- The paper introduces NiNo, a framework that predicts future network parameters using graph-based neuron interactions to accelerate training.
- It leverages neural graphs to capture permutation symmetry in multi-head self-attention layers, enabling accurate and efficient parameter updates.
- Experimental results show a 48.9% speedup in training across diverse tasks, highlighting NiNo's capability to generalize to larger models.
Accelerating Training with Neuron Interaction and Nowcasting Networks
The paper "Accelerating Training with Neuron Interaction and Nowcasting Networks" (2409.04434) presents a novel approach to neural network optimization, focusing on enhancing the training process through periodic parameter prediction. The proposed method, Neuron Interaction and Nowcasting Networks (NiNo), builds upon the concept of weight nowcaster networks (WNNs) and introduces improvements that leverage graph neural networks and neural graphs.
Introduction to NiNo
NiNo introduces an innovative framework for accelerating the training of deep learning models by periodically predicting future parameters using graph-based representations. Unlike conventional optimizers like Adam, NiNo incorporates structural information of neural networks, specifically neuron connectivity, to make accurate predictions about parameter updates. This approach can effectively reduce the number of training steps needed to achieve target performance metrics, with reported improvements of up to 50% across various architecture types and tasks.
Neural Graph Construction
A critical component of NiNo is the construction of neural graphs that accurately represent the permutation symmetry of neurons in multi-head self-attention (MSA) layers, commonly found in Transformers.
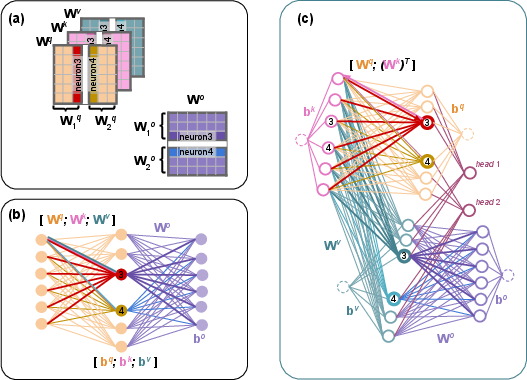
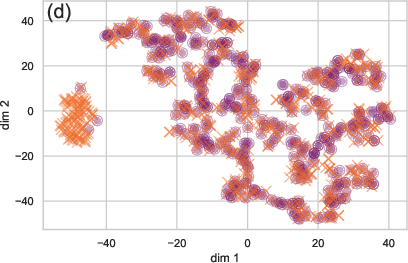
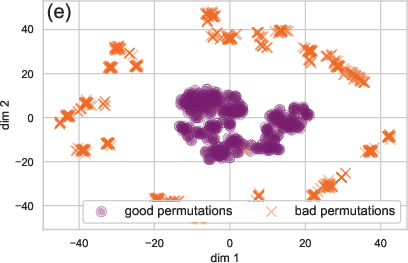
Figure 1: MSA weights with d=6 and H=2 heads; (b) its naive~\citep{kofinas2024graph}.
To address the permutation symmetry inherent to these layers, the paper proposes a refined neural graph that restricts permutations across heads while allowing relaxed permutations within weight matrices Wq,Wk. This construction uses separate node and edge features, encouraging more accurate modeling of neuron interactions and preserving the permutation symmetry across the heads in MSA.
Neuron Interaction and Nowcasting Network (NiNo) Architecture
The NiNo model processes neural graph inputs through layered scaling, embedding, and graph neural network (GNN) layers. By employing a direct multi-step forecasting strategy, NiNo predicts future parameter states and integrates these predictions periodically during training, maintaining computational efficiency.
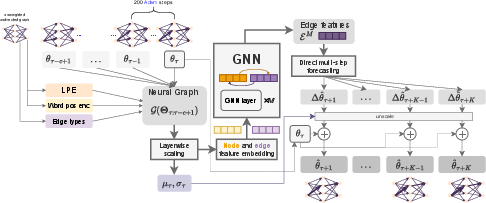
Figure 2: Our neuron interaction and nowcasting (NiNo) model.
NiNo's architecture benefits from the strong inductive bias imposed by neural graphs, improving generalization across diverse tasks and architectures. The unique utilization of graph neural networks within NiNo allows for effective parameter prediction, which is dynamically conditioned on the future horizon k.
Experimental Evaluation
Experiments conducted across nine tasks, including vision and language domains, demonstrate the superior performance of NiNo over existing methods like Linefit, WNN, and their variants.
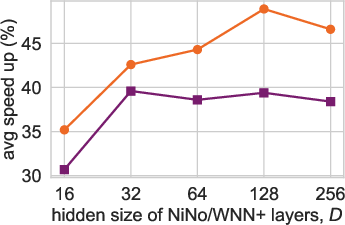
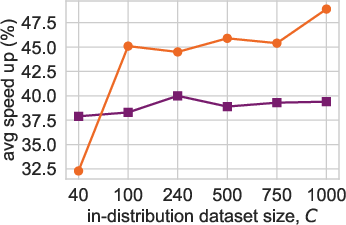
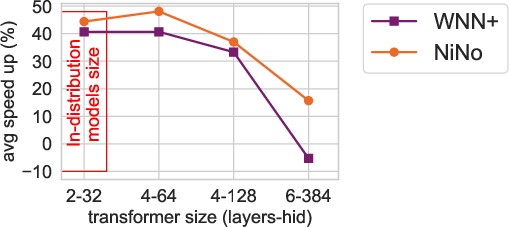
Figure 3: Scaling (a, b) and generalization (c) trends for NiNo vs WNN+.
NiNo achieves an average speedup of 48.9%, significantly outpacing methods such as WNN+. The paper also highlights NiNo's ability to generalize to larger models and different architectures, including challenging setups involving Llama3-style Transformers.
Detailed Analysis
The paper provides an insightful analysis of optimization trajectories in both parameter spaces and graph embedding spaces. By visualizing these trajectories, NiNo's robust ability to distinguish neural network states is demonstrated, which might be useful for subsequent model evaluations and downstream tasks.
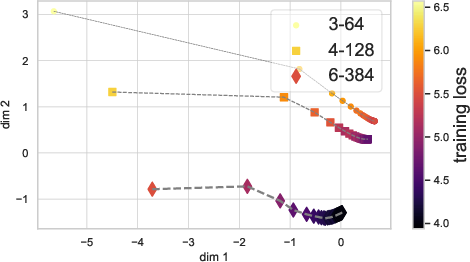
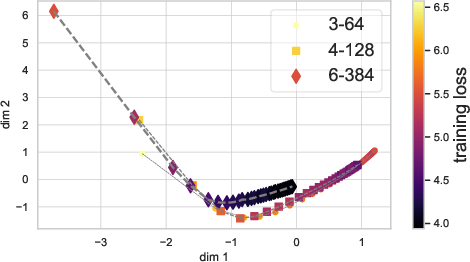
Figure 4: Comparing the embedding quality of WNN+ (a) and NiNo (b) during optimization.
NiNo's embeddings effectively capture the training dynamics, outperforming simpler baseline models like WNN+.
Conclusion
The research on NiNo offers promising advancements in the periodic acceleration of neural network training through sophisticated graph-based methods. Future explorations could aim to further scale NiNo's application to more extensive datasets and even larger models, potentially refining the induction process and enhancing computational efficiencies further. The paper contributes meaningfully to the exploration of periodic training acceleration, merging structure-aware predictions with optimization excellence.