SOAP: Improving and Stabilizing Shampoo using Adam
Abstract: There is growing evidence of the effectiveness of Shampoo, a higher-order preconditioning method, over Adam in deep learning optimization tasks. However, Shampoo's drawbacks include additional hyperparameters and computational overhead when compared to Adam, which only updates running averages of first- and second-moment quantities. This work establishes a formal connection between Shampoo (implemented with the 1/2 power) and Adafactor -- a memory-efficient approximation of Adam -- showing that Shampoo is equivalent to running Adafactor in the eigenbasis of Shampoo's preconditioner. This insight leads to the design of a simpler and computationally efficient algorithm: $\textbf{S}$hampo$\textbf{O}$ with $\textbf{A}$dam in the $\textbf{P}$reconditioner's eigenbasis (SOAP). With regards to improving Shampoo's computational efficiency, the most straightforward approach would be to simply compute Shampoo's eigendecomposition less frequently. Unfortunately, as our empirical results show, this leads to performance degradation that worsens with this frequency. SOAP mitigates this degradation by continually updating the running average of the second moment, just as Adam does, but in the current (slowly changing) coordinate basis. Furthermore, since SOAP is equivalent to running Adam in a rotated space, it introduces only one additional hyperparameter (the preconditioning frequency) compared to Adam. We empirically evaluate SOAP on LLM pre-training with 360m and 660m sized models. In the large batch regime, SOAP reduces the number of iterations by over 40% and wall clock time by over 35% compared to AdamW, with approximately 20% improvements in both metrics compared to Shampoo. An implementation of SOAP is available at https://github.com/nikhilvyas/SOAP.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
Training a big AI model is like trying to walk downhill to the lowest point on a huge, bumpy landscape. Optimizers are the “walking rules” that decide how big a step to take and in which direction, based on the slope under your feet.
This paper introduces an optimizer called SOAP. It combines two popular ideas:
- Adam (a fast, simple optimizer)
- Shampoo (a smarter optimizer that understands the landscape’s shape but is more expensive to run)
SOAP runs Adam in a smart, rotated coordinate system chosen by Shampoo. Think of it like turning your map so that “downhill” lines up neatly with the axes, making your steps more efficient.
Key Questions the Paper Answers
- Can we connect Shampoo to a simpler method so we keep its benefits but make it cheaper and easier to use?
- Can we build a practical optimizer (SOAP) that uses Adam in Shampoo’s “best directions” to speed up training?
- Does SOAP train LLMs faster than AdamW and Shampoo?
- Is SOAP simpler to tune and more stable when we do the expensive calculations less often?
Methods and Approach (explained simply)
- The authors first show a neat math connection: Shampoo with a specific setting (using the “1/2 power”) is equivalent to running Adafactor (a memory-saving version of Adam) in Shampoo’s special coordinate system, called its “eigenbasis.”
- Eigenbasis: Imagine rotating your map so the steepest and flattest directions line up with the x- and y-axes. That makes it easier to choose step sizes in each direction.
- Preconditioner: A tool that adjusts step sizes depending on direction—smaller steps on steep slopes, bigger steps on gentle slopes.
- Based on this insight, they design SOAP:
- Compute the “smart directions” (eigenvectors) from Shampoo every so often, not every step, to save time.
- At every step, run Adam in this rotated space where directions are lined up nicely.
- Keep updating “running averages” (Adam’s memory of past gradients) so the optimizer stays adaptive and stable even if the directions change slowly.
- Rotate the updates back to the original space and apply them to the model weights.
- Experiments:
- Train LLMs (about 360 million and 660 million parameters) on standard data, with large batches of tokens.
- Compare SOAP to AdamW and Shampoo.
- Measure:
- Training speed (how many steps needed and total time)
- Stability when the expensive “direction finding” step is done less often (this is the preconditioning frequency).
- Use careful tuning and a standard learning rate schedule to make fair comparisons.
Main Findings and Why They Matter
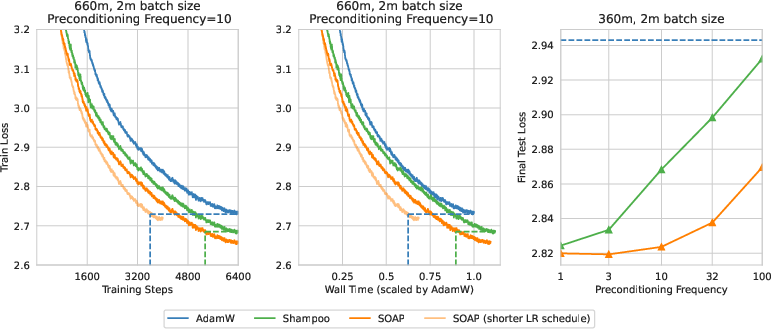
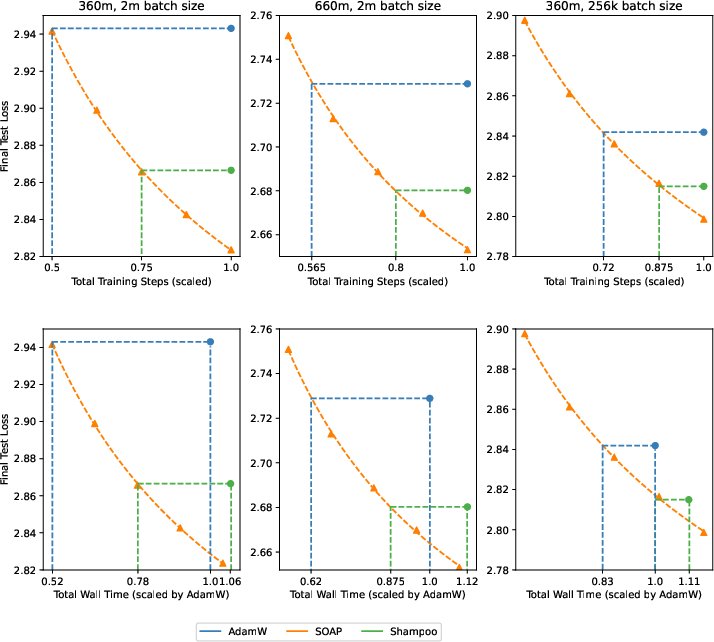
Here are the main results from large-batch training (around 2 million tokens per step):
- SOAP is faster than AdamW and Shampoo:
- About 40% fewer training steps than AdamW.
- About 35% less wall-clock time than AdamW.
- About 20% fewer steps and time than Shampoo.
- SOAP stays strong even if you update the “smart directions” less often:
- When the preconditioning frequency is lower (you compute eigenvectors rarely), Shampoo’s performance drops more noticeably.
- SOAP’s performance drops much more slowly, so it’s more robust.
- SOAP is simpler to use:
- Compared to AdamW, SOAP adds just one extra knob: how often to update the smart directions (the preconditioning frequency).
- Compared to Shampoo, SOAP has fewer hyperparameters to tune.
- Smaller batch sizes:
- With smaller batches (256k tokens), the speedup is smaller but still positive: roughly 25% fewer steps than AdamW and about 10–12% fewer than Shampoo, with around 15% wall-clock improvement over AdamW.
- Practical engineering choices:
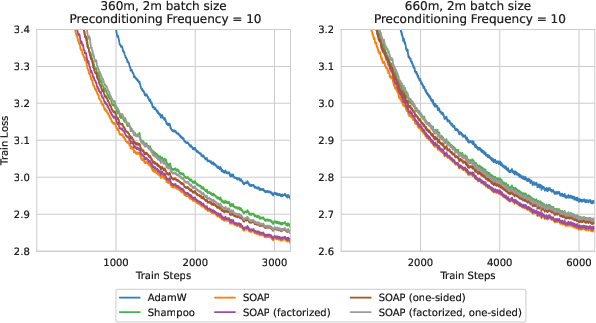
- They use a faster way to estimate eigenvectors (one-step power iteration plus QR decomposition) rather than a slower, exact method.
- They explore variations that trade a tiny bit of performance for lower memory and compute, like using Adafactor inside SOAP or rotating only one side of a layer.
These results matter because training LLMs is very expensive. If you can cut training time by 20–40%, you save lots of money and can iterate faster on research.
Implications and Potential Impact
- Faster, cheaper training: SOAP can reduce the time and compute needed to train big models, which helps both research labs and companies.
- Simpler and more stable: Because SOAP is robust when you don’t update the “smart directions” very often, it’s easier to deploy at scale.
- A useful design idea: Running a simple optimizer (like Adam) in a smarter coordinate system (from Shampoo) is a powerful combination. This approach could be applied to other optimizers and tasks.
- Future improvements: The paper suggests speeding SOAP up even more by using lower precision for certain calculations and better distributed implementations. It could also be tested in areas beyond language, like vision models.
In short, SOAP blends the best of both worlds—Adam’s simplicity and Shampoo’s smarts—to train large models faster with fewer tuning headaches.
Collections
Sign up for free to add this paper to one or more collections.