- The paper demonstrates that eigenvalue corrections can replace learning rate grafting, leading to improved optimization performance.
- It introduces an adaptive strategy using a warm-started QR algorithm to dynamically adjust eigenbasis updates based on training stages.
- Empirical results on Imagewoof show that Shampoo variants without grafting can match or surpass traditional performance while enhancing computational efficiency.
Investigating Shampoo's Heuristics by Decomposing its Preconditioner
Introduction
The paper "Purifying Shampoo: Investigating Shampoo's Heuristics by Decomposing its Preconditioner" (2506.03595) examines the success and complexities surrounding the Shampoo algorithm, a Kronecker-factorization-based optimization method for neural networks. Shampoo's victory in the AlgoPerf contest has rekindled interest in such structured preconditioned gradient techniques over standard methods like Adam. However, its reliance on heuristics like learning rate grafting and outdated preconditioners raises questions about their necessity and optimization.
Decomposition and Heuristics
Shampoo's performance relies heavily on learning rate grafting, a technique to adapt update magnitudes across layers, enhancing stability given the variance in layer-wise eigenspectra and computation infrequency. The paper seeks to decouple and scrutinize the preconditioner's eigenvalues and basis updates, challenging the need for grafting by proposing frequency correction for eigenvalues to offset staleness and scaling issues.
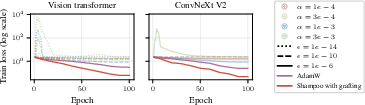
Figure 1: Shampoo with stale preconditioner without grafting shows performance issues with various hyperparameters on Imagewoof, compared to AdamW with grafting.
Experimental Insights and Adaptivity
Empirical investigations demonstrate that optimally correcting eigenvalues can alleviate the need for grafting, as evidenced by experiments comparing Shampoo variants. These alternatives not only match but sometimes surpass the Shampoo performance with grafting, indicating potential simplification of the algorithm's hyperparameters and its broader applicability without grafting under certain conditions.
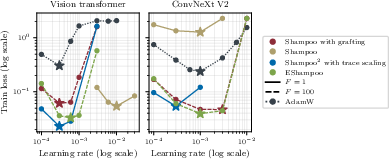
Figure 2: Training results comparing different Shampoo variants on Imagewoof, highlighting superiority in training loss and learning rate transfer across models.
Eigenbasis Update Strategy
The paper proposes a novel adaptive strategy for controlling eigenbasis approximation errors, leveraging a warm-started QR algorithm with a relative error criterion to dynamically adjust computation frequency based on training stages. This approach tailors preconditioner update frequencies to parameter identities, considerably impacting computational efficiency and convergence, particularly evident in contrast with fixed-frequency approaches as shown in the benchmarks.
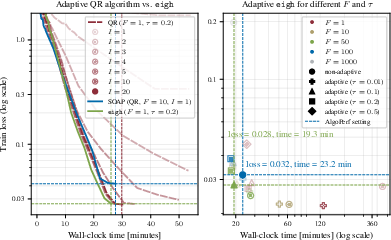
Figure 3: Adaptive eigendecomposition in EShampoo improves wall-clock efficiency on training tasks compared to static methods.
Conclusions and Future Directions
The study conducts a comprehensive evaluation of Shampoo’s heuristics, providing a principled pathway to enhance Shampoo’s algorithmic framework by eliminating grafting and optimizing update strategies. This fosters broader implications for structured gradient methods and scalability across diverse model architectures. Moving forward, it raises prospects for exploring adaptivity in other optimization strategies like K-FAC and further theoretical validations to integrate approximation quality into regret bounds.
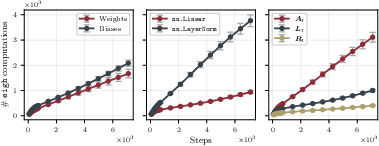
Figure 4: Analysis indicating variable update frequencies of different preconditioner matrices within a model, highlighting distinct computational dynamics.
Overall, this endeavor not only demystifies heuristics of Kronecker-factored optimizers but sets a cornerstone for future research aimed at refining large-scale learning algorithms, particularly in enhancing the balance between convergence quality and computational cost.