- The paper introduces a neurosymbolic architecture that uses a DSL to disentangle visual priors for interpretable scene representation.
- It leverages CNN encoders, programmatic scene descriptions, and differentiable rendering to improve robustness and data efficiency.
- Empirical results show that the approach maintains performance under limited data and noisy conditions compared to pixel-based models.
Disentangling Visual Priors via a Neurosymbolic Compositional Autoencoder
Overview and Motivation
The paper presents a neurosymbolic architecture—Disentangling Visual Priors—that leverages a domain-specific language (DSL) for compositional image interpretation through unsupervised learning. The primary motivation is to overcome core limitations of conventional deep learning (DL) methods in computer vision, particularly their incapacity to generate symbolic, structured scene descriptions and their consequent generalization failures with limited or noisy data. Instead of relying purely on data-driven approaches, the proposed method introduces explicit visual priors over object shapes, appearances, and geometric transformations within a differentiable, executable program expressed in a DSL. This enables disentanglement of image formation factors, offers more interpretable and controllable scene representations, and demonstrates improved robustness and sample efficiency compared to typical pixel-based DL pipelines.
Architecture and Programmatic Scene Representation
The architecture consists of three main components: Perception, Program, and Renderer.
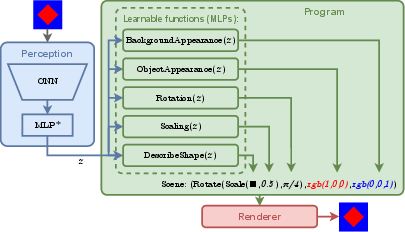
Figure 1: The pipeline encodes an image with the Perception module (CNN→z), maps z to a symbolic scene description via the Program (expressed in DSL), and renders the scene back to the image domain.
- Perception: Utilizes a CNN backbone (ConvNeXt-B or a smaller custom CNN) to encode input images into a latent feature vector z.
- Program: Implemented in a custom DSL, the program maps z to explicit, symbolic scene components (object shape, color, background, and applied transforms). These elements are parameterized either directly from z (e.g., via elliptic Fourier descriptors for shape recovery) or inferred from a set of learnable shape prototypes (embedding-based selection with differentiable indexing).
- Renderer: Employs PyTorch3D’s differentiable rendering engine to translate the symbolic scene back to a raster image, facilitating end-to-end gradient-based optimization.
The DSL is structurally designed to represent compositional generative graphics pipelines, explicitly disentangling appearance, spatial transforms, and object categorization, and allowing the imposition of strong visual priors within the learning process.
Experimental Setup and Evaluation
Experiments are conducted on a synthetic benchmark dataset of 2D scenes, each containing a single object from three shape categories (ellipse, square, heart), presented in random poses, scales, and colors, on colored backgrounds. The key evaluation metrics are MSE, SSIM, IoU, and ARI, which cover both pixel-wise and segmentation-oriented aspects of reconstruction.
Baselines and Model Variants
- The principal baseline is MONet ("MONet: Unsupervised Scene Decomposition and Representation" (Burgess et al., 2019)), with both pre-trained and from-scratch CNN backbones, representing the state-of-the-art for unsupervised scene decomposition without explicit geometry priors.
- DVP models are evaluated in two major program regimes:
- Direct mode (-D): Object shape is predicted directly from z using an MLP producing Fourier descriptors.
- Prototype mode (-P): Object shape is selected as a mixture over a learnable embedding of shape prototypes, conditioned on z.
Both modes are examined with large (ConvNeXt-B) and small (CNN1) Perception modules, including both frozen and jointly-trained configurations.
Key Empirical Insights
DVP models perform comparably to the baseline MONet in standard reconstruction metrics when trained on the full dataset, with marginally lower MSE but similar or superior performance in SSIM and IoU, especially with a pre-trained backbone. The compositional, DSL-imposed structure ensures that DVP reconstructions preserve explicit geometric integrity, with robust figure-ground separation and shape consistency, even when minor infractions in color reproduction occur.



Figure 2: Reconstructions produced by models trained on the full training set, demonstrating faithful scene recovery for both DVP and baseline models.
A crucial performance distinction emerges when data is limited. When training data is reduced to 5% or 1% of the original set, MONet suffers catastrophic metric drops (notably in MSE and IoU), while DVP exhibits only moderate degradation. This underscores a strong empirical claim: compositional, prior-informed neurosymbolic models can attain high sample efficiency and resilience to data scarcity, mitigating the classic DL reliance on large-scale datasets.
Prototype Learning and Interpretability



Figure 4: Visualization of learned prototypes (rows: 100\%, 5\%, 1\% training data). Color denotes each prototype’s overall impact on scene reconstructions.
In the -P variant, DVP autonomously discovers and employs interpretable prototypes corresponding to object categories. Even when trained with minimal supervision, the model typically dedicates unique, stable embedding slots for each geometric type; hearts, for example, sometimes bifurcate into two prototypes to account for orientation symmetries. The disentangled mixture and use of prototypes not only provide a mechanism for explicit shape transfer and manipulation but also offer an interpretable axis for category-level reasoning, leading to near-perfect classification performance in downstream shape categorization tasks.
Robustness to Noise and Out-of-Distribution Generalization
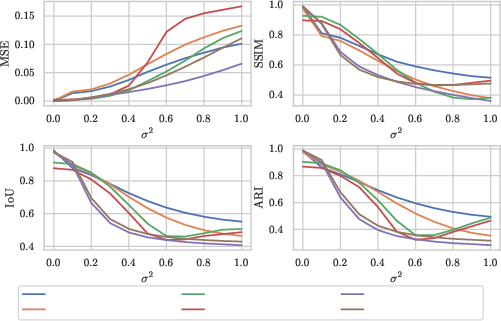
Figure 5: Sensitivity of model performance metrics to varying magnitudes of Gaussian noise injected at test-time.
DVP exhibits robust reconstruction accuracy when exposed to image noise, maintaining compositional inference and segmenting object and background even under significant perturbations. MONet’s performance degrades more rapidly due to its direct reliance on pixel-wise representations.
For out-of-sample shape generalization, DVP’s compositional inductive bias confers adaptability—while the models underperform MONet in raw pixel metrics, they still produce plausible scene parses (faithful segmentation and compositional assignment), even for entirely novel, untrained shape categories.

Figure 3: Reconstructions for out-of-distribution shapes; input scenes (top), DVP (-D{) outputs (middle), and DVP (-Dsmall) outputs (bottom).
Theoretical and Practical Implications
The integration of a DSL for scene composition enables explicit factorization of image formation processes, facilitating disentanglement not through emergent representations, but by construction. This “explanation by design” approach contrasts with fully neural disentanglement models (e.g., VAEs (Kingma et al., 2013)), where interpretability and modularity are only weakly encouraged via loss regularization.
Advantages of the Neurosymbolic Approach
- Transparency: Each scene element—shape, pose, appearance—is represented by an interpretable, semantically meaningful program variable, allowing for both global and local explainability of inference steps.
- Sample Efficiency: The imposition of strong geometric priors restricts the learning hypothesis space, enabling effective learning in low-data regimes.
- Generalization and Robustness: By decomposing scenes into modular, compositional primitives and explicitly modeling geometric transforms, the architecture is more robust to noise, outlier categories, and distributional shift.
- Extensibility: The DSL is amenable to expansion—addition of more object categories, more complex 3D primitives, and richer appearance models (e.g., through extended EFDs or neural textures) can be incorporated via program synthesis.
However, there are practical constraints. Differentiable rendering introduces computational bottlenecks—PyTorch3D rasterization is CPU-bound for 2D meshes, limiting training throughput relative to pure neural models. Moreover, the approach is reliant on a carefully engineered DSL; missing or misaligned priors in the DSL could limit model expressiveness for more complex or naturalistic tasks.
Future Directions
The modular architecture suggests numerous avenues for future research:
- Program Synthesis: Instead of relying on pre-specified DSL templates, a higher-level generative process could be introduced to synthesize candidate programs for novel scenes, extending the model’s interpretive flexibility and enabling multiple hypotheses for ambiguous inputs.
- 3D Extension: The DSL could be extended to structured 3D representations, handling occlusion, multiple interacting objects, alternative rendering modalities, and attributes such as texture and lighting.
- Multi-Object Parsing: While the current work focuses on single-object scenes, the framework is naturally extensible to multi-object, hierarchical, and relational settings, contingent on the scalability of inference and rendering.
Conclusion
This work provides direct empirical and methodological support for the utility of neurosymbolic, compositional pipelines in unsupervised scene interpretation. By embedding scene priors via a DSL and exploiting differentiable rendering in end-to-end training, the architecture achieves interpretable, robust, and data-efficient visual reasoning. The results highlight promising directions for incorporating explicit structure and domain knowledge into neural scene understanding, with implications for robust perception in low-data and out-of-distribution regimes, and for the systematic development of explainable AI frameworks.