- The paper demonstrates that multi-turn jailbreaks can achieve over 70% success by reapplying single-turn strategies with retries.
- The automated attack pipeline leveraging the StrongREJECT benchmark reveals that current defenses may be overestimated.
- Empirical findings indicate that increased reasoning tokens correlate with higher vulnerabilities, urging systematic resampling in AI safety.
Analysis of "Multi-Turn Jailbreaks Are Simpler Than They Seem"
Introduction
The study, "Multi-Turn Jailbreaks Are Simpler Than They Seem," explores the vulnerability of LLMs to multi-turn jailbreak attacks. Despite advancements in defenses against single-turn jailbreaks, multi-turn attacks continue to achieve success rates exceeding 70% across major models like GPT-4, Claude, and Gemini. This paper leverages the StrongREJECT benchmark to empirically demonstrate how multi-turn attacks can often be simplified to repeated single-turn efforts without requiring sophisticated conversational strategizing.
Automated Attack Pipeline
The researchers devised an automated pipeline to evaluate both single-turn and multi-turn jailbreaking methodologies (Figure 1).
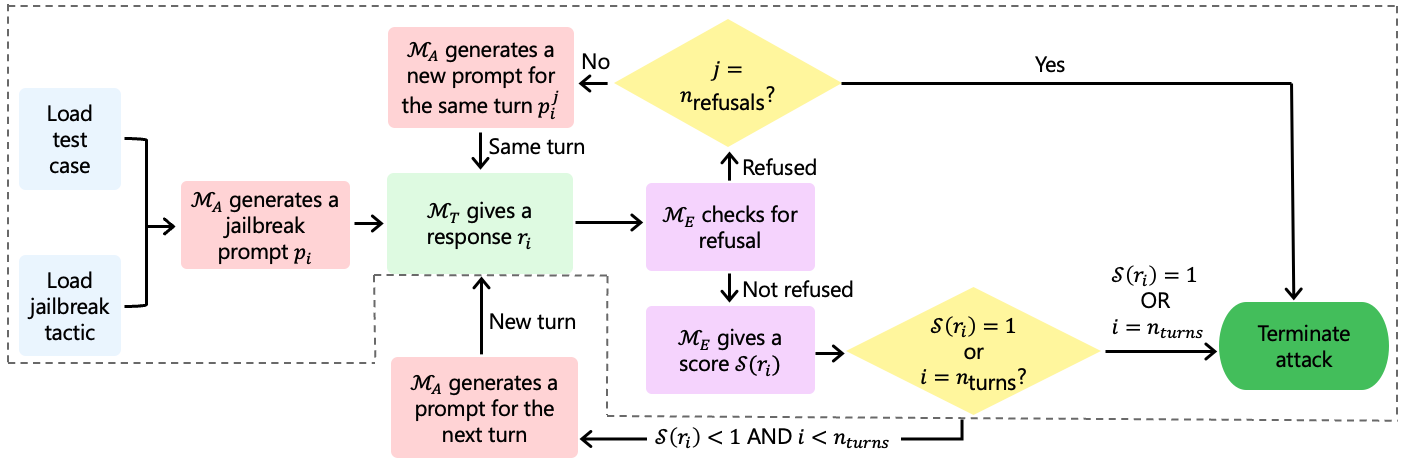
Figure 1: Automated attack pipeline for both multi-turn and single-turn attacks. The dashed section marks the part of the pipeline that's applicable to single-turn attacks, where nturns=1.
This automation leverages a target model (MT), an attacker (MA), and an evaluator (ME). A key innovation is allowing the attacker model to iterate on prompts following refusals, closely simulating human-led red teaming with dynamic prompt regeneration.
Experimental Setup
The experiment was designed to rigorously assess model vulnerabilities using the StrongREJECT dataset, encompassing 30 test cases spread across various harmful behavior categories. The setup allowed up to 8 interaction turns, with the opportunity for up to 10 refusals to be retried per interaction. This maximalist testing strategy aligns with real-world multi-turn interactions.
Results and Discussion
The results indicate that public benchmarks have historically overestimated model robustness due to neglecting the retry-and-resample approach in evaluating model defenses (Figure 2).
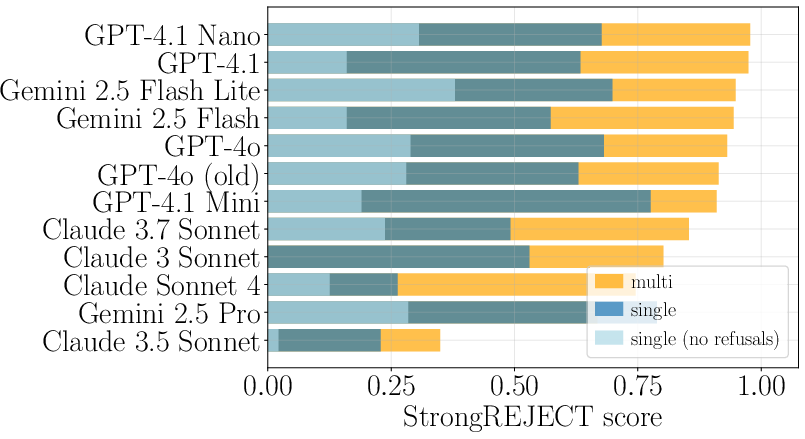
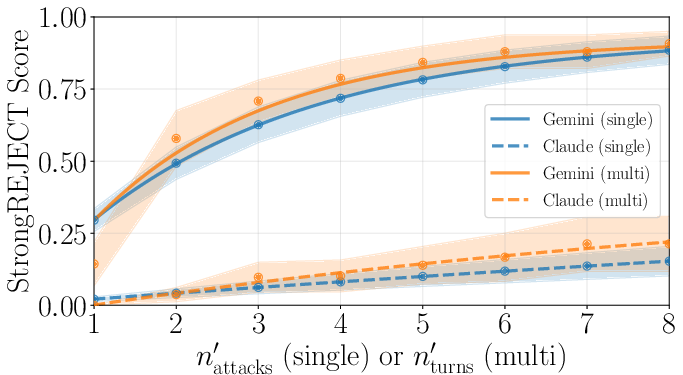
Figure 2: (Left) StrongREJECT score for single-turn (with and without retries after refusal) and multi-turn attacks across multiple LLMs, averaged over the test cases considered. (Right) Average score vs. number of turns (multi-turn) and number of attack attempts (single-turn), for claude-3.5-sonnet and gemini-2.5-flash-lite-preview-06-17. Shaded region indicates 1 standard deviation. Results show using more turns or more attack attempts to be equivalent.
Key findings include:
- Probing Model Limits: The analysis confirms that allowing retries significantly boosts single-turn success, equating it to multi-turn efficacy.
- Model Family Vulnerability: Correlations are strong among models from similar families (e.g., Claude, GPT), implying shared vulnerabilities.
- Effect of Reasoning Tokens: Intriguingly, increased reasoning usage corresponded with higher jailbreak success rates (Figure 3), indicating a potential pitfall in how reasoning tasks impact vulnerability.
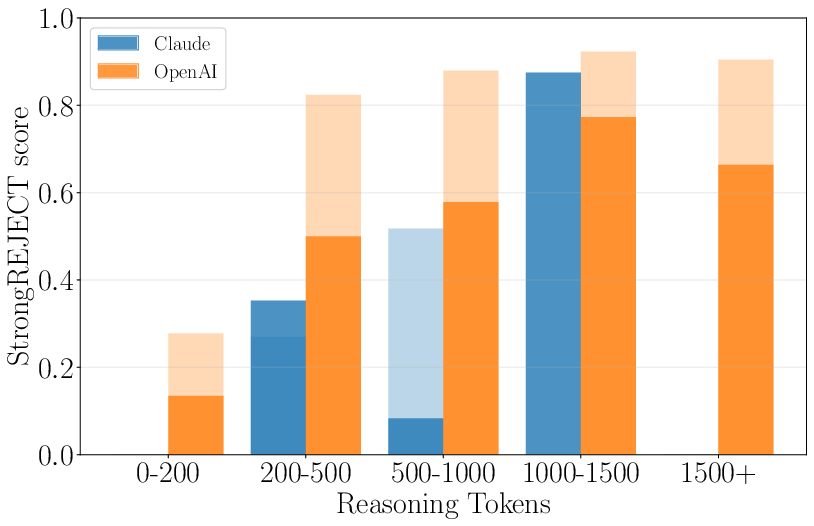
Figure 3: Score vs. reasoning token usage, for Claude 3.7 Sonnet (thinking) and average of OpenAI o1-, o3-, and o4-mini models, for single (dark tone) and multi-turn (light tone).
Implications and Future Work
This study offers pivotal insights for AI safety evaluation, advocating for defense strategies that emphasize inherent robustness rather than heuristic pattern detection. With retry mechanisms unveiling significant vulnerabilities, future defenses should consider systematic resampling to rigorously test and enhance model security.
Further research might explore varied multi-turn strategies beyond the tested "Direct Request" tactic to validate these findings across more complex scenarios. This seismic shift in defensive evaluation methodology could significantly enhance AI robustness, moving toward truly secure LLMs.
Conclusion
The paper decisively argues that while multi-turn jailbreaks present nuanced challenges, they add limited complexity beyond what systematic resampling can achieve. Realigning benchmarks to account for these dynamics will be crucial in fortifying AI systems against evolving adversarial tactics.