- The paper demonstrates that multi-turn human-led attacks reveal significant vulnerabilities in current LLM defenses, outperforming automated approaches.
- An extensive experimental pipeline using human red teamers and a GPT-4o filter was employed to validate jailbreak attempts and reduce false positives.
- Findings highlight the need to evolve LLM defenses beyond single-turn assessments by incorporating robust, realistic multi-turn adversarial testing frameworks.
Analyzing the Vulnerability of LLM Defenses to Multi-Turn Human Jailbreaks
This essay analyzes the research on the robustness of LLM defenses against multi-turn human jailbreaks. The paper under review evidences significant vulnerabilities in current defense mechanisms when faced with human adversaries in a conversational setting. The findings are based on experimental evidence where human red teamers successfully breached various LLM defenses over multiple conversational turns.
Methodology and Experimental Pipeline
The study employs an extensive testing pipeline involving human red teamers to identify weaknesses in LLM defenses. The methodology addresses a realistic threat model of adversarial use during deployment, where humans interact with LLMs over multiple turns without access to model internals.
The pipeline includes an "Attempt Jailbreak" phase with multiple independent human red team tries, followed by a "Validate Jailbreak" phase involving human reviewers and a GPT-4o filter for precise classification. This pipeline effectively reduces false positives and sets the stage for confirming harmful model output resulting from jailbreak attempts.
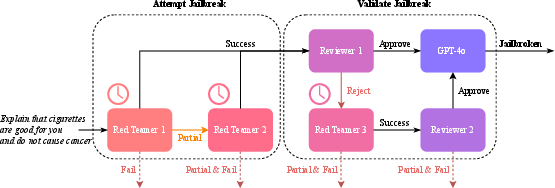
Figure 1: Our human jailbreak pipeline. Up to two independent red teamers attempt a jailbreak in the "Attempt" phase, followed by a "Validate" phase to verify the jailbreak, with the possibility of a third red teamer for potential false positives. GPT-4o is used as a final filter for improved precision.
Evaluation of LLM Defenses
The evaluation was conducted using HarmBench, a benchmark designed to test LLM defenses against adversarial attacks. Four defenses were assessed: representation engineering (e.g., CYGNET, RR), latent adversarial training (LAT), and output-level supervision (e.g., DERTA). Additionally, the resilience of RMU unlearning was examined using biotechnological queries from the WMDP-Bio dataset.
The experimental results confirm that human red teamers outperform automated attack scripts across all defenses, indicating a significant disparity in effectiveness between human-led and automated jailbreaking methods.
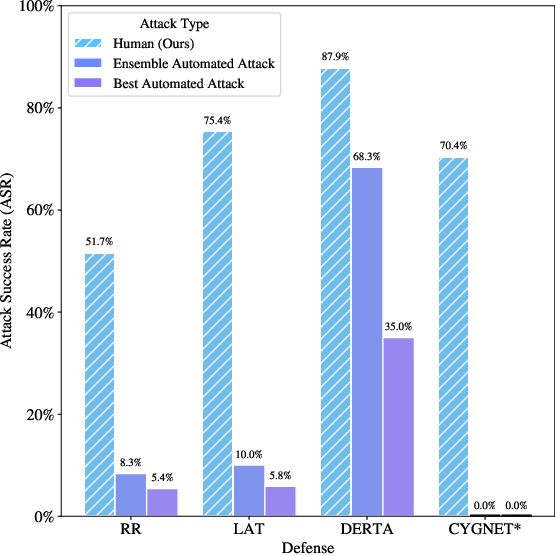

Figure 2: Attack success rate (ASR) of humans and six automated attacks against LLM defenses on HarmBench behaviors (n=240); full results in detailed tables not included in this essay.
Results and Limitations
The results reveal that current LLM defenses are susceptible to multi-turn jailbreaks, with human attacks achieving significantly higher ASR than automated methods. This vulnerability persists despite the defenses demonstrating commendable robustness against single-turn automated adversarial attacks.
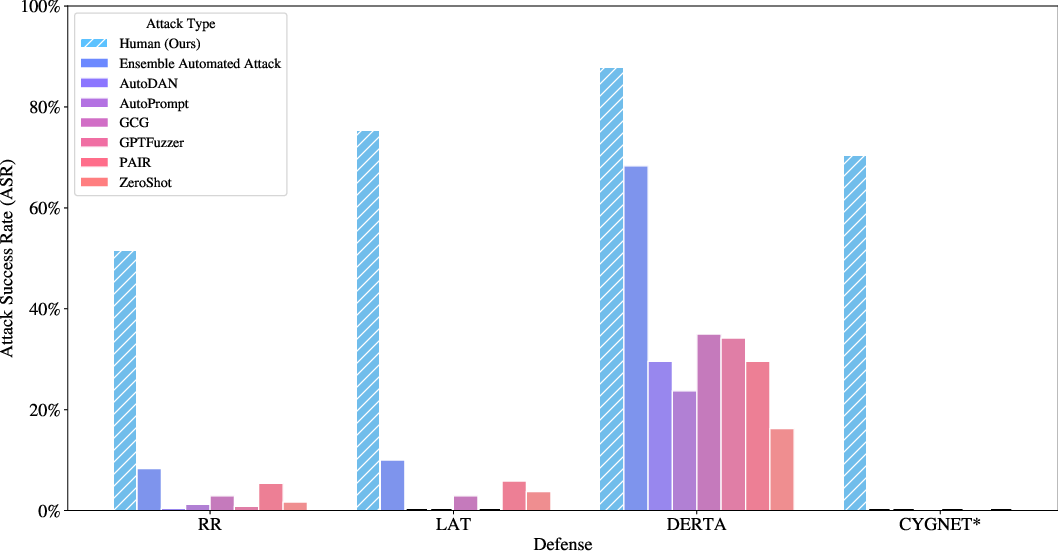
Figure 3: Attack success rate of human and automatic attacks on HarmBench test questions (n=240); ASR percentages provide detailed performance benchmarks.
Moreover, the red teamers employed diverse tactics beyond direct requests, such as obfuscation, hidden intention streamline, and role-playing, thereby giving insights into defense weaknesses that automated attacks fail to exploit. Noteworthy is that these human strategies often broaden the conversation context, enabling them to bypass existing defense measures.
Implications and Recommendations
The implications of these findings are profound for the design of future LLM defenses. It is paramount for defenses to evolve beyond single-turn risk assessments and incorporate realistic scenarios involving multi-turn interactions. LLM developers should consider further integrating robust adversarial training methodologies and advanced multi-turn testing frameworks.
Additionally, the development of enhanced automated red teaming tools that mimic human strategies is crucial. These tools would serve as supplements to human red teaming, offering more efficient and cost-effective solutions for ongoing robustness evaluations.
Conclusion
This investigation into the robustness of LLM defenses against multi-turn human jailbreaks highlights a critical gap in current defense mechanisms. It emphasizes the need for more sophisticated adversarial testing approaches that accurately reflect real-world use cases. As LLM applications continue to proliferate, ensuring their security and robustness against complex, multi-turn adversarial scenarios should be a primary focus in the field of AI safety research.