cite{deephoughvote}"
- Describe Anything Model (DAM): A captioning model that produces detailed descriptions of masked regions across frames. "we leverage the Describe Anything Model (DAM) to first obtain a detailed caption."
- DINO: A self-supervised vision model used to produce visual features; cited as an alternate source of language-aligned embeddings. "visual-language aligned embeddings such as CLIP or DINO"
- Gaussian Primitives: 3D scene representation elements parameterized by Gaussian functions, storing features and enabling efficient rendering. "improving the quality of language features in Gaussian primitives through codebooks."
- Group Dictionary: A data structure storing each unique instance’s centroid and ID during voxel grouping. "We also use a Group Dictionary to record the spatial centroid of each unique instance."
- Group Field: A per-voxel feature storing votes toward instance centroids to realize coherent 3D grouping. "It is worth noting that, with our Group Field construction strategy, even if the voxels are assigned to an incorrect group in some view, the accumulated and still force the voxel to 'vote' the most confident group it belongs"
- Intersection-over-Union (IoU): A standard metric quantifying the overlap between predicted and ground-truth masks. "finding the highest IoU mask in for each instance in $M^{\mathrm{proj}$"
- Masked Average Reduction: Computing an instance’s centroid by averaging 3D points within its 2D mask. "determined by performing masked average reduction on the point map"
- Multi-modal LLMs (MLLMs): LLMs that can process both text and visual inputs for tasks like caption refinement and retrieval. "Multi-modal LLMs (MLLMs)"
- Neural Radiance Fields (NeRF): A continuous volumetric scene representation enabling high-quality novel view synthesis via volume rendering. "Neural radiance fields (NeRF)~\cite{mildenhall2021nerf}"
- Open-Vocabulary Segmentation (OVS): Segmentation that handles arbitrary, unseen textual categories without task-specific training. "open-vocabulary segmentation (OVS)"
- Referring Expression Segmentation (RES): Segmenting objects in 3D based on complex natural-language descriptions specifying attributes or relations. "referring expression segmentation (RES)"
- SAM2: A segmentation foundation model used to obtain per-frame masks and assist in mask merging. "segmentation maps obtained from SAM2~\cite{ravi2024sam2}"
- Scene Map: The global index of grouped instances, recording IDs, positions, and canonical captions for text-based retrieval. "construct a Scene Map recoding their position and captions."
- SE(3): The Lie group of 3D rigid transformations (rotations and translations) used to represent camera poses. "{\xi_i \in \mathrm{SE}(3)}"
- Sparse Voxel Rasterization (SVR): A discrete, sparse voxel representation enabling efficient rasterization-based novel view synthesis. "Sparse Voxel Rasterization (SVR)~\cite{svr}"
- Text-to-Text Retrieval: Matching user queries to stored captions using LLMs, without embedding alignment. "perform direct text-to-text retrieval using MLLMs"
- Top-k Sampling: Selecting the top-k contributors in feature updates; noted as unnecessary for low-dimensional group features. "we do not need the top-k sampling as our group feature is only 3-dimensional."
- Vision LLMs (VLMs): Models jointly trained on images and text, used to obtain or refine semantic descriptions. "leveraging powerful Vision LLMs (VLMs)"
- Volume Rendering Equation: The compositing formula accumulating color contributions along a ray using per-voxel opacities and weights. "Their rendering follows the classical volume rendering equation"
- Voxel Grouping: Clustering voxels into coherent object instances using centroid voting and mask lifting. "Training-Free Sparse Voxel Grouping"
Collections
Sign up for free to add this paper to one or more collections.

